独立性
まずは独立性から導入する。教科書によって導入や独立性の定義の仕方、特に確率変数の独立性の定義の仕方は異なる。
このlecture noteでは舟木「確率論」に基本的には則って導入する。
事象の独立性
まず、事象 \(A, B\in \mathcal F\)の独立性について定義する。
定義(事象の独立性) \(A,B\in \mathcal F\)が独立であるとは \[
P(A\bigcap B) = P(A)P(B)
\]
が成立することを指す。
補題(同値な主張) 以下は同値
- \(A,B\)が独立
- \(A^c, B\)が独立
- \(A,B^c\)が独立
- \(A^c, B^c\)が独立
この補題は以下の含意を持つ。
\(A\) を含む最小の \(\sigma-\) 代数は \(\mathcal F_{A} = \{\emptyset, A,A^c, \Omega\}\) である。同様に、\(B\) を含む最小の \(\sigma-\) 代数は \(\mathcal F_{B} = \{\emptyset, B,B^c, \Omega\}\) である。この時、
\(A\) と \(B\) が独立ならば、\(\forall C_1\in \mathcal F_A,\ \forall C_2 \in \mathcal F_{B}\)に対して、
\[
P(C_1\bigcap C_2) = P(C_1)P(C_2)
\]
である。
これは \(\mathcal F_A\) と \(\mathcal F_B\) が独立っぽいと言ってもいい気がする。なぜなら、どちらの \(\sigma-\) 代数に含まれる情報(事象)のどれを取ってきても、その情報が独立だからである。
実際、このようにして \(\sigma-\)代数の独立性を定義する。
\(\sigma-\)代数の独立性
定義(\(\sigma-\)代数二つの独立性) \(\mathcal{F}_1\) と \(\mathcal{F}_2\) を \(\mathcal{F}\) の部分 \(\sigma\)-加法族,すなわち各 \(\mathcal{F}_k\)(\(k=1,2\))は \(\sigma\)-加法族で,\(\mathcal{F}_k \subset \mathcal{F}\) を満たすとして \(\mathcal{F}_1\) と \(\mathcal{F}_2\) が独立であるとは,任意の \(C_1 \in \mathcal{F}_1\) と \(C_2 \in \mathcal{F}_2\) に対して
\[
P(C_1 \cap C_2) = P(C_1)P(C_2)
\]
が成立するときにいう.
この定義をさらに一般化して
定義 (\(\sigma-\)代数たくさんの独立性)
(1) \(\mathcal{F}_1, \mathcal{F}_2, \ldots, \mathcal{F}_n\) を \(\mathcal{F}\) の部分 \(\sigma\)-加法族として \(\mathcal{F}_1, \mathcal{F}_2, \ldots, \mathcal{F}_n\) が独立(independent あるいは jointly independent)であるとは,任意の \(C_k \in \mathcal{F}_k\)(\(1 \leq k \leq n\))に対して
\[
P(C_1 \cap C_2 \cap \cdots \cap C_n) = \prod_{k=1}^{n} P(C_k)
\]
が成立するときにいう.
また,(一般に非可算の)集合 \(\Lambda\) でパラメータづけられた \(\mathcal{F}\) の部分 \(\sigma\)-加法族の集まり \(\{\mathcal{F}_k\}_{k \in \Lambda}\) が独立であるとは,\(\Lambda\) の任意の有限部分集合 \(\{k_1, k_2, \ldots, k_\ell\}\) に対して \(\{\mathcal{F}_{k_j}\}_{j=1,2,\ldots,\ell}\) が独立であるときにいう.
確率変数の独立性
今から、実数値確率変数はすべて同一の確率空間 \((\Omega, \mathcal{F}, P)\) で定義されているものとして,\(k=1,2,\ldots,n\) または \(\Lambda\) は一般の集合として \(k \in \Lambda\) とする。
定義(確率変数の独立性)
(1) \((X_k)_{k=1,2,\ldots,n}\) が独立とは,任意の \(A_1 \in \mathcal{B},\ A_2 \in \mathcal{B},\ldots,A_n \in \mathcal{B}\) に対して
\[
P(X_k \in A_k,\ k=1,2,\ldots,n)=\prod_{k=1}^n P(X_k \in A_k)
\]
が成立するときにいう.
- さらに一般に、\((X_k)_{k \in \Lambda}\) が独立とは,\(\Lambda\) の任意の有限部分集合 \(\{i_1,i_2,\ldots,i_\ell\}\) と \(A_1 \in \mathcal{B}, A_2 \in \mathcal{B},\ldots,A_\ell \in \mathcal{B}\) に対して
\[
P(X_{k_i}\in A_i,\ i=1,2,\ldots,\ell)=\prod_{i=1}^{\ell} P(X_{k_i}\in A_i)
\]
が成立するときにいう.
注意 確率変数 \(X\) が生成する \(\sigma\)-加法族を \(\sigma(X)\) とすれば、確率変数列の独立性はそれらが生成する \(\sigma\)-加法族の独立性と同値であることが示せる。しかし、この証明は結構必要な道具が多いので追わなくて良い。
命題 \(X_k\) の分布が確率密度関数 \(p_{X_k}(x)\) をもつとき,\((X_k)_{k=1,2,\ldots,n}\) の独立は,
\[
P(a_1 \leq X_1 \leq b_1,\ a_2 \leq X_2 \leq b_2,\ldots,a_n \leq X_n \leq b_n)
=
\prod_{k=1}^n \int_{a_k}^{b_k} p_{X_k}(x)\,dx
\]
が任意の \(a_1<b_1,\ a_2<b_2,\ldots,a_n<b_n\) に対して成立することと同値である.
さらに、確率変数列の独立性は,可測関数との合成によって保たれる。
補題(独立な確率変数の可測関数での写像も独立) 確率変数列 \((X_k)_{k=1,2,\ldots,n}\) は独立で,\(g_k:S_k\to S_k'\),\(k=1,2,\ldots,n\) は可測とする.ただし,\((S_k',\mathcal{S}_k')\) は他の可測空間とする.このとき
\[
Y_k=g_k(X_k),\ k=1,2,\ldots,n
\]
とおけば,\(S_k'\)-値確率変数列 \((Y_k)_{k=1,2,\ldots,n}\) は独立である.
証明 \(k=1,2,\ldots,n\) に対して
\[
\{Y_k\in A_k'\}=\{X_k\in g_k^{-1}(A_k')\},\qquad A_k'\in\mathcal{S}_k'
\]
であることに注意すればよい.
例 実数値確率変数 \(X\) と \(Y\) が独立ならば,\(X^2\) と \(Y^2\) は独立である
系 \((X_k)_{k=1,2,\ldots,n}\) は独立な実数値確率変数列で,\(g=g(x_1,x_2,\ldots,x_i):\mathbb{R}^i\to\mathbb{R}\) は可測とする.ただし,\(i<n\) である.このとき
\[
Y=g(X_1,X_2,\ldots,X_i)
\]
とおけば \(Y,\ X_{i+1},\ldots,X_n\) は独立な確率変数列である.
証明 \(X=(X_1,X_2,\ldots,X_i)\) は \(\mathbb{R}^i\)-値確率変数であり,\(X,\ X_{i+1},\ldots,X_n\) が独立であることが示せる。したがって,補題3.14 で \(S_1=\mathbb{R}^i,\ S_2=\cdots=S_{n-i+1}=\mathbb{R}\) ととればよい.
(さらっと)独立な確率変数なんて存在するの?
ここまでで確率変数の独立性を定義するはできた。すなわち、一つの確率空間 \((\Omega, \mathcal F,P)\)があったときに、その上に存在する確率変数列が独立であると言うことがどういうことなのかはわかった。
しかし、我々はまだ、そのような確率変数列が存在するのかはわかっていない。もしかしたらそのような独立な確率変数列なんて定義が厳しすぎて存在できないかもしれない。
果たして一つの確率空間上に独立な確率変数列は存在できるのか?
以上のような問題意識が存在する。問題意識が数学者すぎる。
ここでは詳細には触れないが、実際に一つの確率空間上に独立な確率変数列を構成することができることが知られている。詳しくは舟木を参照すること。
そして、その独立な確率変数列の全ての要素が同じ分布を持つとき、independent and identically distributedと言う。これを略してi.i.d.とかく。
条件付き期待値
ここからは条件付き期待値を厳密に導入する。
以下では,実数値確率変数 \(X\) は可積分,つまり
\[
E[|X|] < \infty
\]
を満たすとする。条件付き期待値は \(L^1\) の世界で定義できる。後で見るように,計量経済学的には二乗誤差を扱うので,特に \(L^2\) の中での射影として理解することが重要になる。
混乱しそうな点を注意しておくと,
素朴な定義では「条件付き確率」を定義してからそれを使って「条件付き期待値」を定義していた。
フォーマルな定義では逆で,「条件付き期待値」を定義してからそれを使って「条件付き確率」を定義している。
フォーマルな定義
まず,条件をつける対象は「事象」ではなく,「情報」を表す部分 \(\sigma\)-加法族 \(\mathcal G \subseteq \mathcal F\) である。
定義(条件付き期待値)
\((\Omega,\mathcal F,P)\) を確率空間,\(X\) を可積分な確率変数,\(\mathcal G\subseteq\mathcal F\) を部分 \(\sigma\)-加法族とする。
このとき,\(\mathcal G\) の下での \(X\) の条件付き期待値 \(E[X\mid \mathcal G]\) とは,次の2条件を満たす \(\mathcal G\)-可測な確率変数 \(Y\) のことである。
- \(Y\) は \(\mathcal G\)-可測である。
- 任意の \(B\in \mathcal G\) に対して \[
E[X1_B] = E[Y1_B]
\] が成立する。
このような \(Y\) は \(P\)-a.s. の意味で一意に定まり,その \(a.s.\) 同値類を \(E[X\mid \mathcal G]\) と書く。
この定義の2条件は,それぞれ次の意味をもつ。
- \(Y\) が \(\mathcal G\)-可測であること:\(Y\) は「\(\mathcal G\) が教えてくれる情報だけで決まる」こと。
- \(E[X1_B]=E[Y1_B]\) がすべての \(B\in\mathcal G\) で成り立つこと:\(\mathcal G\) のどの情報集合の上でも,\(Y\) は \(X\) と同じ平均をもつこと。
したがって,\(E[X\mid \mathcal G]\) は「\(\mathcal G\) に含まれる情報だけを使って \(X\) を表したときの,平均を保存する確率変数」と読むことができる。
定義(条件付き確率)
\(A\in \mathcal F\) に対して
\[
P(A\mid \mathcal G) := E[1_A\mid \mathcal G]
\]
と定め,これを \(\mathcal G\) の下での \(A\) の条件付き確率という。
記法
- \(E[X\mid Y]\) は \(E[X\mid \sigma(Y)]\) の略記である。
- 同様に,\(P(A\mid Y)\) は \(P(A\mid \sigma(Y))\) の略記である。
つまり,\(E[X\mid Y]\) とは本当は「確率変数 \(Y\) が生成する情報に条件をつけた期待値」である。
ラドン–ニコディムの定理による存在と一意性
上の定義は「そのような \(Y\) があれば」という形になっている。したがって,次に確認すべきことは,そのような \(Y\) が本当に存在するのか,そして存在するとしたら一意なのかである。
ここで使うのがラドン–ニコディムの定理である。
定理(ラドン–ニコディムの定理)
\((S,\mathcal A)\) を可測空間とし,\(\mu\) を \(\sigma\)-有限測度,\(\nu\) を \(\mu\) に絶対連続な \(\sigma\)-有限測度とする。すなわち
\[
\mu(A)=0 \quad \Rightarrow \quad \nu(A)=0
\qquad (A\in\mathcal A)
\]
が成り立つとする。このとき,非負 \(\mathcal A\)-可測関数 \(f\) が存在して,任意の \(A\in\mathcal A\) に対して
\[
\nu(A)=\int_A f\,d\mu
\]
が成り立つ。この \(f\) は \(\mu\)-a.e. の意味で一意であり,
\[
f=\frac{d\nu}{d\mu}
\]
と書く。
この定理を条件付き期待値にどう使うかを見よう。
定理(条件付き期待値の存在と一意性)
\((\Omega,\mathcal F,P)\) を確率空間,\(X\) を可積分な確率変数,\(\mathcal G\subseteq\mathcal F\) を部分 \(\sigma\)-加法族とする。このとき,\(E[X\mid\mathcal G]\) は存在し,\(P\)-a.s. の意味で一意である。
証明
まず \(X\) を正部分と負部分に分ける。
\[
X^+ := \max\{X,0\},
\qquad
X^- := \max\{-X,0\}.
\]
すると
\[
X=X^+-X^-,
\qquad
|X|=X^++X^-.
\]
\(X\) は可積分なので,\(E[X^+]<\infty\) かつ \(E[X^-]<\infty\) である。
ここで \(\mathcal G\) 上の2つの有限測度 \(\nu^+\) と \(\nu^-\) を
\[
\nu^+(B):=E[X^+1_B],
\qquad
\nu^-(B):=E[X^-1_B],
\qquad B\in\mathcal G
\]
で定義する。たとえば \(\nu^+\) について確認すると,
\[
\nu^+(\emptyset)=0,
\qquad
\nu^+(\Omega)=E[X^+]<\infty
\]
であり,互いに素な \(B_1,B_2,\dots\in\mathcal G\) に対しては単調収束定理より
\[
\nu^+\left(\bigcup_{j=1}^\infty B_j\right)
=
E\left[X^+1_{\cup_j B_j}\right]
=
E\left[X^+\sum_{j=1}^\infty 1_{B_j}\right]
=
\sum_{j=1}^\infty E[X^+1_{B_j}]
=
\sum_{j=1}^\infty \nu^+(B_j)
\]
が成り立つ。したがって \(\nu^+\) は \(\mathcal G\) 上の有限測度である。\(\nu^-\) も同様である。
また,\(P(B)=0\) なら
\[
\nu^+(B)=E[X^+1_B]=0,
\qquad
\nu^-(B)=E[X^-1_B]=0
\]
である。したがって,\(\nu^+\) と \(\nu^-\) はいずれも \(P\) を \(\mathcal G\) に制限した測度
\[
P_{\mathcal G}(B):=P(B),\qquad B\in\mathcal G
\]
に絶対連続である。
ここでラドン–ニコディムの定理を,測度空間 \((\Omega,\mathcal G,P_{\mathcal G})\) 上で \(\nu^+\) と \(\nu^-\) に適用する。すると,非負 \(\mathcal G\)-可測関数 \(Y^+\) と \(Y^-\) が存在して,任意の \(B\in\mathcal G\) に対して
\[
\nu^+(B)=\int_B Y^+\,dP,
\qquad
\nu^-(B)=\int_B Y^-\,dP
\]
が成り立つ。つまり
\[
E[X^+1_B]=E[Y^+1_B],
\qquad
E[X^-1_B]=E[Y^-1_B]
\]
である。さらに
\[
E[Y^+]=\nu^+(\Omega)=E[X^+]<\infty,
\qquad
E[Y^-]=\nu^-(\Omega)=E[X^-]<\infty
\]
なので,\(Y^+\) と \(Y^-\) は可積分である。
そこで
\[
Y:=Y^+-Y^-
\]
とおく。\(Y\) は \(\mathcal G\)-可測かつ可積分であり,任意の \(B\in\mathcal G\) に対して
\[
E[Y1_B]
=
E[Y^+1_B]-E[Y^-1_B]
=
E[X^+1_B]-E[X^-1_B]
=
E[X1_B]
\]
が成り立つ。したがって \(Y\) は条件付き期待値の定義を満たす。これで存在が示された。
次に一意性を示す。\(Y\) と \(Y'\) がともに条件付き期待値の定義を満たすとする。このとき \(Y,Y'\) は \(\mathcal G\)-可測なので
\[
D:=\{Y>Y'\}\in\mathcal G
\]
である。定義より
\[
E[Y1_D]=E[X1_D]=E[Y'1_D]
\]
なので
\[
E[(Y-Y')1_D]=0
\]
である。しかし \((Y-Y')1_D\ge 0\) であり,しかも \(D\) 上では正である。したがって \(P(D)=0\) でなければならない。同様に \(\{Y'<Y\}\) も確率 \(0\) である。よって
\[
Y=Y' \qquad a.s.
\]
である。\(\square\)
\(E[X\mid Y]\) は「\(Y\) の関数」である
\(E[X\mid Y]\) と書いたとき,これは \(\sigma(Y)\)-可測な確率変数である。したがって Doob–Dynkin の補題より,あるボレル可測関数 \(m\) が存在して
\[
E[X\mid Y] = m(Y) \qquad a.s.
\]
と書ける。
これが,計量経済学でよく見る
\[
m(x)=E[Y\mid X=x]
\]
という記法の厳密な中身である。
右辺を厳密に言い換えると,「\(\sigma(X)\)-可測な確率変数 \(E[Y\mid X]\) は \(X\) の関数として書けるので,その関数を \(m\) と書いている」ということである。
この見方は重要である。条件付き期待値は,一つの数ではなく,観測された情報の関数として変動する確率変数なのである。
素朴な定義との対応:有限分割の場合
最初に書いた「事象 \(B\) に条件をつける」という素朴な定義が,このフォーマルな定義の特別な場合として本当に出てくることを確認しよう。
命題(有限分割の場合の明示式)
\(\{B_1,\dots,B_n\}\) が \(\Omega\) の有限分割で,
\[
\mathcal G = \sigma(B_1,\dots,B_n)
\]
とする。このとき,可積分な \(X\) に対して
\[
E[X\mid \mathcal G]
=
\sum_{i=1}^n c_i 1_{B_i},
\qquad
c_i=
\begin{cases}
\dfrac{E[X1_{B_i}]}{P(B_i)} & (P(B_i)>0),\\[1em]
0 & (P(B_i)=0)
\end{cases}
\]
が成立する。つまり,\(E[X\mid \mathcal G]\) は各セル \(B_i\) の上で定数であり,その値は「\(B_i\) の上での平均」である。
特に \(A\in\mathcal F\) に対して
\[
P(A\mid \mathcal G)
=
\sum_{i=1}^n d_i 1_{B_i},
\qquad
d_i=
\begin{cases}
\dfrac{P(A\cap B_i)}{P(B_i)} & (P(B_i)>0),\\[1em]
0 & (P(B_i)=0)
\end{cases}
\]
が成り立つ。すなわち,条件付き確率も各セル上で一定になり,その値はセルごとの条件付き確率になる。
証明
\[
Y := \sum_{i=1}^n c_i 1_{B_i}
\]
とおく。\(Y\) は各 \(B_i\) 上で一定だから,明らかに \(\mathcal G\)-可測である。
あとは,任意の \(B\in\mathcal G\) に対して \(E[X1_B]=E[Y1_B]\) を示せばよい。
\(\mathcal G\) は有限分割 \(\{B_i\}\) が生成する \(\sigma\)-加法族だから,任意の \(B\in\mathcal G\) はある添字集合 \(I_B\subseteq\{1,\dots,n\}\) を使って
\[
B = \bigcup_{i\in I_B} B_i
\]
と書ける。したがって
\[
\begin{aligned}
E[Y1_B]
&=
\sum_{i=1}^n c_i P(B_i\cap B) \\
&=
\sum_{i\in I_B} c_i P(B_i) \\
&=
\sum_{i\in I_B} E[X1_{B_i}] \\
&=
E\left[X\sum_{i\in I_B}1_{B_i}\right]
=
E[X1_B].
\end{aligned}
\]
以上より \(Y\) は条件付き期待値の定義を満たす。最後の条件付き確率の式は \(X=1_A\) とおけば従う。\(\square\)
この命題は,条件付き期待値が「部分集団ごとの平均」として理解できる場合を正確に言い表している。
情報 \(\mathcal G\) が「どのセル \(B_i\) に入ったか」だけを教えてくれるなら,最良の予測は「そのセルの中での平均」を返すことになる。
特に,一つの事象 \(B\) に条件をつける場合
\(0<P(B)<1\) として,
\[
\mathcal G = \sigma(B) = \{\emptyset, B, B^c, \Omega\}
\]
とすると,上の命題から
\[
E[X\mid \sigma(B)] = E[X\mid B]1_B + E[X\mid B^c]1_{B^c}
\]
が従う。さらに,\(A\in\mathcal F\) に対して
\[
P(A\mid \sigma(B)) = P(A\mid B)1_B + P(A\mid B^c)1_{B^c}
\]
となる。
つまり,初等確率で習う
\[
P(A\mid B)=\frac{P(A\cap B)}{P(B)}
\]
や
\[
E[X\mid B]
=
\sum_x x P(X=x\mid B)
\]
は,条件付き期待値の一般論の中では,「\(\sigma(B)\) というとても粗い情報に条件をつけたときのセル平均」として位置づけられる。
まず見ておくべき極端な例
例 1:\(\mathcal G=\mathcal F\) のとき
このとき \(X\) 自身が \(\mathcal F\)-可測であり,任意の \(B\in\mathcal F\) について
\[
E[X1_B]=E[X1_B]
\]
は自明に成り立つ。したがって
\[
E[X\mid \mathcal F]=X \qquad a.s.
\]
である。全部の情報が見えているなら,予測すべき対象そのものがわかっている,というだけの話である。
例 2:\(\mathcal G=\{\emptyset,\Omega\}\) のとき
このとき \(\mathcal G\)-可測な確率変数は定数しかない。定数 \(E[X]\) は明らかに \(\mathcal G\)-可測であり,
- \(B=\emptyset\) では \(E[X1_B]=0=E[E[X]1_B]\)
- \(B=\Omega\) では \(E[X1_B]=E[X]=E[E[X]1_B]\)
だから
\[
E[X\mid \{\emptyset,\Omega\}] = E[X] \qquad a.s.
\]
となる。何の情報もなければ,全体平均を返すしかない。
この2つの例は極端だが,本質をよく表している。
- 情報が最大なら,条件付き期待値は \(X\) そのもの
- 情報が最小なら,条件付き期待値は定数 \(E[X]\)
条件付き期待値は,この2つの間で「持っている情報の量」に応じて変わる予測子だと理解するとよい。
条件付き期待値の基本性質
以下では,\(X,Y\) は可積分な確率変数,\(\mathcal H\subseteq \mathcal G\subseteq \mathcal F\) は部分 \(\sigma\)-加法族とする。
命題(条件付き期待値の基本性質)
- (線形性)任意の \(a,b\in\mathbb R\) に対して \[
E[aX+bY\mid \mathcal G]
=
aE[X\mid \mathcal G]+bE[Y\mid \mathcal G]
\qquad a.s.
\]
- (単調性)\(X\le Y\) a.s. なら \[
E[X\mid \mathcal G]\le E[Y\mid \mathcal G]
\qquad a.s.
\] 特に \(X\ge 0\) a.s. なら \(E[X\mid \mathcal G]\ge 0\) a.s. である。
- (わかっているものは外に出せる)\(Z\) が \(\mathcal G\)-可測で,\(ZX\) が可積分なら \[
E[ZX\mid \mathcal G] = Z E[X\mid \mathcal G] \qquad a.s.
\] 特に,\(X\) 自身が \(\mathcal G\)-可測なら \[
E[X\mid \mathcal G] = X \qquad a.s.
\]
- (反復期待値・tower property) \[
E[E[X\mid \mathcal G]\mid \mathcal H] = E[X\mid \mathcal H] \qquad a.s.
\] 特に,\(\mathcal H=\{\emptyset,\Omega\}\) とすると \[
E[E[X\mid \mathcal G]] = E[X].
\]
- (独立なら平均に潰れる)\(\sigma(X)\) と \(\mathcal G\) が独立なら \[
E[X\mid \mathcal G]=E[X] \qquad a.s.
\] したがって,\(f(X)\) が可積分なら \[
E[f(X)\mid \mathcal G]=E[f(X)] \qquad a.s.
\]
- (Jensen の不等式)\(\varphi\) が凸関数で,\(\varphi(X)\) が可積分なら \[
\varphi(E[X\mid\mathcal G])
\le
E[\varphi(X)\mid\mathcal G]
\qquad a.s.
\] 特に \(p\ge 1\) について \[
|E[X\mid\mathcal G]|^p
\le
E[|X|^p\mid\mathcal G]
\qquad a.s.
\] が成り立つ。
証明
(1) 右辺を
\[
U := aE[X\mid \mathcal G]+bE[Y\mid \mathcal G]
\]
とおく。\(U\) は \(\mathcal G\)-可測である。さらに任意の \(B\in\mathcal G\) に対して
\[
\begin{aligned}
E[U1_B]
&=
aE[E[X\mid \mathcal G]1_B]+bE[E[Y\mid \mathcal G]1_B] \\
&=
aE[X1_B]+bE[Y1_B]
=
E[(aX+bY)1_B].
\end{aligned}
\]
よって \(U\) は \(E[aX+bY\mid \mathcal G]\) の定義を満たす。
(2) \(Y-X\ge 0\) なので,\(E[Y-X\mid\mathcal G]\ge0\) を示せばよい。そこで \(V:=E[Y-X\mid\mathcal G]\) とし,\(B=\{V<0\}\in\mathcal G\) を考える。定義より
\[
E[V1_B]=E[(Y-X)1_B]\ge 0
\]
である。一方で \(V1_B\le 0\) だから,両方を満たすには \(V1_B=0\) a.s. でなければならない。したがって \(P(B)=0\),すなわち \(V\ge 0\) a.s. である。
(3) まず \(Z=1_A\)(\(A\in\mathcal G\))の場合を示す。このとき \(1_AE[X\mid \mathcal G]\) は \(\mathcal G\)-可測であり,任意の \(B\in\mathcal G\) に対して
\[
E[(1_AX)1_B]
=
E[X1_{A\cap B}]
=
E[E[X\mid \mathcal G]1_{A\cap B}]
=
E[(1_AE[X\mid \mathcal G])1_B].
\]
したがって
\[
E[1_A X\mid \mathcal G]=1_AE[X\mid \mathcal G].
\]
次に \(Z\) が非負の \(\mathcal G\)-可測単純関数なら,線形性より同じ式が成り立つ。一般の \(\mathcal G\)-可測 \(Z\) については,単純関数近似と正負部分への分解を使えば
\[
E[ZX\mid \mathcal G]=ZE[X\mid \mathcal G]
\]
を得る。
特に \(X\) が \(\mathcal G\)-可測なら,\(X\) 自身が条件付き期待値の定義を満たすので \(E[X\mid\mathcal G]=X\) が従う。
(4) 左辺を
\[
U := E[E[X\mid \mathcal G]\mid \mathcal H]
\]
とおく。\(U\) は \(\mathcal H\)-可測である。任意の \(B\in\mathcal H\) に対して,\(\mathcal H\subseteq \mathcal G\) より \(B\in\mathcal G\) でもあるから
\[
E[U1_B]
=
E[E[X\mid \mathcal G]1_B]
=
E[X1_B].
\]
よって \(U\) は \(E[X\mid \mathcal H]\) の定義を満たす。特に \(\mathcal H=\{\emptyset,\Omega\}\) とすれば \(E[E[X\mid \mathcal G]]=E[X]\) が従う。
(5) 定数 \(E[X]\) は \(\mathcal G\)-可測である。任意の \(B\in\mathcal G\) に対して,\(\sigma(X)\) と \(\mathcal G\) の独立性から
\[
E[X1_B]=E[X]P(B)=E[E[X]1_B].
\]
したがって \(E[X\mid \mathcal G]=E[X]\) a.s. である。\(f(X)\) に対する主張も同様である。
(6) Jensen の不等式はここでは証明を省くが,直感は普通の Jensen と同じである。条件付き期待値は「条件をつけた平均」なので,凸関数を平均の外に出すと小さくなる。\(\square\)
上の(3)と(4)を合わせると,計量経済学で最も頻繁に使う事実がすぐ出る。
系(条件付き期待値から引いた残差は,条件づけた情報と直交する)
\[
U := X-E[X\mid \mathcal G]
\]
とおく。\(Z\) が \(\mathcal G\)-可測で \(UZ\) が可積分なら
\[
E[UZ]=0.
\]
特に \(A\in\mathcal G\) に対して
\[
E[U1_A]=0
\]
である。すなわち,条件付き期待値から引いた残差は,\(\mathcal G\) によって観測できるどんな対象とも平均的に無相関になる。
証明
\(Z\) は \(\mathcal G\)-可測だから,(3)と(4)より
\[
\begin{aligned}
E[UZ]
&=
E\bigl(E[UZ\mid \mathcal G]\bigr) \\
&=
E\bigl(ZE[U\mid \mathcal G]\bigr)
=
0.
\end{aligned}
\]
最後の等号は
\[
E[U\mid \mathcal G]
=
E[X\mid \mathcal G]-E[E[X\mid \mathcal G]\mid \mathcal G]
=
0
\]
から従う。\(\square\)
この「残差は観測可能な情報と直交する」という性質が,そのまま \(L^2\) の射影の話になる。
\(L^2\) 空間と直交射影
ここからが計量経済学的には最も重要である。二乗誤差を考えたいので,今度は \(X\in L^2\),つまり
\[
E[X^2] < \infty
\]
を仮定する。
定義(\(L^2\) 空間)
\(L^2(\mathcal F)\) とは,二乗可積分な実数値確率変数全体を \(a.s.\) に等しいもの同士で同一視した集合である。
この集合には内積
\[
\langle X,Y\rangle := E[XY]
\]
とノルム
\[
\|X\|_2 := \sqrt{E[X^2]}
\]
が入る。\(L^2(\mathcal F)\) はこの内積について Hilbert 空間である。つまり,内積をもつ完備な線形空間である。
いま,情報 \(\mathcal G\) によって観測できる二乗可積分な確率変数全体を
\[
L^2(\mathcal G)
:=
\{Z\in L^2(\mathcal F): Z \text{ は } \mathcal G\text{-可測}\}
\]
と書く。これは \(L^2(\mathcal F)\) の線形部分空間である。しかも閉部分空間である。
補題(\(L^2(\mathcal G)\) は閉部分空間)
\(L^2(\mathcal G)\) は \(L^2(\mathcal F)\) の閉線形部分空間である。
証明
線形部分空間であることは明らかである。閉性だけ確認する。
\(Z_n\in L^2(\mathcal G)\) かつ \(Z_n\to Z\) in \(L^2\) とする。\(L^2\) 収束から,ある部分列 \(Z_{n_j}\) が存在して \(Z_{n_j}\to Z\) a.s. となる。各 \(Z_{n_j}\) は \(\mathcal G\)-可測であり,可測関数列の点ごとの極限も \(\mathcal G\)-可測である。したがって \(Z\) は \(a.s.\) の修正を除いて \(\mathcal G\)-可測である。ゆえに \(Z\in L^2(\mathcal G)\) である。\(\square\)
閉部分空間が出てきたので,Hilbert 空間の射影定理が使える。
定理(Hilbert 空間の射影定理)
\(H\) を Hilbert 空間,\(M\subset H\) を閉線形部分空間とする。任意の \(x\in H\) に対して,ただ一つの \(m^\ast\in M\) が存在して
\[
\|x-m^\ast\|
=
\inf_{m\in M}\|x-m\|
\]
を満たす。さらに,この \(m^\ast\) は
\[
\langle x-m^\ast,m\rangle=0
\qquad
(\forall m\in M)
\]
を満たす唯一の元である。これを \(x\) の \(M\) への直交射影という。
この射影定理を \(H=L^2(\mathcal F)\),\(M=L^2(\mathcal G)\) に適用できる。結論を先に言うと,\(X\) を \(L^2(\mathcal G)\) へ直交射影したものが条件付き期待値である。
定理(条件付き期待値は \(L^2(\mathcal G)\) への直交射影)
\(X\in L^2(\mathcal F)\) とし,
\[
Y := E[X\mid \mathcal G]
\]
とおく。このとき次が成り立つ。
- \(Y\in L^2(\mathcal G)\).
- 任意の \(Z\in L^2(\mathcal G)\) に対して \[
E[(X-Y)Z]=0.
\] すなわち,残差 \(X-Y\) は \(L^2(\mathcal G)\) のすべての元と直交する。
- 任意の \(Z\in L^2(\mathcal G)\) に対して \[
\|X-Z\|_2^2 = \|X-Y\|_2^2 + \|Y-Z\|_2^2.
\]
したがって
\[
E[X\mid \mathcal G]
=
\operatorname*{argmin}_{Z\in L^2(\mathcal G)} E[(X-Z)^2].
\]
つまり,条件付き期待値は「\(\mathcal G\) の情報だけを使って作れる確率変数の中で,\(X\) に最も近いもの」である。
証明
(1) まず \(Y\) は定義から \(\mathcal G\)-可測である。二乗可積分性を示すため,
\[
Y_n := Y1_{\{|Y|\le n\}}
\]
とおく。\(Y_n\) は有界かつ \(\mathcal G\)-可測だから,基本性質より
\[
E[XY_n]
=
E\bigl(E[XY_n\mid \mathcal G]\bigr)
=
E\bigl(Y_nE[X\mid \mathcal G]\bigr)
=
E[YY_n].
\]
したがって Cauchy–Schwarz により
\[
E[Y_n^2]
=
E[YY_n]
=
E[XY_n]
\le
\|X\|_2\|Y_n\|_2.
\]
よって \(\|Y_n\|_2\le \|X\|_2\) である。\(n\to\infty\) とすると \(Y_n^2\uparrow Y^2\) だから,単調収束定理より
\[
E[Y^2] = \lim_{n\to\infty}E[Y_n^2] \le \|X\|_2^2 < \infty.
\]
ゆえに \(Y\in L^2(\mathcal G)\) である。
(2) \(Z\in L^2(\mathcal G)\) とする。\(X-Y\in L^2\) なので,Cauchy–Schwarz により \((X-Y)Z\) は可積分である。しかも \(Z\) は \(\mathcal G\)-可測だから,
\[
E[(X-Y)Z]
=
E\bigl(E[(X-Y)Z\mid \mathcal G]\bigr)
=
E\bigl(ZE[X-Y\mid \mathcal G]\bigr)
=
0.
\]
すなわち,残差 \(X-Y\) は \(L^2(\mathcal G)\) の任意の元に直交する。
(3) \(Y-Z\in L^2(\mathcal G)\) なので,(2)から
\[
E[(X-Y)(Y-Z)]=0.
\]
したがって
\[
\begin{aligned}
\|X-Z\|_2^2
&= E\bigl[((X-Y)+(Y-Z))^2\bigr] \\
&= E[(X-Y)^2] + 2E[(X-Y)(Y-Z)] + E[(Y-Z)^2] \\
&= \|X-Y\|_2^2 + \|Y-Z\|_2^2.
\end{aligned}
\]
これがピタゴラス分解である。右辺第2項は常に非負だから,\(\|X-Z\|_2^2\) は \(Z=Y\) のとき最小になる。しかも最小化子は \(a.s.\) の意味で一意である。\(\square\)
幾何学的な読み方
この定理は,ふつうの線形代数の「直交射影」とまったく同じ構造をもっている。
- 空間全体:\(L^2(\mathcal F)\)
- 射影先の部分空間:\(L^2(\mathcal G)\)
- ベクトル:確率変数
- 内積:\(E[XY]\)
- 射影された点:\(E[X\mid \mathcal G]\)
- 垂線成分:\(X-E[X\mid \mathcal G]\)
つまり,
\[
X = E[X\mid \mathcal G] + \{X-E[X\mid \mathcal G]\}
\]
は
- 予測可能部分 \(E[X\mid \mathcal G]\)
- 予測不可能部分 \(X-E[X\mid \mathcal G]\)
への直交分解になっている。
最良予測子としての条件付き期待値
この射影定理を予測の言葉に言い換えると,条件付き期待値は二乗誤差の意味で最良の予測子である。
定理(二乗誤差の意味での最良予測子)
\(Y\in L^2\),\(W\) を任意の確率変数とする。このとき
\[
m(W):=E[Y\mid W]
\]
は,\(W\) の可測関数 \(g(W)\) の中で
\[
E[(Y-g(W))^2]
\]
を最小化する。
より正確には,任意の二乗可積分な可測関数 \(g\) に対して
\[
E[(Y-g(W))^2]
=
E[(Y-m(W))^2] + E[(m(W)-g(W))^2]
\]
が成り立つ。
証明
\(\mathcal G=\sigma(W)\) とおけば,\(g(W)\) は \(L^2(\mathcal G)\) の元である。したがって直交射影のピタゴラス分解をそのまま使えばよい。\(\square\)
この定理は,計量経済学では極めて重要である。なぜなら,母集団レベルでは
\[
Y = E[Y\mid W] + u,
\qquad E[u\mid W]=0
\]
という分解がいつでもできるからである。ここで
\[
u := Y-E[Y\mid W]
\]
は「\(W\) を知っていても予測できない成分」であり,任意の二乗可積分な \(g(W)\) に対して
\[
E[u\,g(W)] = 0
\]
を満たす。
これは,単に \(u\) と \(W\) が無相関というよりずっと強い。\(u\) は \(W\) のあらゆる可測関数と直交するのである。
OLS と best linear predictor
ここまでの話は「予測子として許されるもの」を \(W\) のすべての可測関数に広げていた。
一方,線形回帰ではその候補を線形関数に制限している。
説明変数ベクトルを \(W\in\mathbb R^k\) とし,定数項を含めるために
\[
R:=(1,W')'
\]
と書く。線形予測子全体を
\[
\mathcal L(W)
:=
\{R'\beta:\beta\in\mathbb R^{k+1}\}
\subset L^2(\sigma(W))
\]
とおく。これは \(L^2(\mathcal F)\) の有限次元線形部分空間である。
母集団 OLS 係数は
\[
\beta^\ast
\in
\operatorname*{argmin}_{\beta\in\mathbb R^{k+1}}
E[(Y-R'\beta)^2]
\]
として定義される。対応する予測値
\[
Y_L:=R'\beta^\ast
\]
は,\(Y\) を \(\mathcal L(W)\) に直交射影したものである。したがって,任意の \(\beta\) に対して
\[
E[(Y-R'\beta)^2]
=
E[(Y-Y_L)^2]+E[(Y_L-R'\beta)^2]
\]
が成り立つ。これが OLS が best linear predictor と呼ばれる理由である。OLS は,線形予測子の中で二乗誤差を最小にする。
内積の直交条件として書けば,
\[
E[R(Y-R'\beta^\ast)]=0
\]
である。これは母集団の正規方程式である。もし
\[
Q:=E[RR']
\]
が正則なら,
\[
\beta^\ast
=
Q^{-1}E[RY]
\]
と明示的に書ける。
ここで条件付き期待値との関係をもう一段はっきりさせよう。\(m(W):=E[Y\mid W]\) とする。任意の \(\beta\) について,直交分解より
\[
E[(Y-R'\beta)^2]
=
E[(Y-m(W))^2]+E[(m(W)-R'\beta)^2].
\]
右辺第1項は \(\beta\) に依存しない。したがって
\[
\beta^\ast
\in
\operatorname*{argmin}_{\beta\in\mathbb R^{k+1}}
E[(m(W)-R'\beta)^2].
\]
つまり,母集団 OLS は \(Y\) 自体を線形近似しているとも言えるが,より本質的には,条件付き期待値関数 \(m(W)=E[Y\mid W]\) を最もよく線形近似していると言える。
ここで重要なのは次の違いである。
- \(E[Y\mid W]\) は すべての可測関数を許したときの最良予測子
- OLS の \(R'\beta^\ast\) は 線形関数だけを許したときの最良予測子
もし本当に
\[
E[Y\mid W] = R'\beta_0
\]
が成り立つなら,条件付き期待値と線形射影は一致し,
\[
\beta^\ast=\beta_0
\]
となる。これが線形回帰モデルがうまく働く理想的な状況である。
しかし一般には \(E[Y\mid W]\) は非線形かもしれない。そのとき OLS が返すのは真の条件付き期待値そのものではなく,あくまで条件付き期待値関数の最良線形近似である。
この区別は計量経済学で非常に重要である。
- 非線形な条件付き平均を線形モデルで近似しているだけなのか
- それとも本当に条件付き平均が線形なのか
で,推定量の意味も解釈も変わるからである。
Rによるシミュレーション:射影の感覚をつかむ
最後に,条件付き期待値を「情報に応じた平均」かつ「射影」として感じるために,簡単なシミュレーションを2つやってみる。
シミュレーション1:粗い情報 \(\mathcal G\) への射影は区間ごとの平均
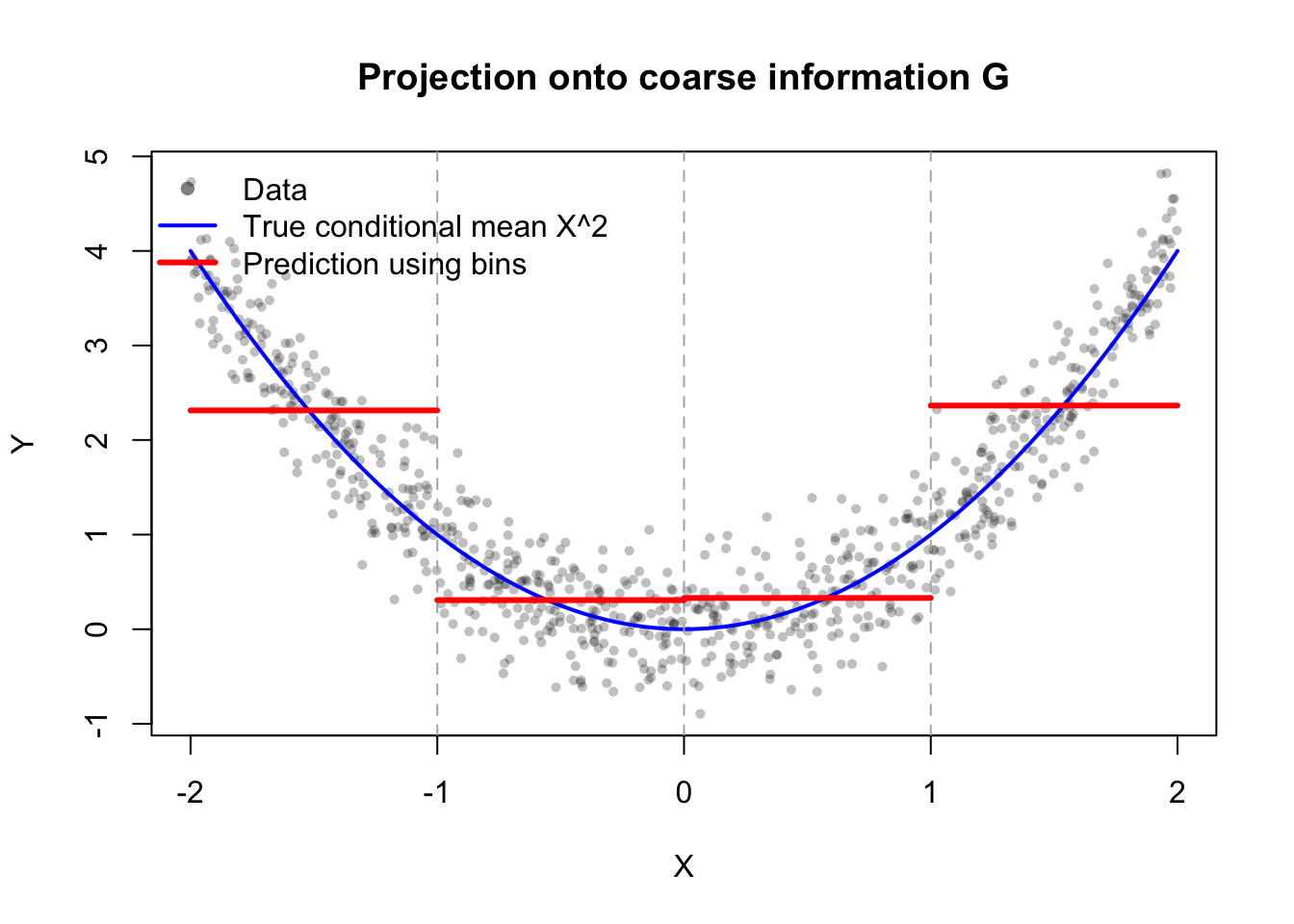
まず
\[
Y = X^2 + \varepsilon,
\qquad X\sim \mathrm{Unif}[-2,2],
\qquad \varepsilon\sim N(0,0.4^2)
\]
を考える。さらに \(X\) と \(\varepsilon\) は独立とする。このとき
\[
E[Y\mid X]=X^2
\]
である。
一方で,いま持っている情報が「\(X\) がどの区間に入ったか」だけだったとする。たとえば
\[
[-2,-1],\ (-1,0],\ (0,1],\ (1,2]
\]
の4区間のどこに入ったかしかわからないとき,\(\mathcal G\) はその分割が生成する \(\sigma\)-加法族である。
このとき \(E[Y\mid \mathcal G]\) は,各区間ごとの平均を返す段差関数になるはずである。
set.seed(123)
n <- 800
x <- runif(n, min = -2, max = 2)
eps <- rnorm(n, mean = 0, sd = 0.4)
y <- x^2 + eps
breaks <- c(-2, -1, 0, 1, 2)
bin <- cut(x, breaks = breaks, include.lowest = TRUE)
bin_mean <- tapply(y, bin, mean)
y_hat_G <- bin_mean[bin]
plot(x, y,
pch = 16, cex = 0.7, col = rgb(0, 0, 0, 0.25),
xlab = "X", ylab = "Y",
main = "Projection onto coarse information G")
curve(x^2, from = -2, to = 2, add = TRUE, lwd = 2, col = "blue")
abline(v = c(-1, 0, 1), lty = 2, col = "gray70")
for (j in 1:(length(breaks) - 1)) {
segments(breaks[j], bin_mean[j], breaks[j + 1], bin_mean[j],
col = "red", lwd = 3)
}
legend("topleft",
legend = c("Data", "True conditional mean X^2", "Prediction using bins"),
col = c(rgb(0, 0, 0, 0.5), "blue", "red"),
pch = c(16, NA, NA), lty = c(NA, 1, 1), lwd = c(NA, 2, 3),
bty = "n")
青い曲線が真の条件付き期待値 \(E[Y\mid X]=X^2\),赤い段差関数が「区間だけ知っている」ときの条件付き期待値 \(E[Y\mid \mathcal G]\) の標本版である。
情報が粗くなると,射影先の空間 \(L^2(\mathcal G)\) も小さくなるので,予測子はより粗い形になる。
次の出力は,「情報が増えるほど二乗誤差が下がる」ことを直感的に見せるものである。
mse_global <- mean((y - mean(y))^2)
mse_G <- mean((y - y_hat_G)^2)
mse_true <- mean((y - x^2)^2)
round(c(
"Global mean only" = mse_global,
"Coarse information G" = mse_G,
"True conditional mean E[Y|X]" = mse_true
), 4)
Global mean only Coarse information G
1.6118 0.5898
True conditional mean E[Y|X]
0.1631
round(tapply(y - y_hat_G, bin, mean), 10)
[-2,-1] (-1,0] (0,1] (1,2]
0 0 0 0
最後の行で,各区間ごとの残差平均がほぼ \(0\) になっていることも確認できる。これは母集団での関係
\[
E[Y-E[Y\mid \mathcal G]\mid \mathcal G]=0
\]
の標本版であり,「射影誤差は射影先の情報と直交する」という性質の離散版である。
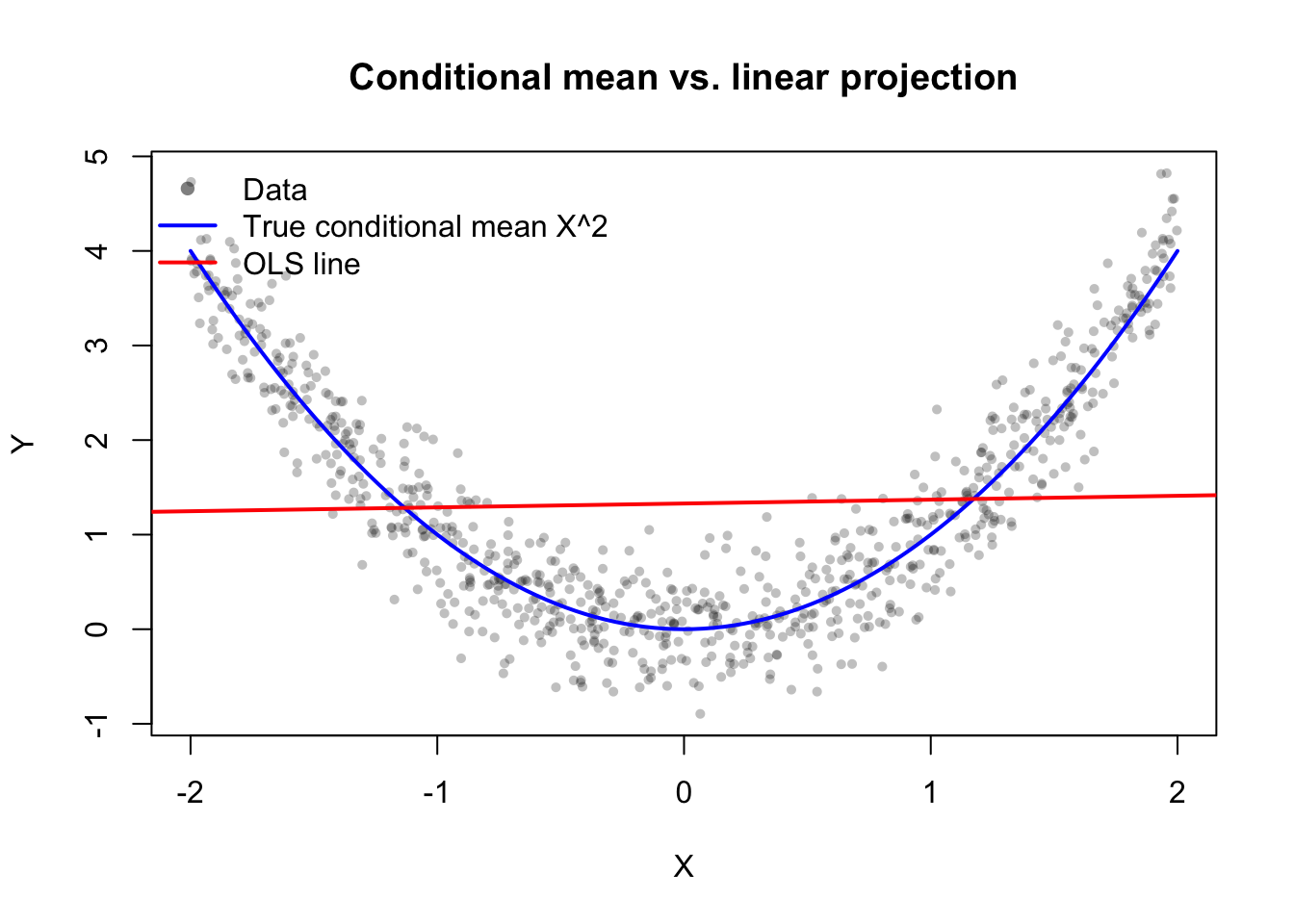
シミュレーション2:条件付き期待値と線形射影は一般には違う
同じデータに対して,今度は最小二乗の直線を引いてみる。
すると,真の条件付き期待値 \(X^2\) は非線形なので,OLS の直線とは一致しないはずである。
fit_lin <- lm(y ~ x)
plot(x, y,
pch = 16, cex = 0.7, col = rgb(0, 0, 0, 0.25),
xlab = "X", ylab = "Y",
main = "Conditional mean vs. linear projection")
curve(x^2, from = -2, to = 2, add = TRUE, lwd = 2, col = "blue")
abline(fit_lin, col = "red", lwd = 2)
legend("topleft",
legend = c("Data", "True conditional mean X^2", "OLS line"),
col = c(rgb(0, 0, 0, 0.5), "blue", "red"),
pch = c(16, NA, NA), lty = c(NA, 1, 1), lwd = c(NA, 2, 2),
bty = "n")
(Intercept) x
1.32924149 0.04076354
round(c(
"Mean residual" = mean(resid(fit_lin)),
"Mean X times residual" = mean(x * resid(fit_lin))
), 10)
Mean residual Mean X times residual
0 0
赤い直線は「\(1\) と \(X\) の線形結合」という小さな部分空間への射影であり,青い曲線 \(E[Y\mid X]=X^2\) とは一般には違う。
それでも OLS 残差が定数項と \(X\) に直交していることは,最後の数値から確認できる。これは線形代数でいう正規方程式の確率論版である。
この図から読み取るべきメッセージは次の通りである。
- 条件付き期待値は「\(X\) のすべての可測関数」を許したときの最良予測子
- OLS は「線形関数だけ」を許したときの最良予測子
- 両者が一致するのは,条件付き平均が本当に線形なときだけ
まとめ
条件付き期待値 \(E[X\mid \mathcal G]\) は,初等確率で習う「ある事象に条件をつけた平均」を大きく一般化した概念である。
- 条件をつける対象は,単なる事象ではなく情報を表す \(\sigma\)-加法族 \(\mathcal G\)
- 条件付き期待値は,一つの数ではなく \(\mathcal G\)-可測な確率変数
- 存在はラドン–ニコディムの定理から従う
- 有限分割の場合には,各セルごとの平均として素朴な定義と一致
- 基本性質として線形性,単調性,tower property,独立性との関係などをもつ
- \(L^2\) では,\(E[X\mid \mathcal G]\) は \(L^2(\mathcal G)\) への直交射影であり,二乗誤差の意味での最良予測子
- OLS は,予測子を線形関数に制限したときの最良予測子であり,条件付き期待値関数の best linear predictor である
計量経済学で回帰分析が重要なのは,まさにこの最後の点のためである。
回帰とは,本質的には「利用可能な情報に基づいて,二乗誤差の意味で最良の予測を作ること」なのである。
線形回帰はその中でも,予測子のクラスを線形関数に制限した特別な場合にすぎない。