大数の法則は典型的には概収束あるいは確率収束を主張し,中心極限定理は法則収束を主張する。したがって,これらの収束概念の違いと関係を最初に整理しておくことが重要である。
確率論の基礎概念その2:収束
確率変数列の収束
同一の確率空間 \((\Omega,\mathcal F,P)\) 上に,実数値確率変数列 \((X_n)_{n\geq 1}\) と実数値確率変数 \(X\) が与えられているとする。
4つの収束概念
定義(概収束,almost sure convergence) \(X_n\) が \(X\) に概収束 するとは,\(P\) -a.s. に対して
\[
X_n(\omega)\to X(\omega)
\qquad (n\to\infty)
\]
が成り立つことをいう。すなわち,
\[
P\bigl(\{\omega\in\Omega:\lim_{n\to\infty}X_n(\omega)=X(\omega)\}\bigr)=1
\]
であるとき,\(X_n\to X\) a.s. と書く。
定義(確率収束,convergence in probability) \(X_n\) が \(X\) に確率収束 するとは,任意の \(\varepsilon>0\) に対して
\[
\lim_{n\to\infty}P(|X_n-X|>\varepsilon)=0
\]
が成り立つことをいう。このとき
\[
X_n\xrightarrow{P} X
\]
と書く。
定義(\(p\) 次平均収束,convergence in \(L^p\) ) \(p\geq 1\) とする。\(X_n\) が \(X\) に\(p\) 次平均収束
\[
\lim_{n\to\infty}E[|X_n-X|^p]=0
\]
が成り立つことをいう。このとき
\[
X_n\xrightarrow{L^p} X
\]
と書く。
定義(法則収束,convergence in law / distribution) \(C_b(\mathbb R)\) を \(\mathbb R\) 上の実数値有界連続関数全体とする。\(X_n\) が \(X\) に法則収束 するとは,任意の \(f\in C_b(\mathbb R)\) に対して
\[
\lim_{n\to\infty}E[f(X_n)]=E[f(X)]
\]
が成り立つことをいう。このとき
\[
X_n\xrightarrow{d}X
\]
あるいは
\[
X_n\Rightarrow X
\]
と書く。
注意
概収束,確率収束,\(p\) 次平均収束は,\(X_n\) と \(X\) が同じ確率空間上に定義されているときに意味を持つ概念である。一方,法則収束は各確率変数の分布だけ によって決まる概念なので,\(X_n\) と \(X\) が同じ確率空間上にある必要はない。
また,概収束,確率収束,\(p\) 次平均収束はそれぞれ強さの異なる収束であり,一般には同値ではない。以下,その関係を順番に調べる。
その前に、実際に幾つかの例でそれぞれの収束概念が違うものっぽいことを確認する。
例
収束概念の定義だけを見ると,それぞれがどの程度違う条件なのかは少しわかりにくい。 そこでまず,典型的な例を通じて,各収束概念がどういう振る舞いを表しているのかを確認する。
例1:定数列 \(X_n=1/n\)
最も簡単な例として,確率空間上で
\[
X_n(\omega)=\frac{1}{n},\qquad X(\omega)=0
\]
と定める。これは実際には確率変数というより単なる定数列であるが,もちろん確率変数の特別な場合である。
このとき任意の \(\omega\in\Omega\) について
\[
X_n(\omega)\to 0
\]
であるから,
\[
X_n\to 0 \quad \text{a.s.}
\]
が成り立つ。したがって概収束から確率収束も従う。
さらに任意の \(p\ge 1\) に対して
\[
E[|X_n-0|^p] = \left(\frac1n\right)^p
\to 0
\]
なので,
\[
X_n\xrightarrow{L^p}0
\]
も成り立つ。
また,分布も一点 \(\frac1n\) に集中しているので,当然
\[
X_n\xrightarrow{d}0
\]
も成り立つ。
したがってこの例では,4つの収束概念がすべて同時に成り立つ。
例2:\(X_n\sim N(0,1/n)\)
次に,各 \(X_n\) が平均 \(0\) ,分散 \(1/n\) の正規分布に従うとする。 すなわち
\[
X_n\sim N\left(0,\frac1n\right).
\]
直感的には,\(n\) が大きくなるほど分布が 0 の近くに強く集中するので,\(X_n\) は 0 に近づくはずである。
実際,任意の \(\varepsilon>0\) に対して
\[
P(|X_n|>\varepsilon)\to 0
\]
であるから,
\[
X_n\xrightarrow{P}0
\]
が成り立つ。
さらに正規分布のモーメント公式より,任意の \(p\ge1\) に対して
\[
E[|X_n|^p] = C_p n^{-p/2}
\to 0
\]
となるので,
\[
X_n\xrightarrow{L^p}0
\]
も成り立つ。
もし \(X_n\) を互いに独立な確率変数として同じ確率空間上に実現すると,概収束も実は成り立つ。 例えば \(\varepsilon>0\) を固定すると,
\[
\sum_{n=1}^\infty P(|X_n|>\varepsilon)
<
\infty
\]
が成り立つので,Borel–Cantelli の補題(これは次のlectureで扱うのでその時また戻ってくる)から
\[
P(|X_n|>\varepsilon \text{ infinitely often})=0
\]
である。\(\varepsilon=1/m\) \((m=1,2,\dots)\) として可算個を同時に考えれば,
\[
X_n\to 0 \quad \text{a.s.}
\]
も従う。
したがってこの例でも,適切に同じ確率空間上に構成すれば,4つの収束概念がすべて成り立つ。
図示と simulation
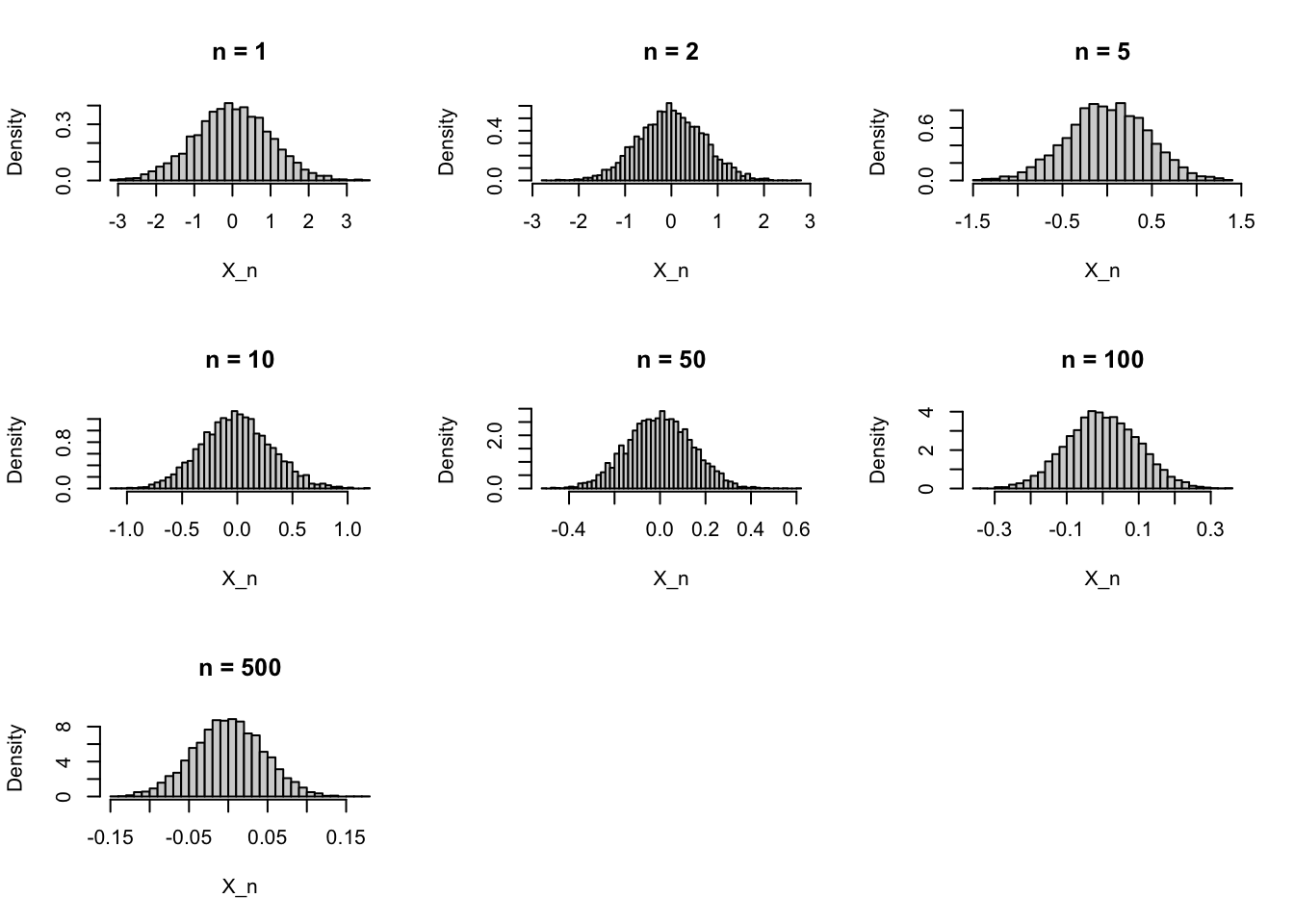
\(n\) が大きくなるにつれて,\(N(0,1/n)\) の分布が 0 の近くに鋭く集中していく様子を描いてみる。
set.seed (123 )<- c (1 , 2 , 5 , 10 , 50 , 100 , 500 )<- 5000 <- par (no.readonly = TRUE )par (mfrow = c (3 , 3 ))for (n in n_vec) {<- rnorm (B, mean = 0 , sd = 1 / sqrt (n))hist (x, breaks = 40 ,main = paste0 ("n = " , n),xlab = "X_n" ,probability = TRUE )par (oldpar)
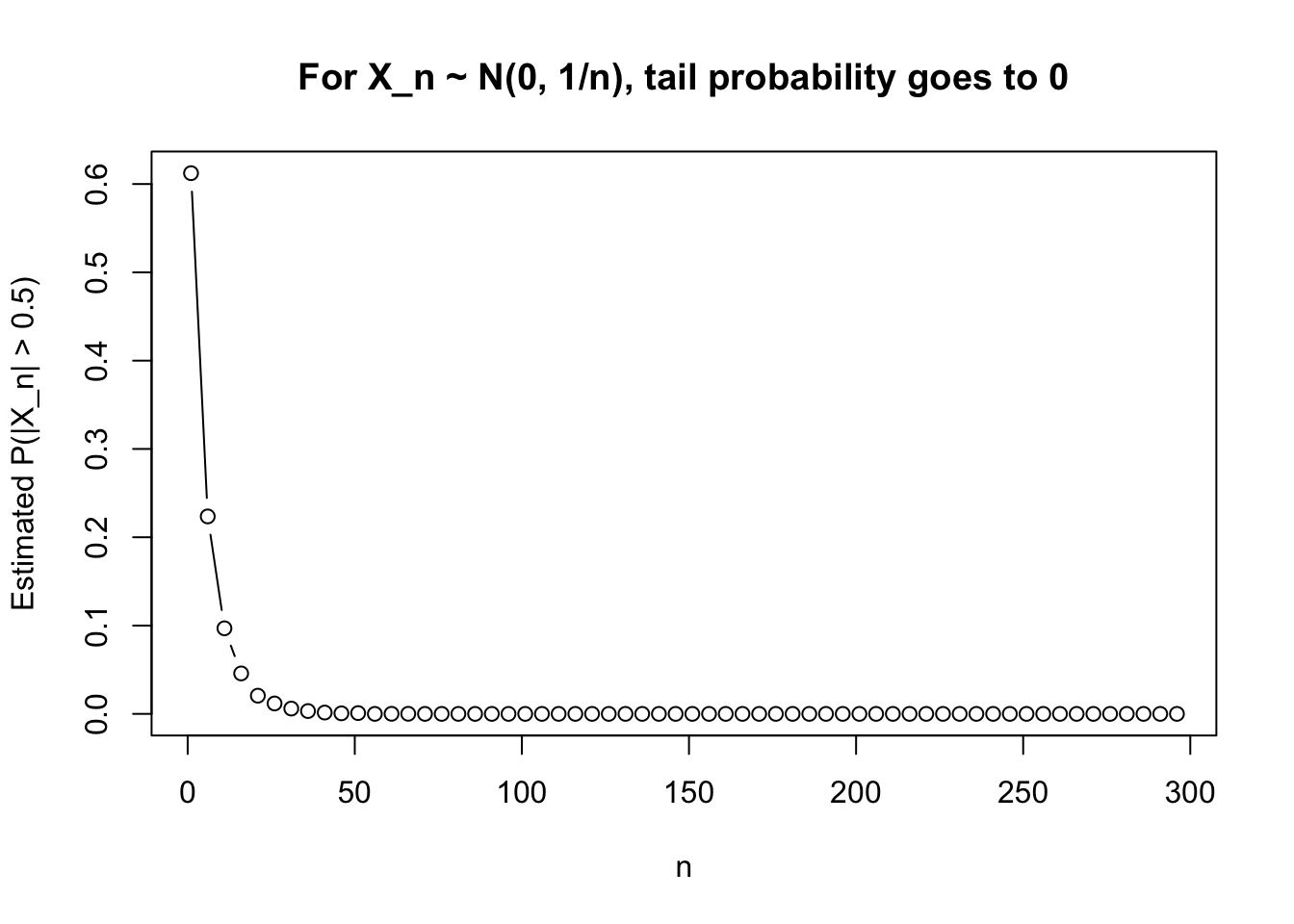
さらに
\[
P(|X_n|>\varepsilon)
\]
を実際に推定してみると,0 に近づくことが確認できる。
set.seed (123 )<- seq (1 , 300 , by = 5 )<- 10000 <- 0.5 <- sapply (n_grid, function (n) {<- rnorm (B, mean = 0 , sd = 1 / sqrt (n))mean (abs (x) > eps)plot (n_grid, prob_est, type = "b" ,xlab = "n" ,ylab = paste0 ("Estimated P(|X_n| > " , eps, ")" ),main = "For X_n ~ N(0, 1/n), tail probability goes to 0" )
例3:確率収束するが,概収束しない例
収束概念の違いが初めて見える典型例として,いわゆる を考える。
確率空間を \(([0,1],\mathcal B([0,1]),\lambda)\) とする。ここで \(\lambda\) はルベーグ測度である。 各 \(n\) に対して区間の指示関数 \(X_n\) を次のように定める。
まず \(n\) を一意的に
\[
n = 2^m + k
\qquad
(m\ge 0,\; 0\le k\le 2^m-1)
\]
と書き,そのとき
\[
X_n(\omega) = \mathbf 1_{\left[k/2^m,\,(k+1)/2^m\right)}(\omega)
\]
とする。
つまり,長さ \(2^{-m}\) の区間を左から順に走査するように 1 と 0 が現れる列になっている。
小さい \(n\) で具体的に書くと,次のようになる。
\[
\begin{aligned}
X_1(\omega) &= \mathbf 1_{[0,1)}(\omega),\\
X_2(\omega) &= \mathbf 1_{[0,1/2)}(\omega),&
X_3(\omega) &= \mathbf 1_{[1/2,1)}(\omega),\\
X_4(\omega) &= \mathbf 1_{[0,1/4)}(\omega),&
X_5(\omega) &= \mathbf 1_{[1/4,1/2)}(\omega),\\
X_6(\omega) &= \mathbf 1_{[1/2,3/4)}(\omega),&
X_7(\omega) &= \mathbf 1_{[3/4,1)}(\omega),\\
X_8(\omega) &= \mathbf 1_{[0,1/8)}(\omega),&
X_9(\omega) &= \mathbf 1_{[1/8,1/4)}(\omega).
\end{aligned}
\]
つまり第 \(m\) ブロックでは,幅 \(2^{-m}\) の窓が \([0,1)\) の上を左から右に動く。ブロックが進むと窓は細くなるが,固定した \(\omega\) から見ると各ブロックで一度はその窓が自分の上を通る。
このとき各 \(n\) について
\[
P(X_n=1)=2^{-m}
\]
なので,\(n\to\infty\) なら \(m\to\infty\) でもあることから
\[
P(|X_n-0|>\varepsilon)=P(X_n=1)\to 0
\qquad (0<\varepsilon\le 1)
\]
となる。したがって
\[
X_n\xrightarrow{P}0
\]
である。
しかし各 \(\omega\in[0,1)\) を固定すると,\(X_n(\omega)\) は 1 にも 0 にも無限回なる。
実際,各段階 \(m\) で長さ \(2^{-m}\) の分割を考えると,\(\omega\) はちょうど1つの小区間に属するので,その段階では一度だけ \(X_n(\omega)=1\) になる。一方,それ以外の多くの \(n\) では 0 である。よって
\[
X_n(\omega)
\]
は極限を持たない。したがって
\[
X_n \not\to 0 \quad \text{a.s.}
\]
である。
この例は
\[
X_n\xrightarrow{P}0
\quad\text{だが}\quad
X_n\not\to 0 \text{ a.s.}
\]
となる代表例である。
図示と simulation
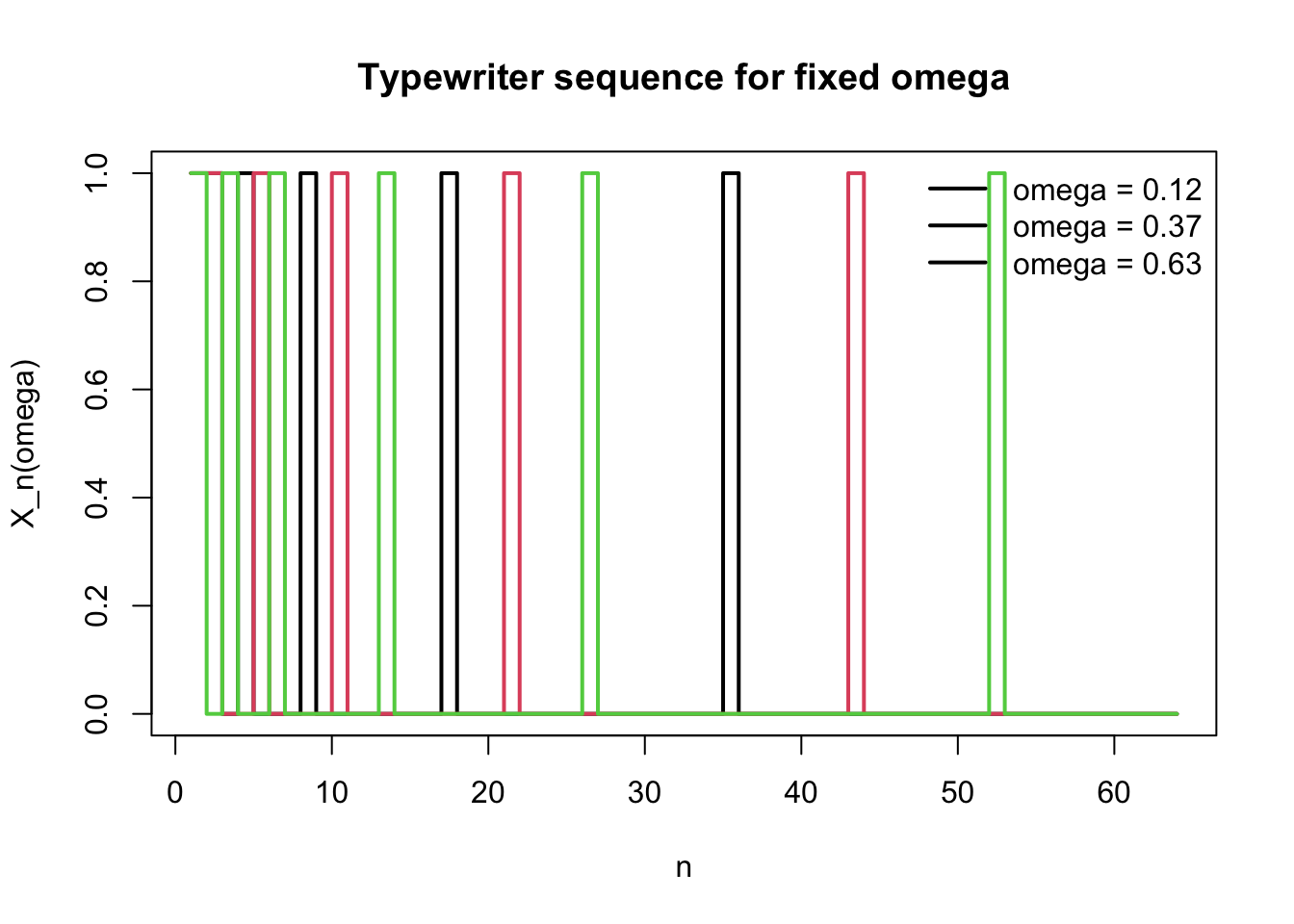
まず,最初のいくつかの \(X_n\) を関数として描く。
<- function (n) {<- floor (log2 (n))<- n - 2 ^ mc (left = k / 2 ^ m, right = (k + 1 ) / 2 ^ m, m = m, k = k)<- function (n, omega) {<- typewriter_interval (n)as.numeric (omega >= interval["left" ] & omega < interval["right" ])<- seq (0 , 1 , length.out = 1000 )<- 1 : 12 <- par (no.readonly = TRUE )par (mfrow = c (4 , 3 ), mar = c (3 , 3 , 2 , 1 ))for (n in n_show) {<- typewriter_value (n, xgrid)<- typewriter_interval (n)plot (xgrid, y, type = "l" , lwd = 2 ,ylim = c (0 , 1.1 ),main = paste0 ("n=" , n, " [" ,"left" ], ", " , interval["right" ], ")" ),xlab = "" , ylab = "" )
次に,固定した \(\omega\) ごとに \(X_n(\omega)\) を見る。各 \(\omega\) について,0 に落ち着くのではなく,1 が何度も現れる。
<- 64 <- c (0.12 , 0.37 , 0.63 )<- sapply (omega_list, function (w) {sapply (1 : N, function (n) typewriter_value (n, w))matplot (1 : N, mat, type = "s" , lty = 1 , lwd = 2 ,xlab = "n" , ylab = "X_n(omega)" ,main = "Typewriter sequence for fixed omega" )legend ("topright" ,legend = paste0 ("omega = " , omega_list),lty = 1 , lwd = 2 , bty = "n" )
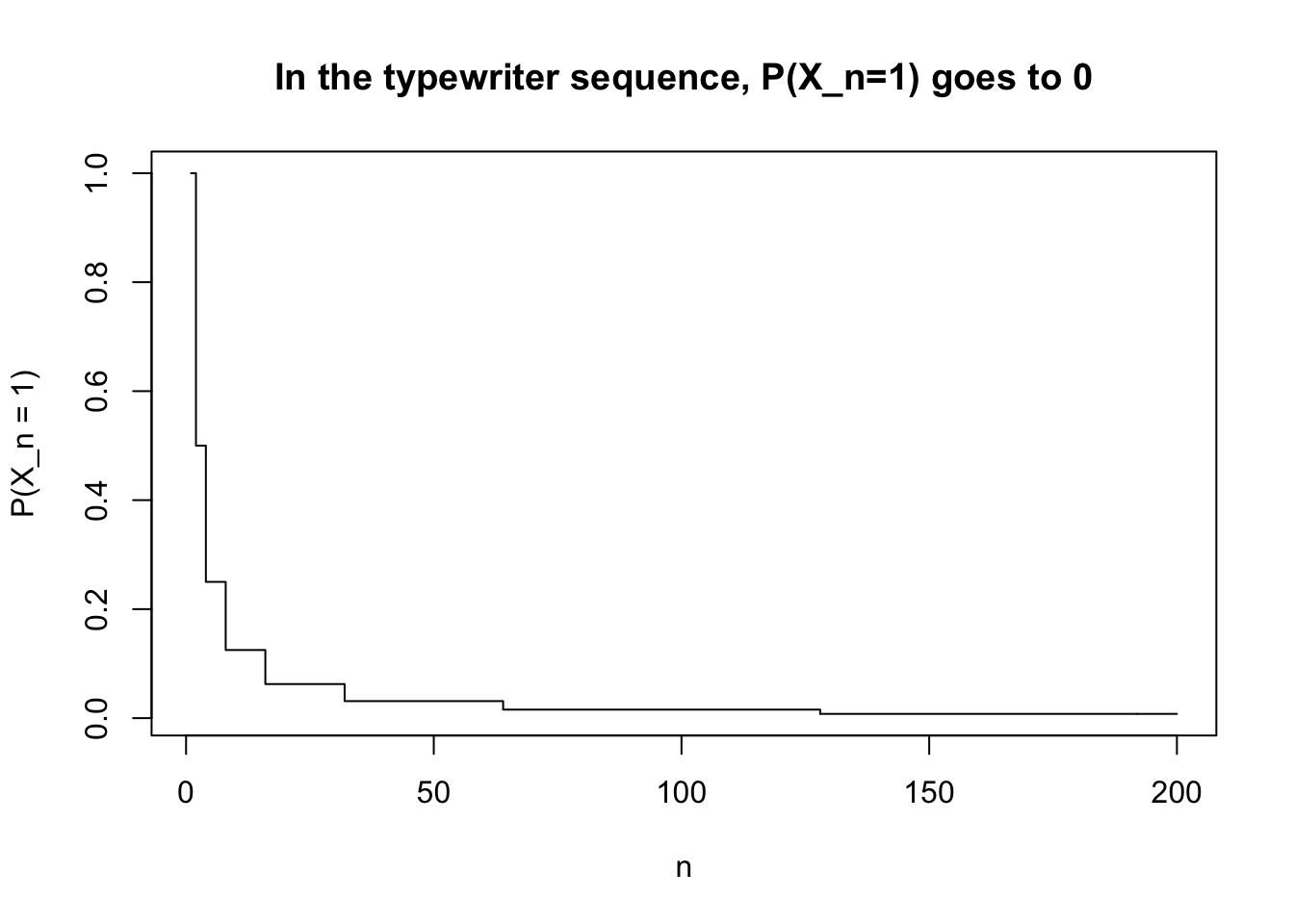
一方で,\(P(X_n=1)\) はブロックが進むほど小さくなる。
<- 1 : 200 <- sapply (n_grid, function (n) {<- typewriter_interval (n)"right" ] - interval["left" ]plot (n_grid, prob_one, type = "s" ,xlab = "n" , ylab = "P(X_n = 1)" ,main = "In the typewriter sequence, P(X_n=1) goes to 0" )
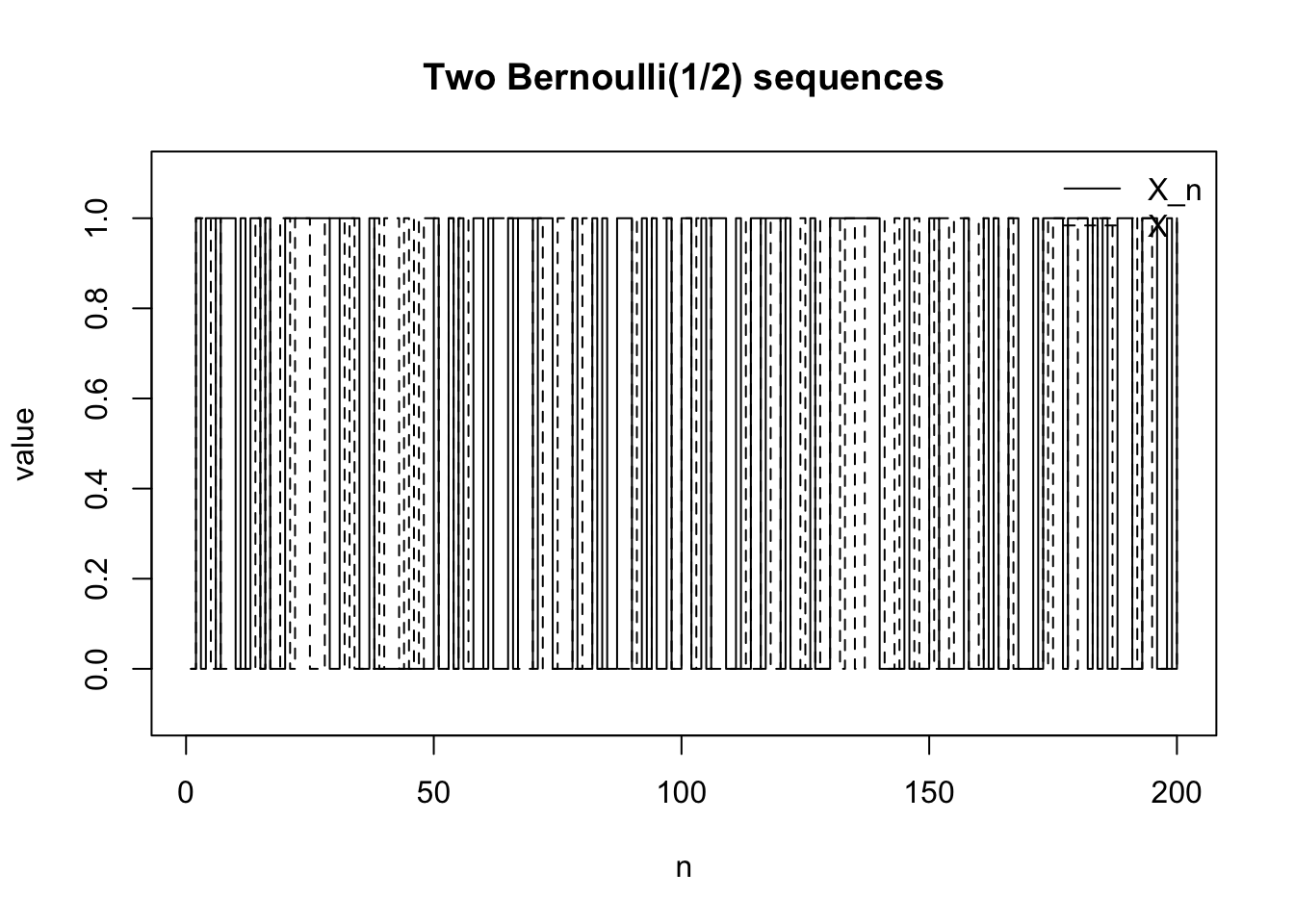
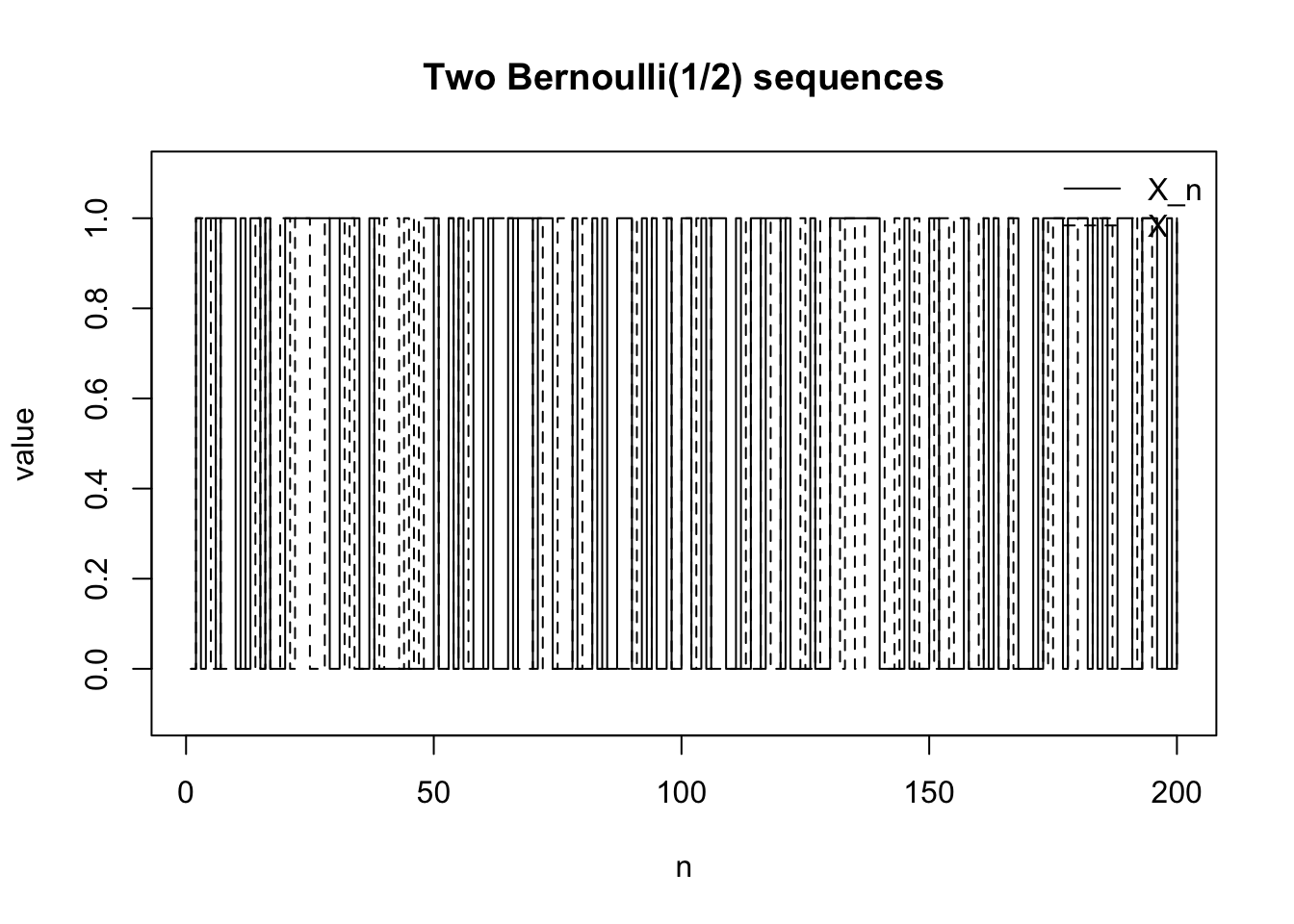
例4:法則収束するが,確率収束しない例
確率変数列 \(X_n\) がすべて同じ分布を持つが,実現値としては全く落ち着かない例を考える。
たとえば,同じ確率空間上に独立な Bernoulli 確率変数列 \((X_n)\) を取り,
\[
P(X_n=1)=P(X_n=0)=\frac12
\]
とする。さらに \(X\) も同じ Bernoulli\((1/2)\) 分布に従う確率変数とする。
このとき各 \(n\) について \(X_n\) と \(X\) は同じ分布を持つので,任意の有界連続関数 \(f\) に対して
\[
E[f(X_n)] = E[f(X)]
\]
である。したがって
\[
X_n\xrightarrow{d}X
\]
が成り立つ。
しかし一般には
\[
X_n\xrightarrow{P}X
\]
は成り立たない。 たとえば \(X\) を \(X_n\) たちと独立に取れば,
\[
P(|X_n-X|>1/2)=P(X_n\neq X)=\frac12
\]
であり,これは 0 に収束しない。
したがってこの例は
\[
X_n\xrightarrow{d}X
\quad\text{だが}\quad
X_n\not\xrightarrow{P}X
\]
となる例である。
このことから,法則収束は非常に弱い収束概念であり,分布の形が近づくことしか言っていないことがわかる。
小さい \(n\) での見え方と simulation
この例では,\(n\) が変わっても各 \(X_n\) の分布はずっと同じである。たとえば \(n=1,2,3,4\) についても
\[
P(X_n=0)=P(X_n=1)=\frac12
\]
であり,分布表はすべて
probability
\(1/2\) \(1/2\)
である。したがって分布だけを見ると \(X_1,X_2,X_3,\dots\) は全く変わっていない。しかし同じ \(\omega\) に沿って実現値を見ると,0 と 1 が不規則に現れ続ける。
set.seed (123 )<- 200 <- rbinom (N, size = 1 , prob = 0.5 )<- rbinom (N, size = 1 , prob = 0.5 )plot (1 : N, x, type = "s" , ylim = c (- 0.1 , 1.1 ),xlab = "n" , ylab = "value" ,main = "Two Bernoulli(1/2) sequences" )lines (1 : N, y, type = "s" , lty = 2 )legend ("topright" , legend = c ("X_n" , "X" ),lty = c (1 , 2 ), bty = "n" )
両者は同じ分布を持つので,分布の意味では全く同じである。しかし実現値としては一致し続けるわけではない。
set.seed (123 )<- 100000 <- rbinom (B, size = 1 , prob = 0.5 )<- rbinom (B, size = 1 , prob = 0.5 )mean (abs (x - y) > 0.5 )
この値は \(P(X_n\neq X)=1/2\) のシミュレーション近似であり,0 に近づくものではない。
例5:確率収束するが \(L^1\) 収束しない例
次に,確率収束はするが平均の意味では収束しない例を挙げる。 確率変数列 \((X_n)\) を
\[
X_n=
\begin{cases}
n & \text{確率 } \frac1n,\\
0 & \text{確率 } 1-\frac1n
\end{cases}
\]
で定める。
このとき任意の \(\varepsilon>0\) に対して,\(n>\varepsilon\) なら
\[
P(|X_n|>\varepsilon)=P(X_n=n)=\frac1n\to 0
\]
なので,
\[
X_n\xrightarrow{P}0
\]
である。
しかし期待値は
\[
E[|X_n|]=n\cdot \frac1n = 1
\]
で一定であり,0 に収束しない。したがって
\[
X_n\not\xrightarrow{L^1}0
\]
である。
この例は,大きな値を取る確率は小さいが,たまに非常に大きな値を取るために,平均の意味では消えてくれない状況を表している。
小さい \(n\) での見え方と simulation
具体的には,
\[
\begin{array}{c|cc}
n & X_n=0 & X_n=n\\
\hline
2 & 1/2 & 1/2\\
3 & 2/3 & 1/3\\
4 & 3/4 & 1/4\\
5 & 4/5 & 1/5\\
10 & 9/10 & 1/10
\end{array}
\]
である。\(n\) が大きいほど 0 を取る確率は高くなるので,確率収束の意味では 0 に近づいている。しかし,非ゼロになったときの値も \(n\) に大きくなるので,期待値は消えない。
set.seed (123 )<- function (n, B = 10000 ) {<- runif (B)ifelse (u <= 1 / n, n, 0 )<- c (2 , 5 , 10 , 20 , 50 , 100 , 200 )<- numeric (length (n_grid))<- numeric (length (n_grid))for (i in seq_along (n_grid)) {<- n_grid[i]<- sample_Xn (n)<- mean (x != 0 )<- mean (abs (x))<- par (no.readonly = TRUE )par (mfrow = c (1 , 2 ))plot (n_grid, prob_nonzero, type = "b" ,xlab = "n" , ylab = "P(X_n != 0)" ,main = "Probability of nonzero value" )plot (n_grid, mean_abs, type = "b" ,xlab = "n" , ylab = "E[|X_n|] (simulated)" ,main = "Mean absolute value stays around 1" )abline (h = 1 , lty = 2 )
この例では
\(P(X_n\neq 0)=1/n\to 0\) なので確率収束はするしかし \(E|X_n|=1\) のままなので \(L^1\) 収束はしない
という違いがはっきり見える。
例6:\(L^p\) 収束すれば確率収束することの直感
最後に,\(L^p\) 収束がかなり強い条件であることを確認しておく。 もし
\[
E[|X_n-X|^p]\to 0
\]
なら,Markov の不等式より任意の \(\varepsilon>0\) に対して
\[
P(|X_n-X|>\varepsilon) = P(|X_n-X|^p>\varepsilon^p)
\le
\frac{E[|X_n-X|^p]}{\varepsilon^p}
\to 0
\]
である。したがって
\[
X_n\xrightarrow{L^p}X
\quad\Longrightarrow\quad
X_n\xrightarrow{P}X.
\]
この含意は一般に成り立つが,逆は例5で見たように成り立たない。
具体例と simulation
たとえば
\[
X_n =
\begin{cases}
1 & \text{確率 } 1/n^2,\\
0 & \text{確率 } 1-1/n^2
\end{cases}
\]
とおく。このとき
\[
E[|X_n|^p]=\frac{1}{n^2}\to 0
\]
なので,任意の \(p\ge 1\) について \(X_n\xrightarrow{L^p}0\) である。小さい \(n\) では,
\[
\begin{array}{c|cc}
n & X_n=0 & X_n=1\\
\hline
1 & 0 & 1\\
2 & 3/4 & 1/4\\
3 & 8/9 & 1/9\\
4 & 15/16 & 1/16\\
5 & 24/25 & 1/25
\end{array}
\]
となる。非ゼロの値そのものは 1 のままだが,その確率が十分速く小さくなるので,平均的な大きさも確率的なずれも同時に消える。
<- 1 : 100 <- 1 / n_grid^ 2 <- 1 / n_grid^ 2 <- lp_moment / 0.5 plot (n_grid, tail_prob, type = "l" , lwd = 2 ,xlab = "n" , ylab = "probability / bound" ,main = "L^1 control implies probability control" )lines (n_grid, markov_bound, lty = 2 , lwd = 2 )legend ("topright" ,legend = c ("P(|X_n| > 0.5)" , "E|X_n| / 0.5" ),lty = c (1 , 2 ), lwd = 2 , bty = "n" )
この図では,実際の tail probability と Markov の不等式による上界がどちらも 0 に向かっている。
ここまでの例からわかること
以上の例から,収束概念の強さにはおおよそ次の関係があることが見えてくる。
\[
X_n \xrightarrow{L^p} X
\quad\Longrightarrow\quad
X_n \xrightarrow{P} X
\quad\Longrightarrow\quad
X_n \xrightarrow{d} X,
\]
また
\[
X_n \to X \text{ a.s.}
\quad\Longrightarrow\quad
X_n \xrightarrow{P} X.
\]
ただし逆向きは一般には成り立たない。 実際,
例3は「確率収束するが概収束しない」例
例5は「確率収束するが \(L^1\) 収束しない」例
例4は「法則収束するが確率収束しない」例
になっていた。
したがって,今後大数の法則や中心極限定理を学ぶときには,「どの意味で収束しているのか」を常に意識することが重要である。
収束概念の間の関係
先ほどの例で見た4つの収束概念の間の関係性についてフォーマルに確認していく。
概収束ならば確率収束
定理 \(X_n\to X\) a.s. ならば
\[
X_n\xrightarrow{P}X
\]
が成り立つ。
証明 \(m,j\in\mathbb N\) に対して
\[
A_{m,j}=\{|X_m-X|\leq 1/j\}
\]
とおく。すると,点列の収束の定義より
\[
\left\{\lim_{n\to\infty}X_n=X\right\}
=
\bigcap_{j=1}^{\infty}\bigcup_{n=1}^{\infty}\bigcap_{m=n}^{\infty}A_{m,j}
\]
が成り立つ。実際,\(X_n(\omega)\to X(\omega)\) であることは,任意の \(j\) に対して,ある \(n\) が存在して,それ以後すべての \(m\geq n\) で
\[
|X_m(\omega)-X(\omega)|\leq 1/j
\]
となることと同値であるからである。
いま \(X_n\to X\) a.s. を仮定しているので,左辺の事象の確率は \(1\) である。したがって,任意の固定した \(j\) に対して
\[
P\left(\bigcup_{n=1}^{\infty}\bigcap_{m=n}^{\infty}A_{m,j}\right)=1
\]
である。
ここで
\[
B_{n,j}=\bigcap_{m=n}^{\infty}A_{m,j}
\]
とおくと,\(n\) を大きくするほど共通部分をとる集合が減るので
\[
B_{n,j}\subset B_{n+1,j}
\]
であり,したがって \((B_{n,j})_{n\geq 1}\) は単調増加列である。よって確率の連続性から
\[
\lim_{n\to\infty}P(B_{n,j})
=
P\left(\bigcup_{n=1}^{\infty}B_{n,j}\right)
=1
\]
を得る。
しかも \(B_{n,j}\subset A_{n,j}\) であるから
\[
P(A_{n,j})\geq P(B_{n,j})
\]
であり,したがって
\[
\lim_{n\to\infty}P(A_{n,j})=1
\]
が従う。すなわち,各 \(j\) に対して
\[
\lim_{n\to\infty}P\left(|X_n-X|\leq \frac1j\right)=1
\]
である。
ここで任意に \(\varepsilon>0\) をとる。\(1/j\leq \varepsilon\) となるように \(j\) を十分大きくとれば
\[
\left\{|X_n-X|\leq \frac1j\right\}
\subset
\{|X_n-X|\leq \varepsilon\}
\]
であるから
\[
P(|X_n-X|\leq \varepsilon)
\geq
P\left(|X_n-X|\leq \frac1j\right).
\]
よって右辺を \(n\to\infty\) とすると
\[
\lim_{n\to\infty}P(|X_n-X|\leq \varepsilon)=1
\]
となる。したがって
\[
\lim_{n\to\infty}P(|X_n-X|>\varepsilon)=0
\]
であり,\(X_n\xrightarrow{P}X\) が示された。\(\square\)
\(p\) 次平均収束ならば確率収束定理 \(p\geq 1\) とする。\(X_n\xrightarrow{L^p}X\) ならば
\[
X_n\xrightarrow{P}X
\]
が成り立つ。
証明 \(\varepsilon>0\) に対して,Markov の不等式を非負確率変数 \(|X_n-X|^p\) に適用すると
\[
P(|X_n-X|>\varepsilon)
=
P(|X_n-X|^p>\varepsilon^p)
\leq
\frac{E[|X_n-X|^p]}{\varepsilon^p}
\]
を得る。右辺は仮定により \(n\to\infty\) で \(0\) に収束するから,
\[
\lim_{n\to\infty}P(|X_n-X|>\varepsilon)=0
\]
である。したがって \(X_n\xrightarrow{P}X\) が従う。\(\square\)
逆は一般には成り立たない
先にいくつかの例で確認した通り,上の2つの定理の逆は一般には成り立たない。
また,概収束と \(L^p\) 収束の間にも,一方向の包含関係は一般には存在しない 。
そのことを具体例で確認しておく。
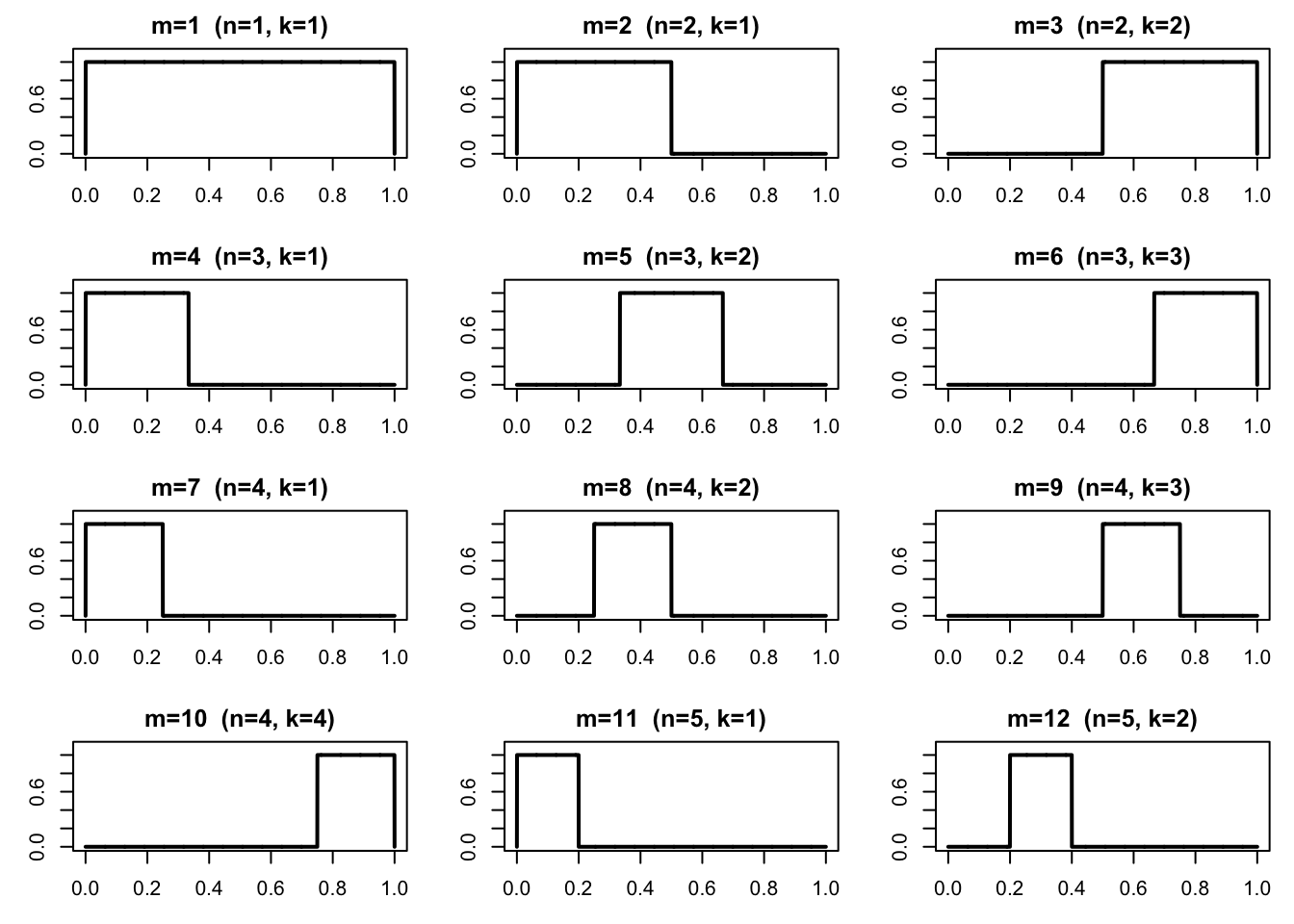
\(L^p\) 収束しても概収束しない例\((\Omega,\mathcal F,P)=((0,1),\mathcal B((0,1)),\lambda)\) とし,\(\lambda\) はルベーグ測度とする。各 \(n\geq 1\) と \(1\leq k\leq n\) に対して
\[
X_{n,k}(\omega)=\mathbf 1_{\left(\frac{k-1}{n},\frac{k}{n}\right)}(\omega),
\qquad \omega\in(0,1)
\]
と定める。これらを
\[
X_{1,1},\ X_{2,1},X_{2,2},\ X_{3,1},X_{3,2},X_{3,3},\ \dots
\]
の順に一列に並べて得られる確率変数列を \((Y_m)_{m\geq 1}\) とする。
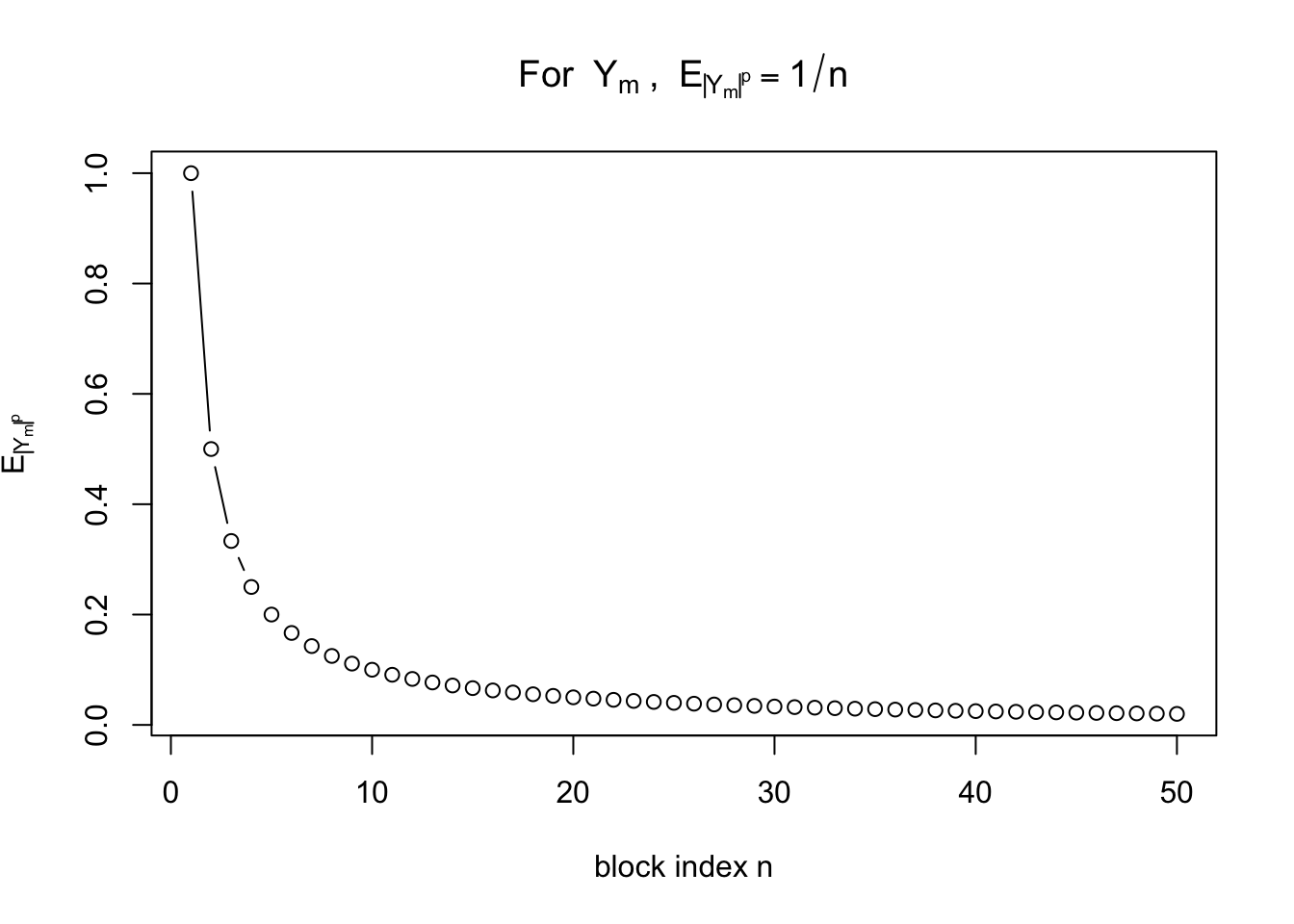
主張 \(Y_m\to 0\) は任意の \(p\geq 1\) について \(L^p\) 収束し,したがって確率収束する。しかし概収束はしない。
証明 \(L^p\) 収束を示す。\(Y_m\) が第 \(n\) ブロックに属するとき,すなわち \(Y_m=X_{n,k}\) であるとき,
\[
E[|Y_m|^p]=E[|X_{n,k}|^p]=E[X_{n,k}]=\lambda\left(\left(\frac{k-1}{n},\frac{k}{n}\right)\right)=\frac1n
\]
である。\(m\to\infty\) なら対応するブロック番号 \(n\to\infty\) だから,
\[
E[|Y_m|^p]\to 0
\]
が成り立つ。ゆえに \(Y_m\xrightarrow{L^p}0\) である。したがって先ほどの定理より \(Y_m\xrightarrow{P}0\) でもある。
次に概収束しないことを示す。端点の集合
\[
D=\bigcup_{n=1}^{\infty}\left\{\frac{k}{n}:k=1,2,\dots,n-1\right\}
\]
は可算集合なので
\[
P(D)=0
\]
である。したがって \(\omega\in (0,1)\setminus D\) をとれば,各 \(n\) に対してただ一つの \(k_n\in\{1,\dots,n\}\) が存在して
\[
\omega\in \left(\frac{k_n-1}{n},\frac{k_n}{n}\right)
\]
となる。よって第 \(n\) ブロック
\[
X_{n,1}(\omega),\dots,X_{n,n}(\omega)
\]
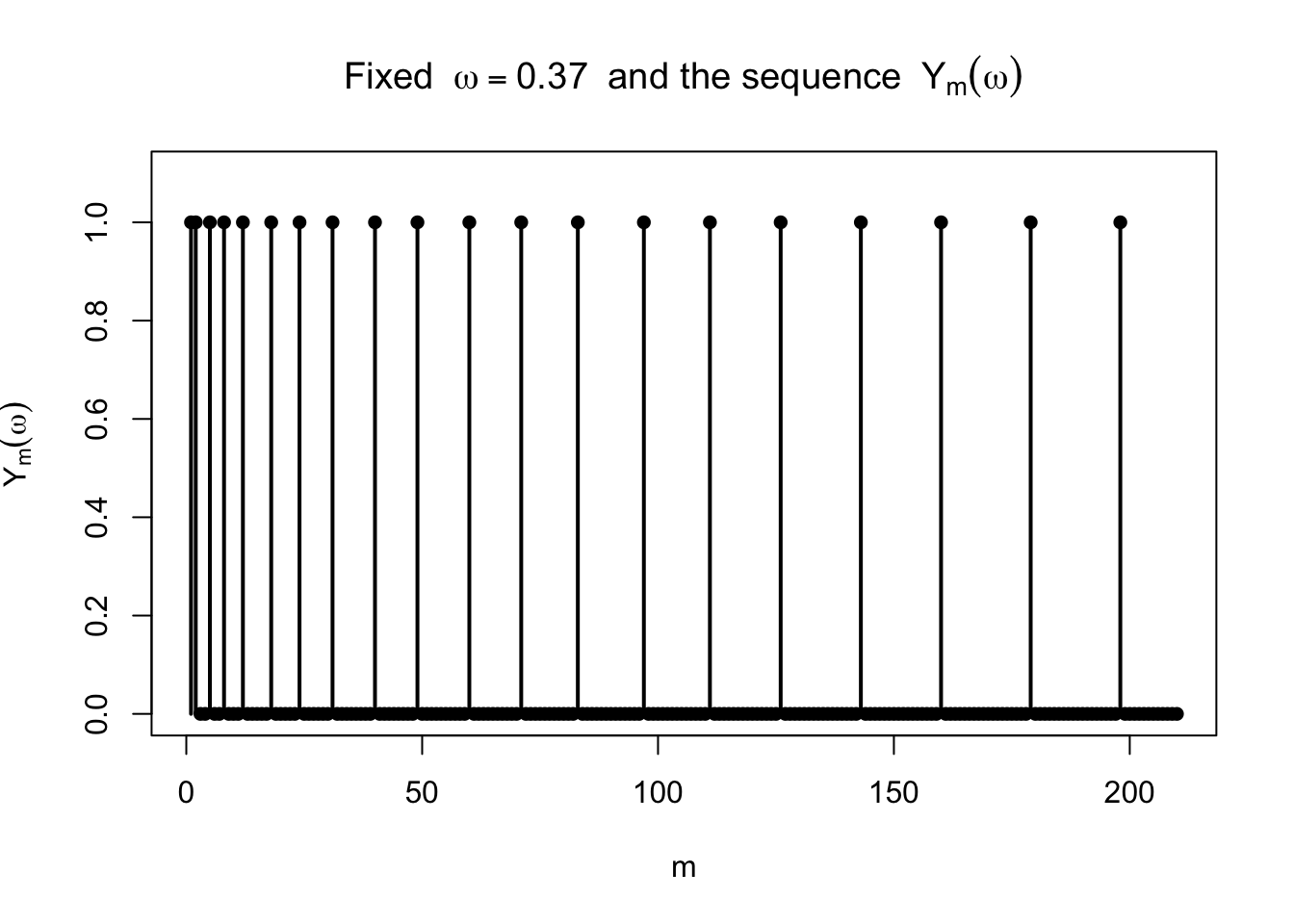
の中ではちょうど一つだけが \(1\) で,残りはすべて \(0\) である。したがって列 \((Y_m(\omega))\) は \(1\) を無限回とり,同時に \(0\) も無限回とる。ゆえに \(Y_m(\omega)\) は収束しない。
これは \(\omega\in (0,1)\setminus D\) のすべてで起きるから,
\[
P\bigl(\{\omega:Y_m(\omega)\text{ は収束しない}\}\bigr)=1
\]
である。したがって \(Y_m\) は \(0\) に概収束しない。\(\square\)
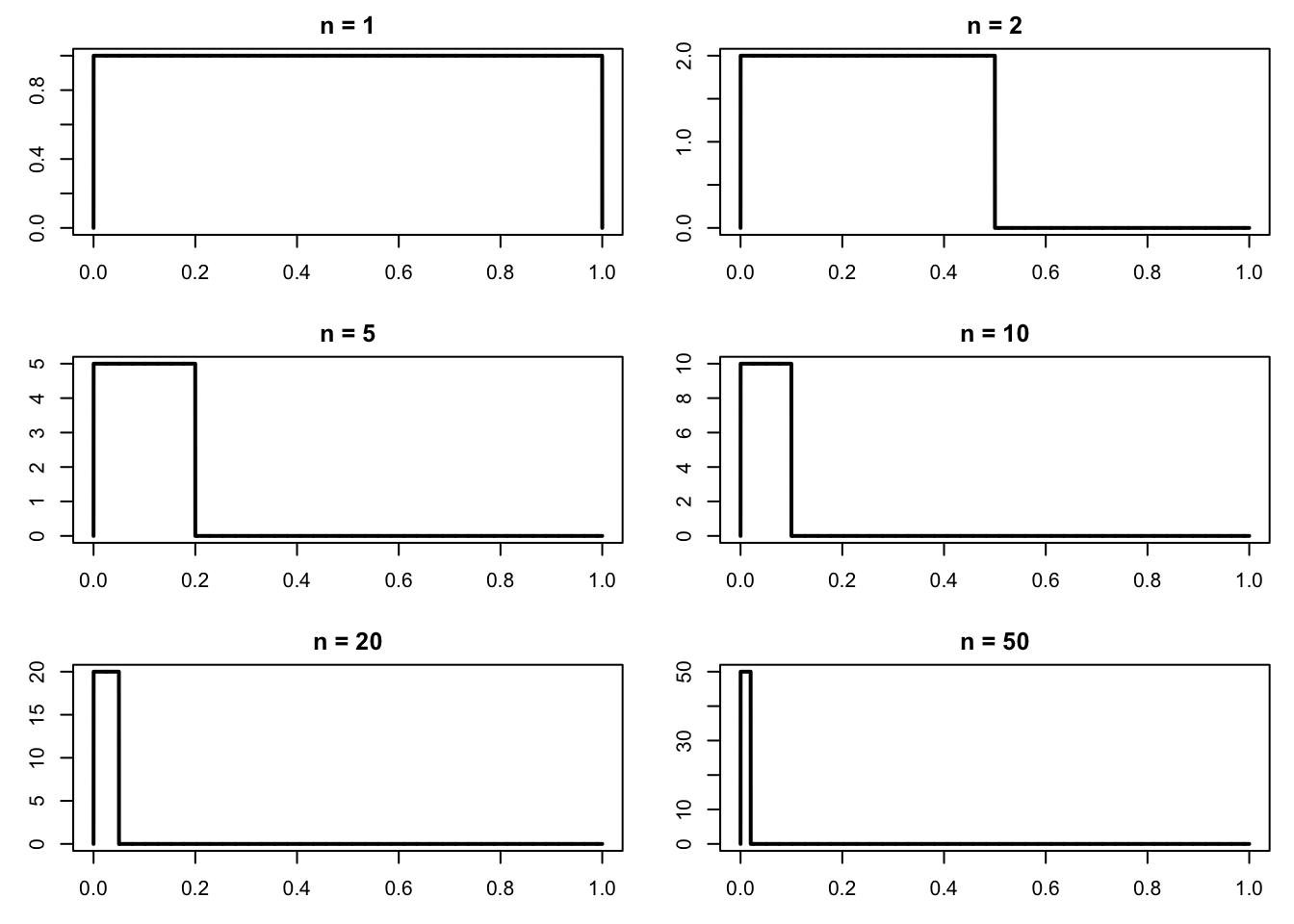
この例では,各 \(Y_m\) は「ある小区間の上でだけ \(1\) をとり,それ以外では \(0\) であるような指示関数」である。\(n\) が大きくなるほど,その小区間の長さは \(1/n\) となって細くなっていく。したがって各 \(Y_m\) の「面積」は 0 に近づいていき,\(L^p\) 収束が起こる。
一方で,固定した \(\omega\) を見ると,各ブロックごとにちょうど一度だけ \(Y_m(\omega)=1\) となるので,列 \(Y_m(\omega)\) は 0 に落ち着かない。\(L^p\) 収束は「平均的な大きさ」が小さくなることを表しているが,点ごとの収束を保証するわけではない。
以下の図は,最初のいくつかの \(Y_m\) の形を描いたものである。
<- function (max_block = 6 ) {<- data.frame (m = integer (), n = integer (), k = integer ())<- 1 for (n in 1 : max_block) {for (k in 1 : n) {<- rbind (out, data.frame (m = m, n = n, k = k))<- m + 1 <- function (x, n, k) {as.numeric (x > (k - 1 ) / n & x < k / n)<- make_Y_index (max_block = 6 )<- seq (0 , 1 , length.out = 2000 )par (mfrow = c (4 , 3 ), mar = c (3 , 3 , 2 , 1 ))for (j in 1 : 12 ) {<- Y_index$ n[j]<- Y_index$ k[j]<- Y_fun (xgrid, n, k)plot (xgrid, y, type = "l" , lwd = 2 ,ylim = c (0 , 1.1 ),main = paste0 ("m=" , j, " (n=" , n, ", k=" , k, ")" ),xlab = "" , ylab = "" )
各図は,高さ \(1\) の細い長方形が左から右へ動いている形になっている。 \(n\) が大きくなるほど長方形の幅が狭くなっていることがわかる。
次に,固定した \(\omega\) を1つ取り,\(Y_m(\omega)\) の列がどう振る舞うかを見てみる。
<- function (omega, max_block = 20 ) {<- c ()<- make_Y_index (max_block)for (j in 1 : nrow (index)) {<- index$ n[j]<- index$ k[j]<- as.numeric (omega > (k - 1 ) / n & omega < k / n)data.frame (m = 1 : length (vals), value = vals)<- 0.37 <- Y_value_at_omega (omega, max_block = 20 )plot (df_omega$ m, df_omega$ value, type = "h" , lwd = 2 ,ylim = c (0 , 1.1 ),xlab = "m" , ylab = expression (Y[m](omega)),main = bquote ("Fixed " ~ omega == .(omega) ~ " and the sequence " ~ Y[m](omega)))points (df_omega$ m, df_omega$ value, pch = 16 )
この図からわかるように,\(Y_m(\omega)\) は 0 に近づいていくのではなく,1 が何度も現れる。 したがって概収束はしない。
一方で,各 \(Y_m\) の \(L^p\) ノルムはブロック番号 \(n\) に対して \(1/n\) であり,確かに 0 に近づいていく。
<- 1 : 50 <- 1 / n_valsplot (n_vals, lp_size, type = "b" ,xlab = "block index n" ,ylab = expression (E[abs (Y[m])^ p]),main = expression ("For " ~ Y[m] ~ ", " ~ E[abs (Y[m])^ p] == 1 / n))
この例は,
\[
L^p\text{ 収束 }\not\Rightarrow \text{ 概収束}
\]
であることを示している。
概収束しても \(L^p\) 収束しない例
同じく \((\Omega,\mathcal F,P)=((0,1),\mathcal B((0,1)),\lambda)\) 上で
\[
X_n(\omega)=n,\mathbf 1_{(0,1/n)}(\omega),
\qquad \omega\in(0,1)
\]
と定める。
主張 \(X_n\to 0\) a.s. かつ \(X_n\xrightarrow{P}0\) である。しかし任意の \(p\geq 1\) に対して \(X_n\) は \(0\) に \(L^p\) 収束しない。
証明 まず概収束を示す。任意の固定した \(\omega\in(0,1)\) に対して,\(n>1/\omega\) ならば \(1/n<\omega\) なので
\[
\omega\notin (0,1/n)
\]
である。したがって十分大きい \(n\) では \(X_n(\omega)=0\) となる。よって
\[
X_n(\omega)\to 0
\]
がすべての \(\omega\in(0,1)\) について成り立つ。したがって
\[
X_n\to 0 \quad \text{a.s.}
\]
である。よって前の定理から \(X_n\xrightarrow{P}0\) でもある。
一方,任意の \(p\geq 1\) に対して
\[
E[|X_n|^p] = \int_0^1 n^p\mathbf 1_{(0,1/n)}(\omega),d\omega
= n^p\cdot \frac1n
n^{p-1}.
\]
したがって
\[
E[|X_n|^p]=n^{p-1}
\]
は \(p=1\) では常に \(1\) であり,\(p>1\) では \(n\to\infty\) で無限大に発散する。特に
\[
E[|X_n-0|^p]\not\to 0
\]
なので,\(X_n\) は \(0\) に \(L^p\) 収束しない。\(\square\)
この例では,各 \(X_n\) は \((0,1/n)\) の上でだけ高さ \(n\) をとり,それ以外では \(0\) である。 したがってグラフとしては,原点の近くに幅の狭い高い柱が立っているような形になる。
このとき,固定した \(\omega>0\) に対しては,十分大きい \(n\) で \(\omega\notin(0,1/n)\) となるため,やがて \(X_n(\omega)=0\) になる。 したがって概収束は成り立つ。 しかしその一方で,柱の高さが \(n\) まで大きくなるため,\(L^p\) ノルムは 0 に近づかない。
以下の図は,いくつかの \(X_n\) の形を描いたものである。
<- function (x, n) {ifelse (x > 0 & x < 1 / n, n, 0 )<- seq (0 , 1 , length.out = 5000 )<- c (1 , 2 , 5 , 10 , 20 , 50 )par (mfrow = c (3 , 2 ), mar = c (3 , 3 , 2 , 1 ))for (n in n_list) {<- X_fun (xgrid, n)plot (xgrid, y, type = "l" , lwd = 2 ,main = paste0 ("n = " , n),xlab = "" , ylab = "" )
\(n\) が大きくなるにつれて,柱の幅は狭くなるが高さは急激に増えている。 この図から,「各点ではやがて 0 になる」のに「平均的な大きさは消えない」という現象が視覚的にも理解できる。
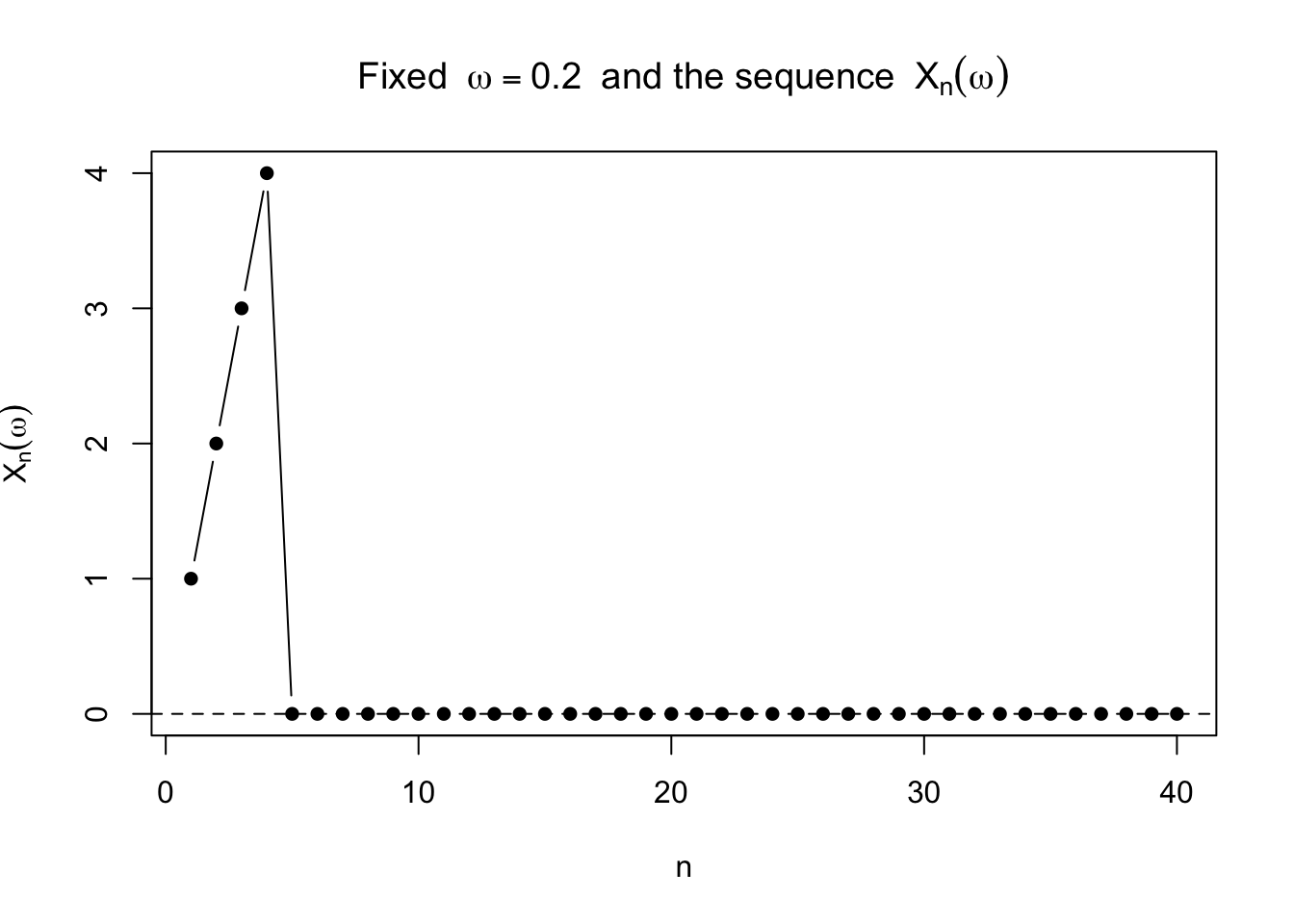
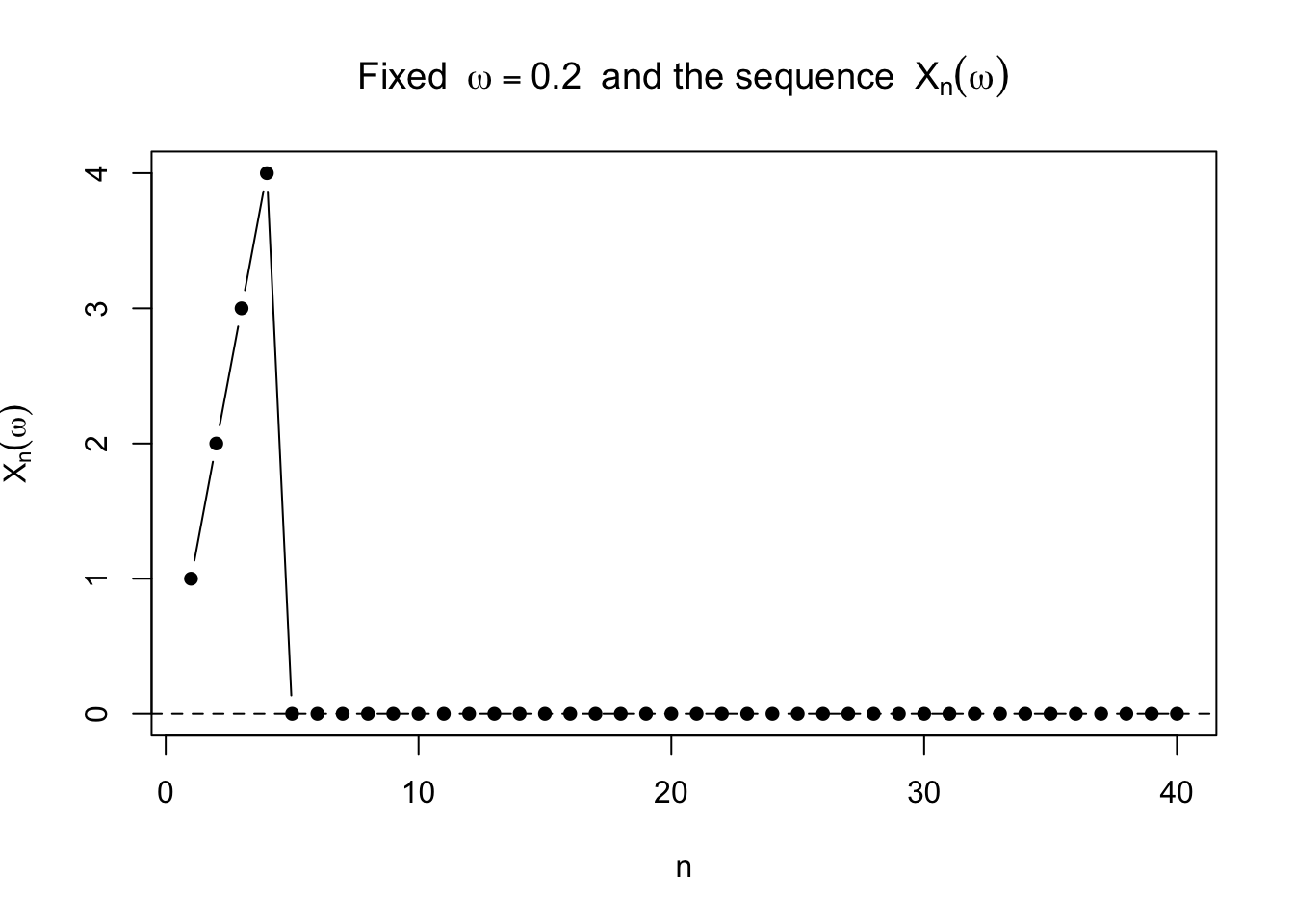
実際,固定した \(\omega\) での列 \(X_n(\omega)\) を見ると,十分大きな \(n\) では 0 になっている。
<- 0.2 <- 1 : 40 <- sapply (n_grid, function (n) ifelse (omega > 0 & omega < 1 / n, n, 0 ))plot (n_grid, vals, type = "b" , pch = 16 ,xlab = "n" , ylab = expression (X[n](omega)),main = bquote ("Fixed " ~ omega == .(omega) ~ " and the sequence " ~ X[n](omega)))abline (h = 0 , lty = 2 )
たとえば \(\omega=0.2\) のとき,\(n>5\) なら \(1/n<0.2\) なので,それ以降はずっと \(X_n(\omega)=0\) である。 これが概収束の理由である。
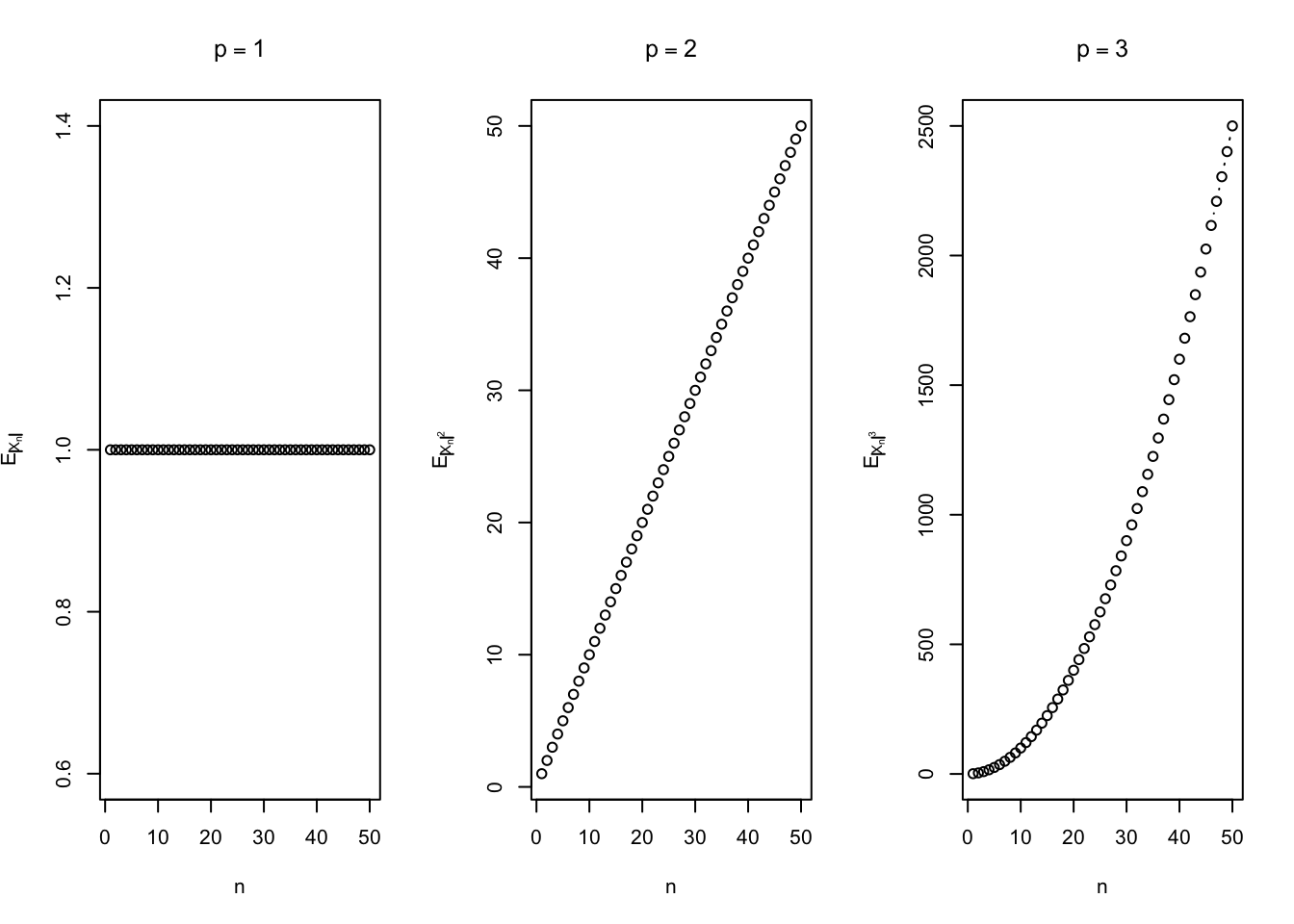
しかし \(L^p\) ノルムの方は全く違う振る舞いをする。実際,
\[
E[|X_n|^p]=n^{p-1}
\]
だから,\(p=1\) では一定であり,\(p>1\) では発散する。
<- 1 : 50 par (mfrow = c (1 , 3 ))plot (n_grid, rep (1 , length (n_grid)), type = "b" ,xlab = "n" , ylab = expression (E[abs (X[n])]),main = expression (p == 1 ))plot (n_grid, n_grid, type = "b" ,xlab = "n" , ylab = expression (E[abs (X[n])^ 2 ]),main = expression (p == 2 ))plot (n_grid, n_grid^ 2 , type = "b" ,xlab = "n" , ylab = expression (E[abs (X[n])^ 3 ]),main = expression (p == 3 ))
したがってこの例は,
\[
\text{概収束 }\not\Rightarrow L^p\text{ 収束}
\]
であることを示している。
まとめ
以上の2つの例から,概収束と \(L^p\) 収束は互いに全く異なる情報を表していることがわかる。
\(L^p\) 収束は,確率変数全体の「平均的な大きさ」が小さくなることを意味する。 これに対して概収束は,ほとんどすべての \(\omega\) ごとに見たときの点ごとの極限を問題にしている。
そのため,
関数の面積は小さくなっていても,固定した点で見たときに 1 が無限回現れれば概収束はしない。
逆に,各点ではやがて 0 になっても,その間に非常に高いスパイクが立っていれば \(L^p\) 収束はしない。
今後,大数の法則や中心極限定理を学ぶときにも,「どの意味で収束しているのか」を明確に意識することが重要である。
確率収束から概収束する部分列を取り出せる
確率収束は概収束より弱いが,完全に無関係というわけではない。確率収束している列からは,適当に部分列を取り出すと概収束が得られる。
定理(部分列定理) \(X_n\xrightarrow{P}X\) ならば,ある部分列 \((X_{n_k})\) が存在して
\[
X_{n_k}\to X \quad \text{a.s.}
\]
が成り立つ。特に,\(X_n\xrightarrow{L^p}X\) ならば,ある部分列 \((X_{n_k})\) が存在して
\[
X_{n_k}\to X \quad \text{a.s.}
\]
が成り立つ。
証明 \(X_n\xrightarrow{P}X\) を仮定する。すると,任意の \(\varepsilon>0\) に対して
\[
P(|X_n-X|>\varepsilon)\to 0
\qquad (n\to\infty)
\]
である。
ここで各 \(k\in\mathbb N\) に対して \(\varepsilon=2^{-k}\) をとる。すると
\[
P\left(|X_n-X|>2^{-k}\right)\to 0
\qquad (n\to\infty)
\]
だから,各 \(k\) ごとに十分大きい \(n_k\) を選んで
\[
P\left(|X_{n_k}-X|>2^{-k}\right)<2^{-k}
\]
となるようにできる。さらに必要なら \(n_1<n_2<\cdots\) となるように選び直せば,\((X_{n_k})\) は部分列になる。
ここで
\[
A_k=\{|X_{n_k}-X|>2^{-k}\}
\]
とおく。\(A_k\) は,「\(k\) 番目に選んだ部分列の値 \(X_{n_k}\) が,\(X\) から \(2^{-k}\) 以上ずれている」という事象である。
我々が示したいのは,ほとんどすべての \(\omega\) に対して,十分大きい \(k\) では
\[
|X_{n_k}(\omega)-X(\omega)|\leq 2^{-k}
\]
が成り立つことである。\(2^{-k}\to 0\) だから,これが成り立てば
\[
X_{n_k}(\omega)\to X(\omega)
\]
が従うからである。
したがって問題は,「\(A_k\) が何回起こるか」を調べることに帰着される。
まず任意の \(m\) に対して,Boole の不等式より
\[
P\left(\bigcup_{k=m}^{\infty}A_k\right)
\leq
\sum_{k=m}^{\infty}P(A_k)
<
\sum_{k=m}^{\infty}2^{-k}.
\]
右辺は等比級数の tail だから,\(m\to\infty\) で \(0\) に収束する。
ここで
\[
\bigcup_{k=m}^{\infty}A_k
\]
は,「\(k\ge m\) のどこかで少なくとも一度は \(A_k\) が起こる」という事象である。\(m\) 回目以降に bad event が一回でも起こる」という意味である。
さらに
\[
\bigcap_{m=1}^{\infty}\bigcup_{k=m}^{\infty}A_k
\]
を考える。\(m\) について「\(m\) 回目以降に少なくとも一度は \(A_k\) が起こる」が成り立つということである。
この集合の意味を言葉で書くと,
どれだけ先に進んでも,
その先でまた \(A_k\) が起こる
ということである。\(A_k\) が無限回起こる」事象である。記号ではしばしば
\[
\{A_k \text{ i.o.}\}
\]
と書く。
実際,
もし \(A_k\) が無限回起これば,どんな \(m\) をとっても,\(k\ge m\) なる範囲に \(A_k\) が起こる場所が存在するので, \[
\omega\in \bigcup_{k=m}^{\infty}A_k
\] がすべての \(m\) について成り立つ。したがって \[
\omega\in \bigcap_{m=1}^{\infty}\bigcup_{k=m}^{\infty}A_k.
\]
逆に, \[
\omega\in \bigcap_{m=1}^{\infty}\bigcup_{k=m}^{\infty}A_k
\] なら,どんな \(m\) に対しても \(k\ge m\) で \(A_k\) が起こるものが存在する。したがって \(A_k\) は有限回しか起こらないことはありえず,無限回起こる。
よって確かに
\[
\bigcap_{m=1}^{\infty}\bigcup_{k=m}^{\infty}A_k
=
\{\omega:A_k \text{ が無限回起こる}\}
\]
である。
さて,上で示した評価 \[
P\left(\bigcup_{k=m}^{\infty}A_k\right)
\le
\sum_{k=m}^{\infty}2^{-k}
\] の右辺は \(m\to\infty\) で \(0\) に収束する。しかも \[
\bigcup_{k=m+1}^{\infty}A_k \subset \bigcup_{k=m}^{\infty}A_k
\] であるから,これらは単調減少列をなす。したがって確率の連続性より
\[
P\left(\bigcap_{m=1}^{\infty}\bigcup_{k=m}^{\infty}A_k\right)
=
\lim_{m\to\infty}
P\left(\bigcup_{k=m}^{\infty}A_k\right)
=0.
\]
すなわち,
\[
P(A_k \text{ i.o.})=0
\]
である。\(A_k\) が無限回起こることは,確率 0 でしか起こらない」という意味である。
したがって確率 1 の集合上で,\(A_k\) は高々有限回しか起こらない。\(\omega\) に対して,ある番号 \(m(\omega)\) が存在して,\(k\ge m(\omega)\) なら常に \(A_k\) は起こらない。
\(A_k\) が起こらないとは
\[
|X_{n_k}(\omega)-X(\omega)|\leq 2^{-k}
\]
ということである。よってほとんどすべての \(\omega\) に対して,十分大きい \(k\) では
\[
|X_{n_k}(\omega)-X(\omega)|\leq 2^{-k}
\]
が成り立つ。右辺は \(k\to\infty\) で 0 に収束するから,はさみうちにより
\[
X_{n_k}(\omega)\to X(\omega)
\]
である。
ゆえに
\[
P\bigl(\{\omega:X_{n_k}(\omega)\to X(\omega)\}\bigr)=1
\]
が成り立つ。すなわち
\[
X_{n_k}\to X \quad \text{a.s.}
\]
である。
最後に \(X_n\xrightarrow{L^p}X\) の場合は,すでに示した
\[
X_n\xrightarrow{L^p}X \;\Longrightarrow\; X_n\xrightarrow{P}X
\]
を用いれば,同様にある部分列 \((X_{n_k})\) が存在して
\[
X_{n_k}\to X \quad \text{a.s.}
\]
が従う。\(\square\)
要するに,確率収束から「ずれが起こる確率が非常に小さい項」だけをうまく抜き出すと,その bad event は無限回起こらなくなり,結果として概収束が得られる。
simulationで見てみる
部分列定理は,「確率収束している列は,そのままでは概収束しなくても,うまく項を間引けば概収束する」という主張である。 この現象を,先ほど見た typewriter sequence 型の例で可視化してみよう。
確率空間を \(([0,1],\mathcal B([0,1]),\lambda)\) とし,
\[
X_{n,k}(\omega)=\mathbf 1_{\left(\frac{k-1}{n},\frac{k}{n}\right)}(\omega)
\]
を考える。これを
\[
X_{1,1},\ X_{2,1},X_{2,2},\ X_{3,1},X_{3,2},X_{3,3},\ \dots
\]
の順に並べた列を \((Y_m)\) とする。
すでに見たように,この列は
\[
Y_m\xrightarrow{P}0
\]
であるが,
\[
Y_m\to 0 \quad \text{a.s.}
\]
は成り立たない。
しかし,各ブロックの最後の項
\[
X_{1,1}, X_{2,2}, X_{3,3}, X_{4,4}, \dots
\]
だけを抜き出すと,これは
\[
Z_n(\omega)=\mathbf 1_{\left(\frac{n-1}{n},1\right)}(\omega)
\]
となる。 このとき任意の固定した \(\omega\in(0,1)\) に対して,十分大きい \(n\) では
\[
\frac{n-1}{n}>\omega
\]
となるので,やがて \(\omega\notin ((n-1)/n,1)\) となる。したがって
\[
Z_n(\omega)\to 0
\qquad (\forall \omega\in(0,1))
\]
であり,
\[
Z_n\to 0 \quad \text{a.s.}
\]
が成り立つ。
つまり,元の列 \((Y_m)\) は概収束しないが,適切な部分列 \((Z_n)\) を取ると概収束する。
元の列と部分列を比べる R code
# block structure <- function (max_block = 40 ) {<- data.frame (m = integer (), n = integer (), k = integer ())<- 1 for (n in 1 : max_block) {for (k in 1 : n) {<- rbind (out, data.frame (m = m, n = n, k = k))<- m + 1 # value of Y_m(omega) <- function (omega, n, k) {as.numeric (omega > (k - 1 ) / n & omega < k / n)# full sequence Y_m(omega) <- function (omega, max_block = 40 ) {<- make_Y_index (max_block)<- mapply (function (n, k) Y_value (omega, n, k), idx$ n, idx$ k)data.frame (m = idx$ m, n = idx$ n, k = idx$ k, value = vals)# subsequence Z_n = X_{n,n} <- function (omega, max_n = 40 ) {<- sapply (1 : max_n, function (n) Y_value (omega, n, n))data.frame (n = 1 : max_n, value = vals)
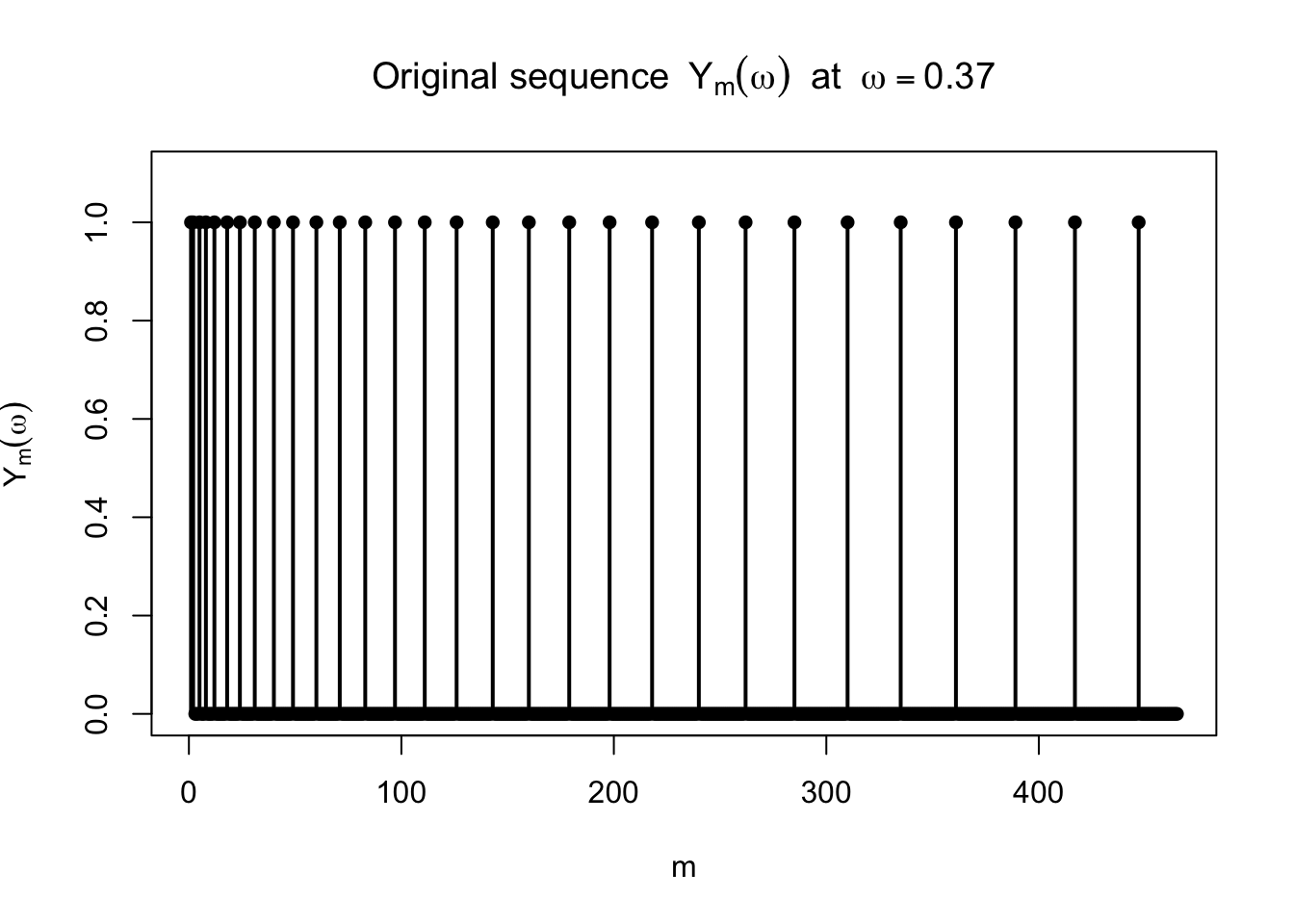
まず,固定した \(\omega\) に対して元の列 \(Y_m(\omega)\) を描く。
<- 0.37 <- Y_seq_at_omega (omega, max_block = 30 )plot (dfY$ m, dfY$ value, type = "h" , lwd = 2 ,ylim = c (0 , 1.1 ),xlab = "m" , ylab = expression (Y[m](omega)),main = bquote ("Original sequence " ~ Y[m](omega) ~ " at " ~ omega == .(omega)))points (dfY$ m, dfY$ value, pch = 16 )
この図では,1 が何度も現れ続けるので,\(Y_m(\omega)\) は 0 に収束しないことが見てとれる。
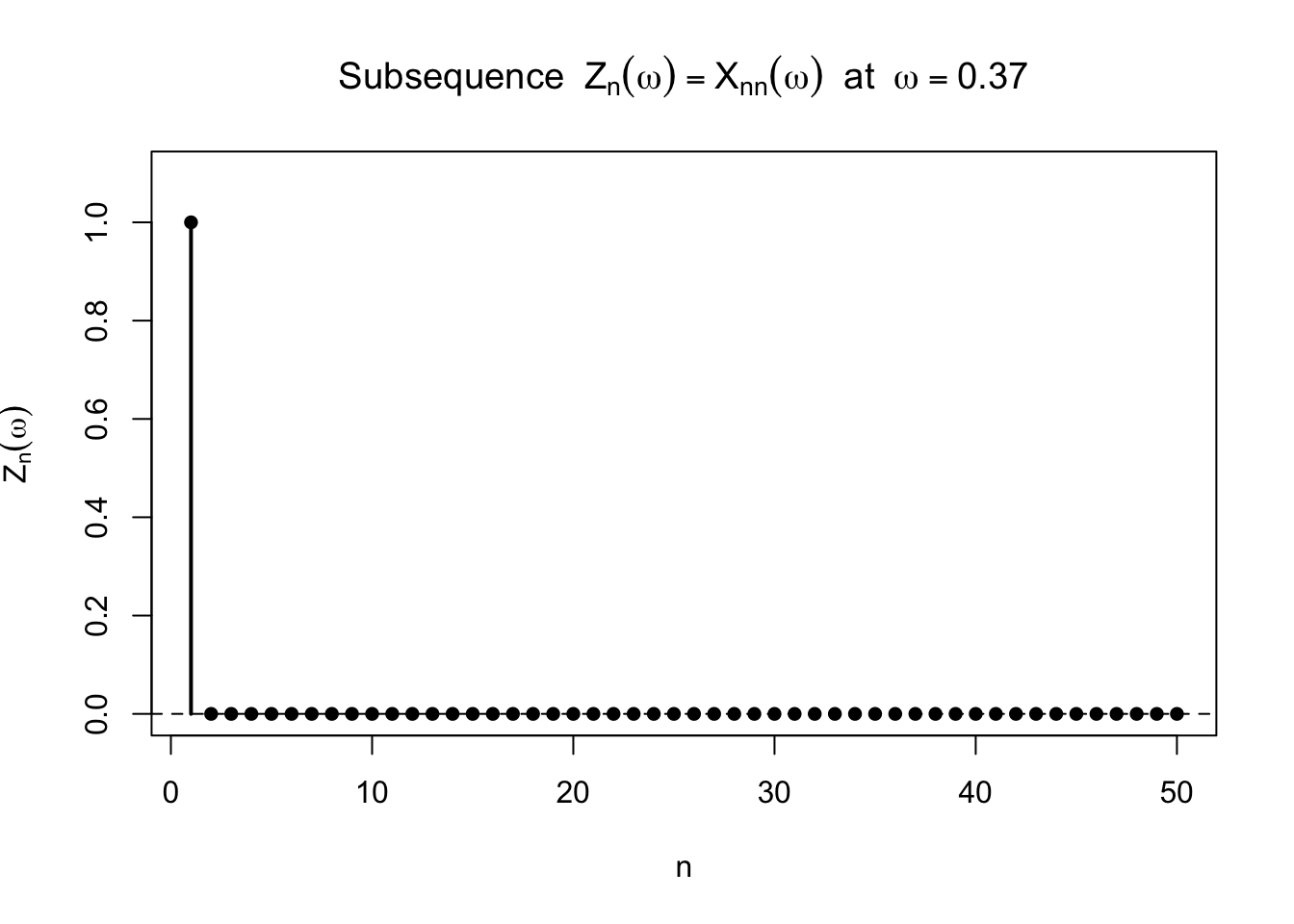
次に,各ブロックの最後だけを抜き出した部分列
\[
Z_n = X_{n,n}
\]
を同じ \(\omega\) で描く。
<- Z_seq_at_omega (omega, max_n = 50 )plot (dfZ$ n, dfZ$ value, type = "h" , lwd = 2 ,ylim = c (0 , 1.1 ),xlab = "n" , ylab = expression (Z[n](omega)),main = bquote ("Subsequence " ~ Z[n](omega) == X[n* n](omega) ~ " at " ~ omega == .(omega)))points (dfZ$ n, dfZ$ value, pch = 16 )abline (h = 0 , lty = 2 )
こちらでは,あるところから先はずっと 0 になる。 つまり,部分列を取ることで,点ごとの収束が見えるようになっている。
複数の \(\omega\) で同時に見る
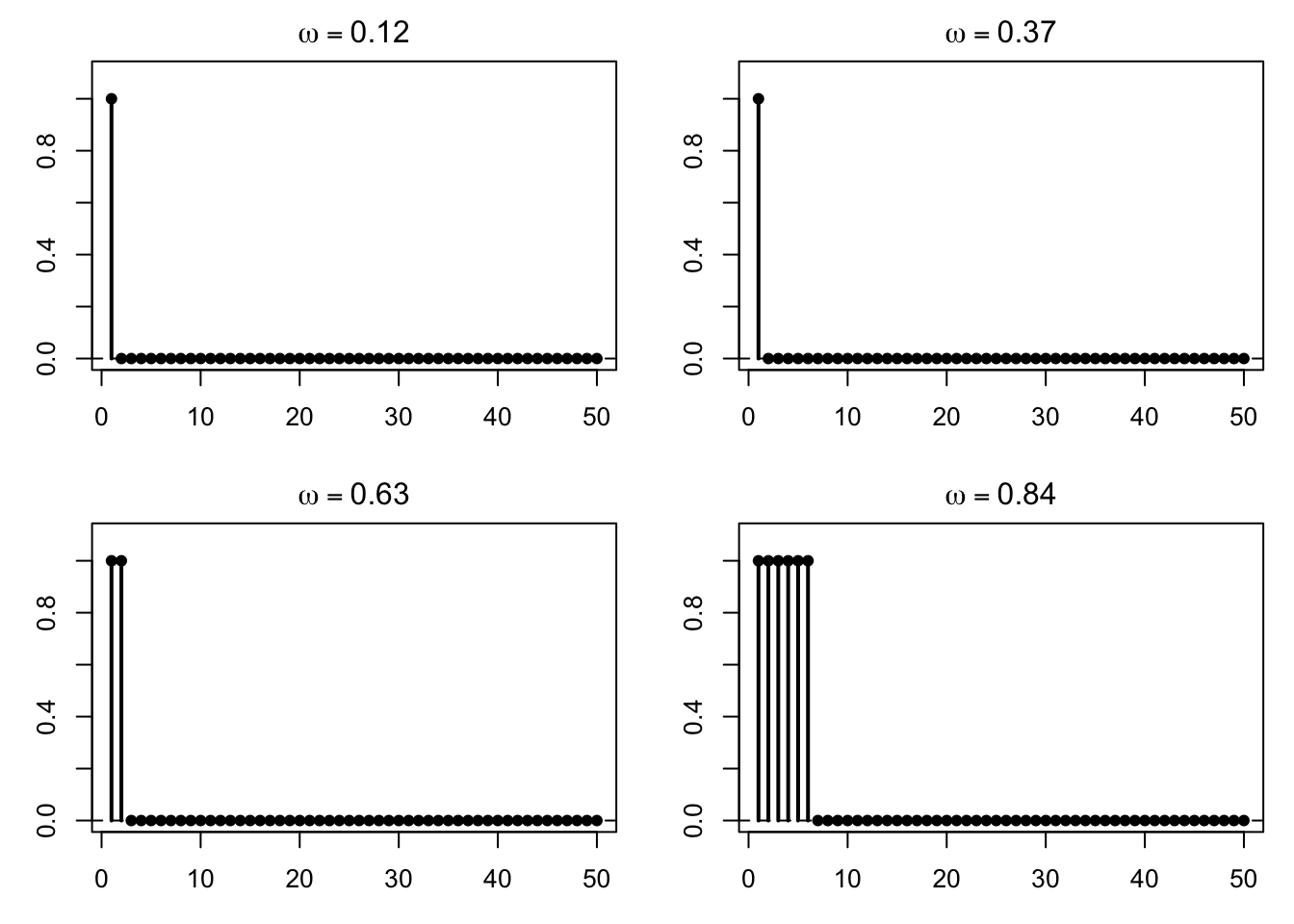
部分列定理の雰囲気をより強く見るために,いくつかの異なる \(\omega\) について同時に描いてみる。
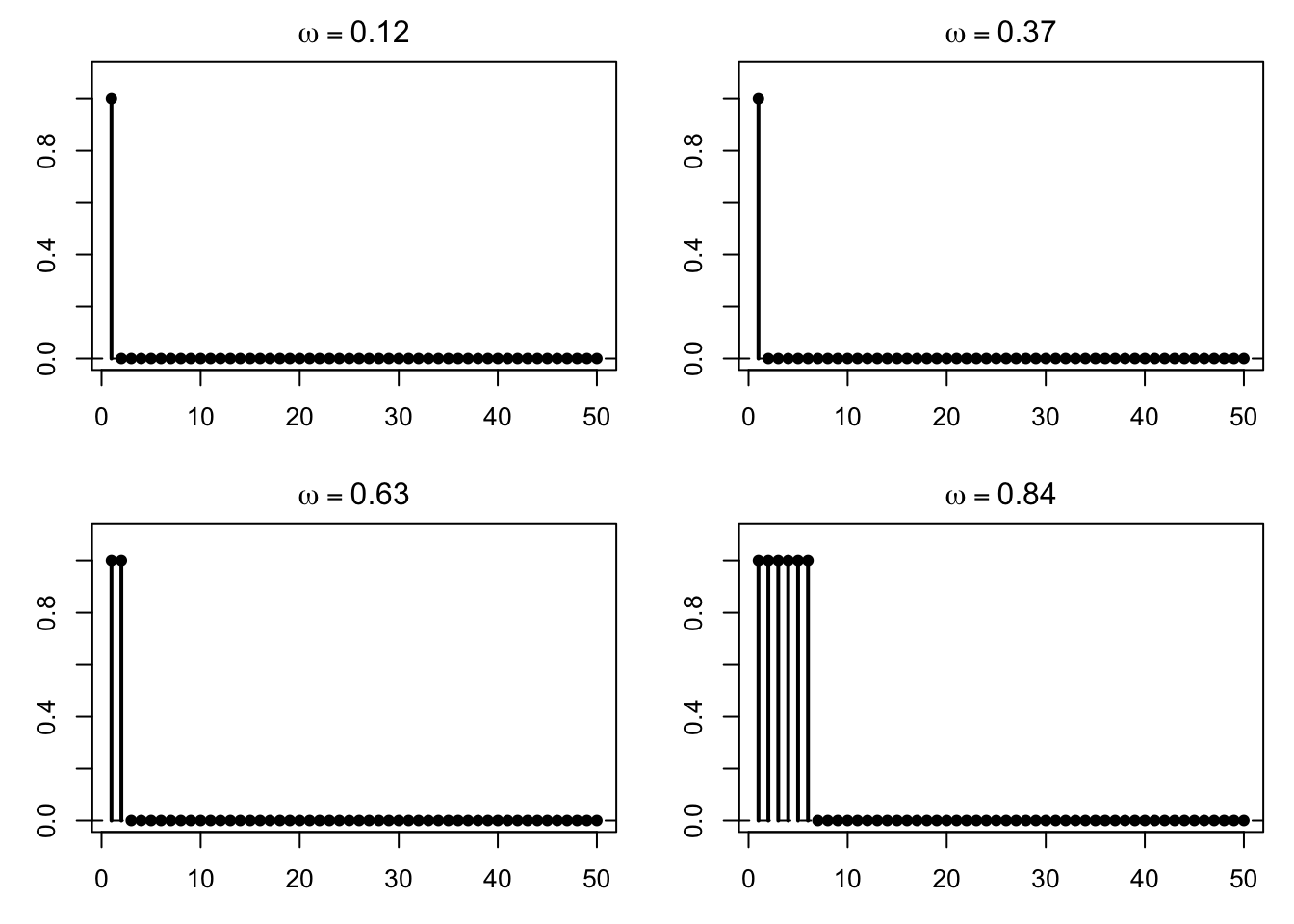
<- c (0.12 , 0.37 , 0.63 , 0.84 )par (mfrow = c (2 , 2 ), mar = c (3 , 3 , 2 , 1 ))for (omega in omega_list) {<- Z_seq_at_omega (omega, max_n = 50 )plot (dfZ$ n, dfZ$ value, type = "h" , lwd = 2 ,ylim = c (0 , 1.1 ),xlab = "n" , ylab = expression (Z[n](omega)),main = bquote (omega == .(omega)))points (dfZ$ n, dfZ$ value, pch = 16 )abline (h = 0 , lty = 2 )
どの \(\omega\) でも,十分大きい \(n\) では 0 になっていることがわかる。 これが概収束に対応している。
この simulation が何を表しているか
この simulation では,元の列 \((Y_m)\) は確率収束しているが,固定した \(\omega\) で見ると 1 が何度も現れるため,概収束しない。 しかし適切に部分列 \((Z_n)\) を抜き出すと,各 \(\omega\) についてやがて 0 になり,概収束が成り立つ。
部分列定理の一般の証明では,この「うまい抜き出し方」を
\[
P(|X_{n_k}-X|>2^{-k})<2^{-k}
\]
となるように選ぶことで実現している。 つまり,\(k\) 番目の項では「まだ大きくずれている確率」が非常に小さいものだけを選んでいる。
その結果,bad event
\[
A_k={|X_{n_k}-X|>2^{-k}}
\]
は無限回起こらなくなり,最終的に
\[
X_{n_k}\to X \quad \text{a.s.}
\]
が得られる。
確率収束ならば法則収束
定理 \(X_n\xrightarrow{P}X\) ならば
\[
X_n\xrightarrow{d}X
\]
が成り立つ。
証明 \(f\in C_b(\mathbb R)\) をとる。示すべきことは
\[
E[f(X_n)]\to E[f(X)]
\]
である。
これが成り立たないと仮定する。すると,ある \(\varepsilon_0>0\) と部分列 \((X_{n_k})\) が存在して,すべての \(k\) について
\[
|E[f(X_{n_k})]-E[f(X)]|\geq \varepsilon_0
\]
となる。
しかし \(X_n\xrightarrow{P}X\) なら部分列 \((X_{n_k})\) もやはり \(X\) に確率収束する。よって先ほどの部分列定理により,さらに部分列 \((X_{n_{k_j}})\) をとって
\[
X_{n_{k_j}}\to X \quad \text{a.s.}
\]
とできる。
\(f\) は連続だから
\[
f(X_{n_{k_j}})\to f(X) \quad \text{a.s.}
\]
である。また \(f\) は有界なので,ある定数 \(M>0\) が存在して
\[
|f(X_{n_{k_j}})|\leq M,
\qquad |f(X)|\leq M
\]
が成り立つ。したがって優収束定理により
\[
E[f(X_{n_{k_j}})]\to E[f(X)]
\]
を得る。これは
\[
|E[f(X_{n_{k_j}})]-E[f(X)]|\geq \varepsilon_0
\]
に矛盾する。したがって最初の仮定が誤りであり,
\[
E[f(X_n)]\to E[f(X)]
\]
が成り立つ。ゆえに \(X_n\xrightarrow{d}X\) である。\(\square\)
注意 \((0,1)\) 上の一様分布に従う確率変数 \(U(\omega)=\omega\) をとり,
\[
X_n=U,\qquad X=1-U
\]
とおくと,すべての \(n\) について \(X_n\) と \(X\) は同じ一様分布を持つので
\[
X_n\xrightarrow{d}X
\]
である。しかし \(0<\varepsilon<1\) に対して
\[
P(|X_n-X|>\varepsilon)=P(|2U-1|>\varepsilon)=1-\varepsilon
\]
であり,これは \(0\) に収束しない。したがって \(X_n\) は \(X\) に確率収束しない。
実数値確率変数の法則収束と分布関数
法則収束の定義は有界連続関数の期待値によって与えられているが,実数値確率変数の場合には分布関数による特徴づけがある。これが中心極限定理などで最も頻繁に用いられる形である。
\(X_n\) と \(X\) の分布関数をそれぞれ
\[
F_n(x)=P(X_n\leq x),
\qquad
F(x)=P(X\leq x)
\]
と書く。
定理(分布関数による特徴づけ) \((X_n)\) と実数値確率変数 \(X\) について,次は同値である。
\(X_n\xrightarrow{d}X\) 。\(F\) の連続点 \(x\) すべてに対して \[
F_n(x)\to F(x)
\] が成り立つ。
証明 \(\Rightarrow\) 2 を示す。\(x\) を \(F\) の連続点とする。任意の \(\delta>0\) に対して,連続関数
\[
g^-_{x,\delta}(t)=
\begin{cases}
1 & (t\leq x-\delta),\\
\dfrac{x-t}{\delta} & (x-\delta<t<x),\\
0 & (t\geq x),
\end{cases}
\]
\[
g^+_{x,\delta}(t)=
\begin{cases}
1 & (t\leq x),\\
\dfrac{x+\delta-t}{\delta} & (x<t<x+\delta),\\
0 & (t\geq x+\delta)
\end{cases}
\]
を考える。これらはともに \(C_b(\mathbb R)\) に属し,しかも
\[
g^-_{x,\delta}(t)
\leq
\mathbf 1_{(-\infty,x]}(t)
\leq
g^+_{x,\delta}(t)
\]
がすべての \(t\in\mathbb R\) について成り立つ。したがって
\[
E[g^-_{x,\delta}(X_n)]
\leq
F_n(x)
\leq
E[g^+_{x,\delta}(X_n)]
\]
である。いま \(X_n\xrightarrow{d}X\) だから,\(n\to\infty\) とすると
\[
E[g^-_{x,\delta}(X)]
\leq
\liminf_{n\to\infty}F_n(x)
\leq
\limsup_{n\to\infty}F_n(x)
\leq
E[g^+_{x,\delta}(X)]
\]
を得る。
ここで \(\delta\downarrow 0\) とすると,\(g^-_{x,\delta}(t)\uparrow \mathbf 1_{(-\infty,x)}(t)\) ,
\[
g^+_{x,\delta}(t)\downarrow \mathbf 1_{(-\infty,x]}(t)
\]
であるから,単調収束定理により
\[
E[g^-_{x,\delta}(X)]\uparrow P(X<x),
\qquad
E[g^+_{x,\delta}(X)]\downarrow P(X\leq x)=F(x)
\]
である。ところが \(x\) は \(F\) の連続点なので
\[
P(X<x)=P(X\leq x)=F(x)
\]
である。したがって \(\delta\downarrow 0\) とすると
\[
F(x)
\leq
\liminf_{n\to\infty}F_n(x)
\leq
\limsup_{n\to\infty}F_n(x)
\leq
F(x)
\]
となる。よって
\[
F_n(x)\to F(x)
\]
が示された。
次に 2 \(\Rightarrow\) 1 を示す。\(\mu_n=P_{X_n}\) ,\(\mu=P_X\) とおく。任意の \(f\in C_b(\mathbb R)\) をとり,
\[
M=\|f\|_\infty
\]
とおく。示すべきことは
\[
\int f\,d\mu_n \to \int f\,d\mu
\]
である。
任意の \(\varepsilon>0\) をとる。\(\mu\) は確率測度だから,\(F\) の連続点である \(a<b\) を十分大きくとって
\[
\mu\bigl(( -\infty,a]\cup (b,\infty)\bigr)<\varepsilon
\]
とできる。仮定より \(F_n(a)\to F(a)\) ,\(F_n(b)\to F(b)\) なので,十分大きい \(n\) について
\[
\mu_n\bigl(( -\infty,a]\cup (b,\infty)\bigr)<2\varepsilon
\]
も成り立つ。
分布関数の不連続点は高々可算だから,\([a,b]\) の中には \(F\) の連続点がいくらでも存在する。したがって,\(f\) はコンパクト区間 \([a,b]\) 上で一様連続であることを用いて,\(F\) の連続点からなる分割
\[
a=x_0<x_1<\cdots <x_m=b
\]
を十分細かくとって,各区間
\[
I_i=(x_{i-1},x_i],\qquad i=1,\dots,m
\]
上での \(f\) の振動が \(\varepsilon\) 以下になるようにできる。各 \(i\) について \(\xi_i\in I_i\) を一つ取り,段階関数
\[
s(t)=\sum_{i=1}^m f(\xi_i)\mathbf 1_{I_i}(t)
\]
を考える。すると \(t\in [a,b]\) では
\[
|f(t)-s(t)|\leq \varepsilon
\]
である。
よって十分大きい \(n\) に対して
\[
\begin{aligned}
\left|\int f\,d\mu_n-\int s\,d\mu_n\right|
&\leq \int |f-s|\,d\mu_n \\
&\leq \varepsilon\,\mu_n([a,b]) + 2M\,\mu_n\bigl(( -\infty,a]\cup (b,\infty)\bigr) \\
&\leq \varepsilon + 4M\varepsilon.
\end{aligned}
\]
同様に
\[
\left|\int f\,d\mu-\int s\,d\mu\right|
\leq
\varepsilon+2M\varepsilon.
\]
一方,\(x_i\) はすべて \(F\) の連続点なので,仮定から
\[
\mu_n(I_i)
=
F_n(x_i)-F_n(x_{i-1})
\to
F(x_i)-F(x_{i-1})
=
\mu(I_i)
\]
が成り立つ。したがって
\[
\int s\,d\mu_n
=
\sum_{i=1}^m f(\xi_i)\mu_n(I_i)
\to
\sum_{i=1}^m f(\xi_i)\mu(I_i)
=
\int s\,d\mu.
\]
以上より,十分大きい \(n\) に対して
\[
\begin{aligned}
\left|\int f\,d\mu_n-\int f\,d\mu\right|
&\leq
\left|\int f\,d\mu_n-\int s\,d\mu_n\right|
+
\left|\int s\,d\mu_n-\int s\,d\mu\right|
+
\left|\int s\,d\mu-\int f\,d\mu\right| \\
&\leq
(\varepsilon+4M\varepsilon)
+
\left|\int s\,d\mu_n-\int s\,d\mu\right|
+
(\varepsilon+2M\varepsilon).
\end{aligned}
\]
\(n\to\infty\) とすると真ん中の項は \(0\) に収束するので
\[
\limsup_{n\to\infty}\left|\int f\,d\mu_n-\int f\,d\mu\right|
\leq
2\varepsilon+6M\varepsilon.
\]
\(\varepsilon>0\) は任意だったから
\[
\int f\,d\mu_n\to\int f\,d\mu
\]
である。すなわち \(X_n\xrightarrow{d}X\) が成り立つ。\(\square\)
まとめ
以上で,確率変数列の収束概念の間に成り立つ基本関係は
\[
X_n\to X\ \text{a.s.}
\quad\Longrightarrow\quad
X_n\xrightarrow{P}X
\quad\Longrightarrow\quad
X_n\xrightarrow{d}X
\]
および
\[
X_n\xrightarrow{L^p}X
\quad\Longrightarrow\quad
X_n\xrightarrow{P}X
\]
であることがわかった。図で書けば
\[
\text{概収束} \quad \Longrightarrow \quad \text{確率収束} \quad \Longrightarrow \quad \text{法則収束}
\]
\[
\text{$p$ 次平均収束} \quad \Longrightarrow \quad \text{確率収束}
\]
である。
ただし,逆は一般には成り立たない。また,概収束と \(L^p\) 収束の間にも一般には直接の包含関係はない。先ほどの2つの例は,そのことをはっきり示している。