予備知識:解析の言葉
極値推定の議論では、解析の言葉が頻繁に出てくる。ただし、この章で必要なのは「有限個のパラメタを推定する」ための有限次元の直観で十分である。
上限 sup
\(\sup\) は 上限 と読む。集合 \(A\) のすべての要素以上である数を上界といい、その中で最小のものを \(\sup A\) と書く。
例えば \[
\sup [0,1]=1,
\qquad
\sup (0,1)=1
\] である。\([0,1]\) では 1 が集合に入っているので最大値でもある。一方、\((0,1)\) では 1 は集合に入っていないので最大値ではないが、いくらでも 1 に近づけるので上限は 1 である。
極値推定で \[
\sup_{\theta\in\Theta} Q_n(\theta)
\] と書くときは、「パラメタ \(\theta\) を動かしたときに達成できる目的関数の最良値」を表している。最大値が実際に存在するときは \(\max_{\theta\in\Theta} Q_n(\theta)\) と同じだが、存在するかどうかをまだ仮定したくないので \(\sup\) を使う。
コンパクト
有限次元、つまり \(\Theta\subseteq\mathbb R^p\) の場合には、コンパクト はほぼ
閉じていて、かつ有界である
と思ってよい。
閉じているとは、端点や境界を含むということである。有界であるとは、無限遠まで広がっていないということである。例えば \([0,1]\) や閉球 \[
\{\theta\in\mathbb R^p:\|\theta\|\le C\}
\] はコンパクトである。一方、\((0,1)\) は端点を含まないのでコンパクトではなく、\(\mathbb R\) は無限に広がるのでコンパクトではない。
推定論でコンパクト性を仮定する理由は、パラメタが「端点の外」や「無限遠」に逃げる可能性を排除するためである。本章では有限個のパラメタしか扱わないので、この有限次元の理解で十分である。
連続関数
関数 \(Q(\theta)\) が連続であるとは、\(\theta\) を少しだけ動かすと \(Q(\theta)\) も少しだけしか変わらない、ということである。
多項式、指数関数、対数関数、そしてそれらを足したり掛けたり合成したりして作った関数は、多くの場合連続である。一方、 \[
1\{\theta\ge 0\}
\] のような指示関数は、\(\theta=0\) で急に値が変わるので連続ではない。
極値推定では、\(Q\) が連続であると、目的関数の山や谷が突然切れることがない。この性質が、最大化点の存在や clean maximum の確認に使われる。
Weierstrass の定理
Weierstrass の定理は、極値推定で何度も使う基本事実である。
\(\Theta\subseteq\mathbb R^p\) がコンパクトで、\(Q:\Theta\to\mathbb R\) が連続なら、\(Q\) は \(\Theta\) 上で最大値と最小値をとる。
つまり、単に \[
\sup_{\theta\in\Theta}Q(\theta)
\] という上限があるだけでなく、それを実際に達成する点 \(\theta^*\) が存在して \[
Q(\theta^*)=\sup_{\theta\in\Theta}Q(\theta)
\] と書ける。
この章では、\(\theta_0\) から一定距離以上離れた集合上で \(Q\) の最大値をとる点が存在することを使い、その点では識別により \(Q(\theta_0)\) より目的関数が低い、と示す。
収束と一様収束
数列 \(a_n\) が \(a\) に収束するとは、\(n\) が大きくなると \(a_n\) が \(a\) に近づくことである。確率変数 \(Z_n\) が \(Z\) に確率収束するとは、任意の \(\varepsilon>0\) について \[
P(|Z_n-Z|>\varepsilon)\to 0
\] となることである。
関数列 \(Q_n(\theta)\) の場合には、2 種類の収束を区別する必要がある。
点ごとの収束は、各 \(\theta\) を固定すると \[
Q_n(\theta)\to Q(\theta)
\] となることである。
一様収束は、\(\theta\) 全体で見た最大の誤差が小さくなることである。 \[
\sup_{\theta\in\Theta}|Q_n(\theta)-Q(\theta)|\to 0.
\]
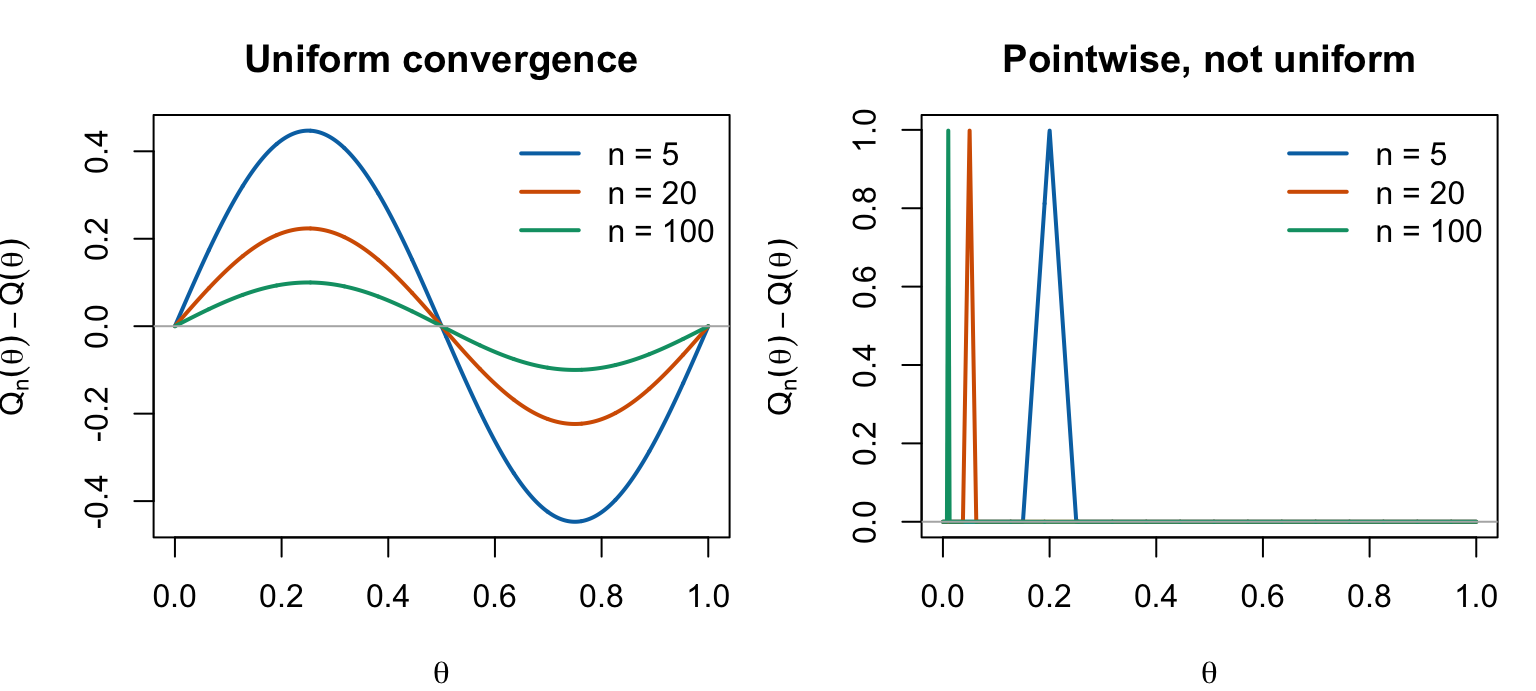
図式的には、点ごとの収束は「どの点も、個別に見れば近づく」、一様収束は「同じ \(n\) で、曲線全体がまとめて近づく」という違いである。
\[
\begin{array}{c}
\text{点ごとの収束:}\quad
\theta\text{ を固定してから }n\to\infty \\
\text{一様収束:}\quad
\theta\text{ を全部動かしても最大誤差が小さい}
\end{array}
\]
次の R コードでは、誤差 \[
e_n(\theta)=Q_n(\theta)-Q(\theta)
\] を 2 通りに作って、この違いを直接描いている。どちらも極限関数は \(0\) である。左側では誤差の曲線全体が \(0\) に押しつぶされていく。右側では、各固定点から見るとスパイクはいつか通り過ぎるので \(0\) に収束するが、どの \(n\) でも高さ 1 のスパイクが残っている。
theta <- seq(0, 1, length.out = 2000)
n_grid <- c(5, 20, 100)
# 一様収束する誤差: 曲線全体の振幅が小さくなる。
uniform_error <- function(theta, n) {
sin(2 * pi * theta) / sqrt(n)
}
# 点ごとには 0 に収束するが、一様には収束しない誤差。
# 高さ 1 の三角形スパイクが theta = 1/n の位置に動いていく。
moving_spike <- function(theta, n) {
pmax(0, 1 - 4 * n * abs(theta - 1 / n))
}
cols <- c("#0072B2", "#D55E00", "#009E73")
old_par <- par(mfrow = c(1, 2), mar = c(4, 4, 3, 1))
matplot(
theta,
sapply(n_grid, function(n) uniform_error(theta, n)),
type = "l", lty = 1, lwd = 2, col = cols,
xlab = expression(theta),
ylab = expression(Q[n](theta) - Q(theta)),
main = "Uniform convergence"
)
abline(h = 0, col = "gray70")
legend("topright", legend = paste("n =", n_grid),
col = cols, lty = 1, lwd = 2, bty = "n")
matplot(
theta,
sapply(n_grid, function(n) moving_spike(theta, n)),
type = "l", lty = 1, lwd = 2, col = cols,
xlab = expression(theta),
ylab = expression(Q[n](theta) - Q(theta)),
main = "Pointwise, not uniform"
)
abline(h = 0, col = "gray70")
legend("topright", legend = paste("n =", n_grid),
col = cols, lty = 1, lwd = 2, bty = "n")
par(old_par)
この右側の例は、 \[
e_n(\theta)=\max\{0,1-4n|\theta-1/n|\}
\] という誤差を描いている。このスパイクが正になる範囲は \[
\left|\theta-\frac1n\right|<\frac{1}{4n},
\qquad
\text{つまり}\qquad
\theta\in\left(\frac{3}{4n},\frac{5}{4n}\right)
\] である。したがって、任意の固定された \(\theta\in[0,1]\) については \(e_n(\theta)\to0\) である。実際、\(\theta>0\) なら、十分大きな \(n\) ではスパイクは \(\theta\) よりずっと左側に移動している。また \(\theta=0\) では、各 \(n\) について \[
e_n(0)=\max\{0,1-4n|0-1/n|\}=\max\{0,-3\}=0
\] である。
しかし、一様収束はしない。なぜなら、各 \(n\) について \(\theta=1/n\) を選べば \[
e_n(1/n)=1
\] であり、 \[
\sup_{\theta\in[0,1]}|e_n(\theta)|=1
\] のままだからである。つまり、「どの固定点でも近づく」と「どこを見ても同時に近い」は別の条件である。
n_check <- c(5, 20, 100, 500, 2000)
sup_errors <- data.frame(
n = n_check,
uniform_error = 1 / sqrt(n_check),
moving_spike_error = rep(1, length(n_check))
)
knitr::kable(
sup_errors,
digits = 3,
col.names = c("n", "一様収束する例の sup 誤差", "スパイク例の sup 誤差")
)
極値推定の一致性では、一様収束が重要である。なぜなら、推定量 \(\hat\theta\) 自体が \(Q_n\) を見て動くため、固定された \(\theta\) だけで収束を確認しても足りないからである。
上のスパイク例でいえば、\(\hat\theta\) は固定された点ではない。\(Q_n\) の形を見て、その時々で高い場所を選ぶ。したがって、固定した \(\theta\) では消えているように見えるスパイクでも、最大化問題では \(\hat\theta\) がそのスパイクを追いかけてしまう可能性がある。一様収束は、このような「動き回る見かけの山」が目的関数全体に残っていないことを保証する条件である。
ブラケット数の直観
一様収束を示すには、無限個の関数 \[
\mathcal M=\{m(\cdot;\theta):\theta\in\Theta\}
\] を同時に扱う必要がある。ブラケット数は、この関数族がどれくらい複雑かを測る道具である。
ブラケットとは、関数 \(f\) を上下から挟む 2 本の関数 \(\ell\) と \(u\) の組である。 \[
\ell(x)\le f(x)\le u(x)
\] で、さらに上下の幅の平均 \[
E[u(X)-\ell(X)]
\] が小さいとき、そのブラケットはよい近似になっている。
\[
\begin{array}{c}
u(x)\quad \text{上側の関数} \\
\hline
f(x)\quad \text{挟まれる関数} \\
\hline
\ell(x)\quad \text{下側の関数}
\end{array}
\]
次の図では、簡単な関数族 \[
m(x;\theta)=\sin(2\pi x)+\theta x,
\qquad
\theta\in[0,1]
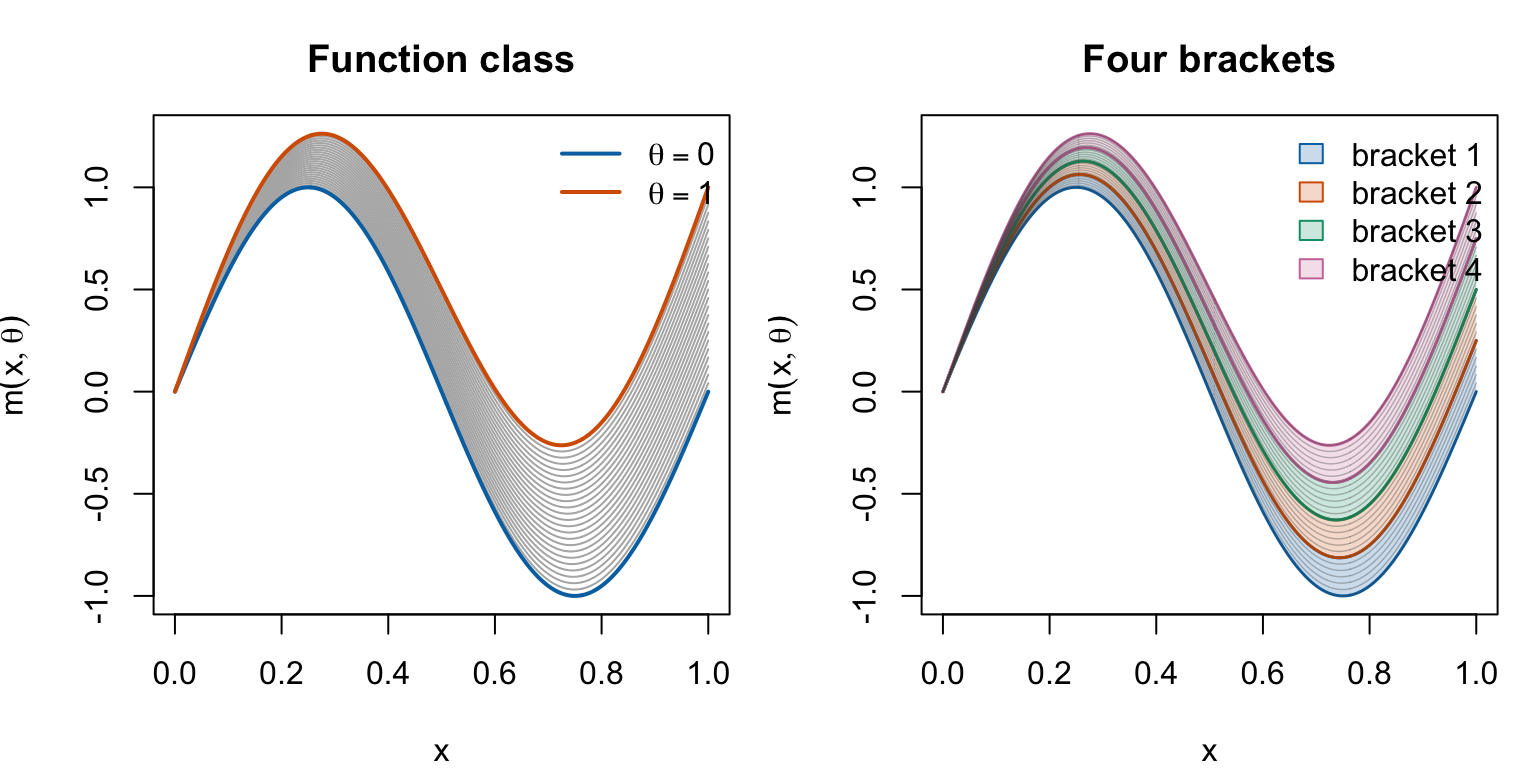
\] を考える。左側の灰色の線は、\(\theta\) を細かく動かして得られるたくさんの関数である。右側では、\(\theta\) の範囲を 4 つに分け、それぞれの区間に入る関数を上下 2 本の線で挟んでいる。
x <- seq(0, 1, length.out = 500)
m_fun <- function(x, theta) {
sin(2 * pi * x) + theta * x
}
theta_many <- seq(0, 1, length.out = 25)
y_many <- sapply(theta_many, function(theta) m_fun(x, theta))
y_lim <- range(y_many)
J <- 4
theta_breaks <- seq(0, 1, length.out = J + 1)
band_cols <- adjustcolor(
c("#0072B2", "#D55E00", "#009E73", "#CC79A7"),
alpha.f = 0.22
)
edge_cols <- c("#0072B2", "#D55E00", "#009E73", "#CC79A7")
old_par <- par(mfrow = c(1, 2), mar = c(4, 4, 3, 1))
matplot(
x, y_many,
type = "l", lty = 1, lwd = 1, col = "gray70",
xlab = "x", ylab = expression(m(x, theta)),
ylim = y_lim,
main = "Function class"
)
lines(x, m_fun(x, 0), col = "#0072B2", lwd = 2)
lines(x, m_fun(x, 1), col = "#D55E00", lwd = 2)
legend(
"topright",
legend = c(expression(theta == 0), expression(theta == 1)),
col = c("#0072B2", "#D55E00"),
lty = 1, lwd = 2, bty = "n"
)
plot(
x, m_fun(x, 0),
type = "n",
xlab = "x", ylab = expression(m(x, theta)),
ylim = y_lim,
main = "Four brackets"
)
for (j in seq_len(J)) {
theta_low <- theta_breaks[j]
theta_high <- theta_breaks[j + 1]
lower <- m_fun(x, theta_low)
upper <- m_fun(x, theta_high)
polygon(
c(x, rev(x)),
c(lower, rev(upper)),
col = band_cols[j],
border = NA
)
lines(x, lower, col = edge_cols[j], lwd = 1.5)
lines(x, upper, col = edge_cols[j], lwd = 1.5)
}
for (theta in theta_many) {
lines(x, m_fun(x, theta), col = adjustcolor("gray30", alpha.f = 0.35), lwd = 0.7)
}
legend(
"topright",
legend = paste0("bracket ", seq_len(J)),
fill = band_cols,
border = edge_cols,
bty = "n"
)
par(old_par)
この例では \(x\in[0,1]\) なので、\(m(x;\theta)\) は \(\theta\) について単調に増える。したがって、\(\theta\) が区間 \([\theta_{j-1},\theta_j]\) に入っているなら、 \[
m(x;\theta_{j-1})
\le
m(x;\theta)
\le
m(x;\theta_j)
\qquad (0\le x\le 1)
\] である。このとき \[
\ell_j(x)=m(x;\theta_{j-1}),
\qquad
u_j(x)=m(x;\theta_j)
\] が 1 つのブラケットになる。
ブラケットの幅は「帯の厚さ」である。たとえば \(X\) が \([0,1]\) 上の一様分布なら、上の例で 4 等分した各ブラケットの平均幅は \[
E[u_j(X)-\ell_j(X)]
=
E[(\theta_j-\theta_{j-1})X]
=
\frac{1}{4}\cdot\frac{1}{2}
=
\frac18
\] である。もっと細かく分ければ帯は薄くなるが、必要なブラケットの数は増える。ブラケット数とは、「指定された幅以下の帯で関数族全体を覆うには、最低いくつ帯が必要か」を表す数である。
したがって、この例では 4 個のブラケットで平均幅 \(1/8\) の精度で関数族全体を挟めている。さらに、\(\theta\) の区間を \(J\) 等分すれば各ブラケットの平均幅は \(1/(2J)\) になるので、任意の \(\varepsilon>0\) に対して十分大きな有限の \(J\) を選べば、幅 \(\varepsilon\) 以下の有限個のブラケットで関数族全体を挟める。
有限個のブラケットで関数族全体を挟めるなら、無限個の関数を一つずつ見る代わりに、有限個の上側関数と下側関数だけを見ればよい。有限個に帰着できれば、大数の法則を同時に適用しやすくなる。
予備知識:線形代数の言葉
GMM や漸近正規性では、ベクトルと行列の記法を使う。ここでは、この章で必要な最小限をまとめる。
ベクトル
ベクトルは数を縦に並べたものである。 \[
x=
\begin{pmatrix}
x_1\\
x_2\\
\vdots\\
x_k
\end{pmatrix}
\in\mathbb R^k.
\]
\(x'\) は転置を表し、縦ベクトルを横ベクトルに変える。 \[
x'=(x_1,x_2,\ldots,x_k).
\]
2 つの同じ長さのベクトル \(x,y\in\mathbb R^k\) の内積は \[
x'y=\sum_{j=1}^k x_jy_j
\] である。ノルムはベクトルの長さであり、 \[
\|x\|=\sqrt{x'x}
\] と書く。
行列
行列は数を長方形に並べたものである。 \[
A=
\begin{pmatrix}
a_{11}&a_{12}&\cdots&a_{1k}\\
a_{21}&a_{22}&\cdots&a_{2k}\\
\vdots&\vdots&\ddots&\vdots\\
a_{r1}&a_{r2}&\cdots&a_{rk}
\end{pmatrix}
\in\mathbb R^{r\times k}.
\]
\(A\in\mathbb R^{r\times k}\) は、\(r\) 行 \(k\) 列の行列という意味である。\(A'\) は転置行列で、行と列を入れ替える。
足し算とスカラー倍
同じサイズの行列やベクトルは、成分ごとに足し算できる。 \[
\begin{pmatrix}1\\2\end{pmatrix}
+
\begin{pmatrix}3\\4\end{pmatrix}
=
\begin{pmatrix}4\\6\end{pmatrix}.
\]
数 \(c\) を掛けるスカラー倍も成分ごとに行う。 \[
c
\begin{pmatrix}1\\2\end{pmatrix}
=
\begin{pmatrix}c\\2c\end{pmatrix}.
\]
掛け算
行列とベクトルの積 \(Ax\) は、\(A\) の列数と \(x\) の長さが一致するときに定義される。\(A\in\mathbb R^{r\times k}\)、\(x\in\mathbb R^k\) なら、\(Ax\in\mathbb R^r\) である。 \[
(Ax)_i=\sum_{j=1}^k a_{ij}x_j.
\]
例えば \[
\begin{pmatrix}
1&2\\
3&4
\end{pmatrix}
\begin{pmatrix}
5\\
6
\end{pmatrix}
=
\begin{pmatrix}
1\cdot 5+2\cdot 6\\
3\cdot 5+4\cdot 6
\end{pmatrix}
=
\begin{pmatrix}
17\\
39
\end{pmatrix}.
\]
行列同士の積 \(AB\) は、\(A\) の列数と \(B\) の行数が一致するときに定義される。成分は \[
(AB)_{ij}=\sum_{\ell}a_{i\ell}b_{\ell j}
\] である。一般に \(AB=BA\) ではない。行列の掛け算では順番が重要である。
ランク
行列 \(A\) の ランク \(\operatorname{rank}(A)\) は、\(A\) の列ベクトルの中に含まれる独立な方向の数である。同じ値は、行ベクトルの中に含まれる独立な方向の数としても定義できる。
例えば \[
A=
\begin{pmatrix}
1&2\\
2&4
\end{pmatrix}
\] では、第 2 列が第 1 列の 2 倍なので、列方向の情報は実質的に 1 つしかない。したがって \(\operatorname{rank}(A)=1\) である。一方、 \[
B=
\begin{pmatrix}
1&0\\
0&1
\end{pmatrix}
\] では 2 本の列が独立なので、\(\operatorname{rank}(B)=2\) である。
\(A\in\mathbb R^{r\times k}\) なら \[
\operatorname{rank}(A)\le \min\{r,k\}
\] である。特に
- \(\operatorname{rank}(A)=k\) のとき、\(A\) は full column rank をもつという。
- \(\operatorname{rank}(A)=r\) のとき、\(A\) は full row rank をもつという。
full column rank は、\(A b=0\) を満たす \(b\) が \(b=0\) しかないことと同値である。つまり、列の間に完全な線形関係がない。
計量経済学では、ランク条件は「冗長な情報がない」「パラメタを識別できる」という意味で現れる。例えば、回帰の設計行列 \(X\in\mathbb R^{n\times k}\) が full column rank であることは、説明変数の間に完全な多重共線性がないことを意味する。このとき \[
X'X
\] は可逆であり、OLS の公式 \((X'X)^{-1}X'y\) が定義できる。
理由は次の通りである。任意の \(b\in\mathbb R^k\) について \[
b'X'Xb=(Xb)'(Xb)=\|Xb\|^2
\] である。\(X\) が full column rank なら、\(b\neq0\) なら \(Xb\neq0\) なので \[
b'X'Xb>0.
\] したがって \(X'X\) は正定値であり、可逆である。
GMM でも同じ発想が出てくる。モーメント条件のヤコビアン \[
G=\frac{\partial g(\theta_0)}{\partial\theta'}
\in\mathbb R^{K\times p}
\] が full column rank \(p\) をもつという仮定は、\(p\) 個のパラメタの局所的な変化が、モーメント条件に独立な方向として現れることを意味する。これは局所識別のための基本的なランク条件である。
仮説検定では full row rank が出てくる。例えば \(r\) 個の制約 \[
a(\theta_0)=0
\] を検定するとき、ヤコビアン \[
A(\theta_0)=\frac{\partial a(\theta_0)}{\partial\theta'}
\in\mathbb R^{r\times p}
\] が full row rank \(r\) をもつという仮定は、\(r\) 個の制約が互いに冗長ではないことを意味する。
逆行列
正方行列 \(A\in\mathbb R^{k\times k}\) に対して、 \[
A^{-1}A=AA^{-1}=I_k
\] を満たす行列 \(A^{-1}\) が存在するとき、\(A\) は可逆であるといい、\(A^{-1}\) を逆行列という。\(I_k\) は単位行列であり、対角成分が 1、それ以外が 0 の行列である。
2 次元の場合、 \[
A=
\begin{pmatrix}
a&b\\
c&d
\end{pmatrix}
\] について \(ad-bc\neq 0\) なら \[
A^{-1}
=
\frac{1}{ad-bc}
\begin{pmatrix}
d&-b\\
-c&a
\end{pmatrix}.
\]
公式を覚えるだけでなく、掃き出し法(行基本変形)で求める様子も見ておくとよい。例えば \[
A=
\begin{pmatrix}
2&1\\
1&1
\end{pmatrix}
\] の逆行列を求める。まず、左に \(A\)、右に単位行列を置いた拡大行列を作る。 \[
\left[
\begin{array}{cc|cc}
2&1&1&0\\
1&1&0&1
\end{array}
\right].
\] 目標は、左側を単位行列に変形することである。まず第 1 行と第 2 行を入れ替える。 \[
\left[
\begin{array}{cc|cc}
1&1&0&1\\
2&1&1&0
\end{array}
\right].
\] 次に、第 2 行から第 1 行の 2 倍を引く。 \[
R_2\leftarrow R_2-2R_1
\] とすると \[
\left[
\begin{array}{cc|cc}
1&1&0&1\\
0&-1&1&-2
\end{array}
\right]
\] となる。第 2 行に \(-1\) を掛けて、左下をきれいにする。 \[
R_2\leftarrow -R_2
\] より \[
\left[
\begin{array}{cc|cc}
1&1&0&1\\
0&1&-1&2
\end{array}
\right].
\] 最後に、第 1 行から第 2 行を引く。 \[
R_1\leftarrow R_1-R_2
\] すると \[
\left[
\begin{array}{cc|cc}
1&0&1&-1\\
0&1&-1&2
\end{array}
\right]
=
\left[
I\mid A^{-1}
\right]
\] が得られる。したがって \[
A^{-1}
=
\begin{pmatrix}
1&-1\\
-1&2
\end{pmatrix}.
\] 実際に掛け算して確認すると \[
\begin{pmatrix}
2&1\\
1&1
\end{pmatrix}
\begin{pmatrix}
1&-1\\
-1&2
\end{pmatrix}
=
\begin{pmatrix}
1&0\\
0&1
\end{pmatrix}
\] である。
一般の次元でも同じように、拡大行列 \[
[A\mid I]
\] を行基本変形で \[
[I\mid A^{-1}]
\] に変形することで逆行列を計算できる。実務では、明示的に逆行列を作るより、\(Ax=b\) を直接解く数値計算の方が安定である。
正方行列 \(A\in\mathbb R^{k\times k}\) が可逆であることは、 \[
\operatorname{rank}(A)=k
\] であることと同値である。ランクが落ちている行列は、どこかの方向の情報を失っているので、逆向きに一意に戻すことができない。
トレース
正方行列 \(A\) の トレース は対角成分の和であり、 \[
\operatorname{tr}(A)=\sum_i a_{ii}
\] と書く。トレースは、分散の合計やあとで見る射影行列の自由度を数えるときに出てくる。
よく使う性質は \[
\operatorname{tr}(AB)=\operatorname{tr}(BA)
\] である。ただし、積が定義されるサイズである必要がある。
固有値と固有ベクトル
正方行列 \(A\) に対して、0 でないベクトル \(v\) と数 \(\lambda\) が \[
Av=\lambda v
\] を満たすとき、\(\lambda\) を固有値、\(v\) を固有ベクトルという。これは、\(A\) を掛けても \(v\) の向きは変わらず、長さだけが \(\lambda\) 倍になるという意味である。
例えば \[
D=
\begin{pmatrix}
3&0\\
0&1
\end{pmatrix}
\] を考える。\(e_1=(1,0)'\) と \(e_2=(0,1)'\) について \[
De_1=
\begin{pmatrix}
3\\0
\end{pmatrix}
=3e_1,
\qquad
De_2=
\begin{pmatrix}
0\\1
\end{pmatrix}
=1e_2
\] である。したがって、\(e_1\) は固有値 3 の固有ベクトル、\(e_2\) は固有値 1 の固有ベクトルである。この行列は横方向を 3 倍し、縦方向はそのままにする。
もう少しだけ面白い例として \[
A=
\begin{pmatrix}
2&1\\
1&2
\end{pmatrix}
\] を考える。この行列は座標軸方向ではなく、斜め方向にわかりやすい伸び縮みをもつ。実際、 \[
A
\begin{pmatrix}
1\\1
\end{pmatrix}
=
\begin{pmatrix}
3\\3
\end{pmatrix}
=3
\begin{pmatrix}
1\\1
\end{pmatrix}
\] なので、\((1,1)'\) は固有値 3 の固有ベクトルである。また \[
A
\begin{pmatrix}
1\\-1
\end{pmatrix}
=
\begin{pmatrix}
1\\-1
\end{pmatrix}
=1
\begin{pmatrix}
1\\-1
\end{pmatrix}
\] なので、\((1,-1)'\) は固有値 1 の固有ベクトルである。つまり、この行列は \((1,1)'\) 方向を 3 倍し、\((1,-1)'\) 方向はそのままにする。
この様子は図で見るとわかりやすい。ここで「単位円に行列 \(A\) を掛ける」とは、円周上の各点を 2 次元ベクトルとして見て、そのすべてに同じ行列 \(A\) を掛けるという意味である。
単位円上の点は \[
x(t)=
\begin{pmatrix}
\cos t\\
\sin t
\end{pmatrix},
\qquad
0\le t\le 2\pi
\] と書ける。この各点を \[
y(t)=Ax(t)
\] に移す。つまり、円周上の点 \[
\begin{pmatrix}
x_1\\x_2
\end{pmatrix}
\] を \[
A
\begin{pmatrix}
x_1\\x_2
\end{pmatrix}
=
\begin{pmatrix}
2x_1+x_2\\
x_1+2x_2
\end{pmatrix}
\] へ写す。これを円周上のすべての点について行うと、円全体が別の曲線に変形される。この例では、単位円は楕円になる。
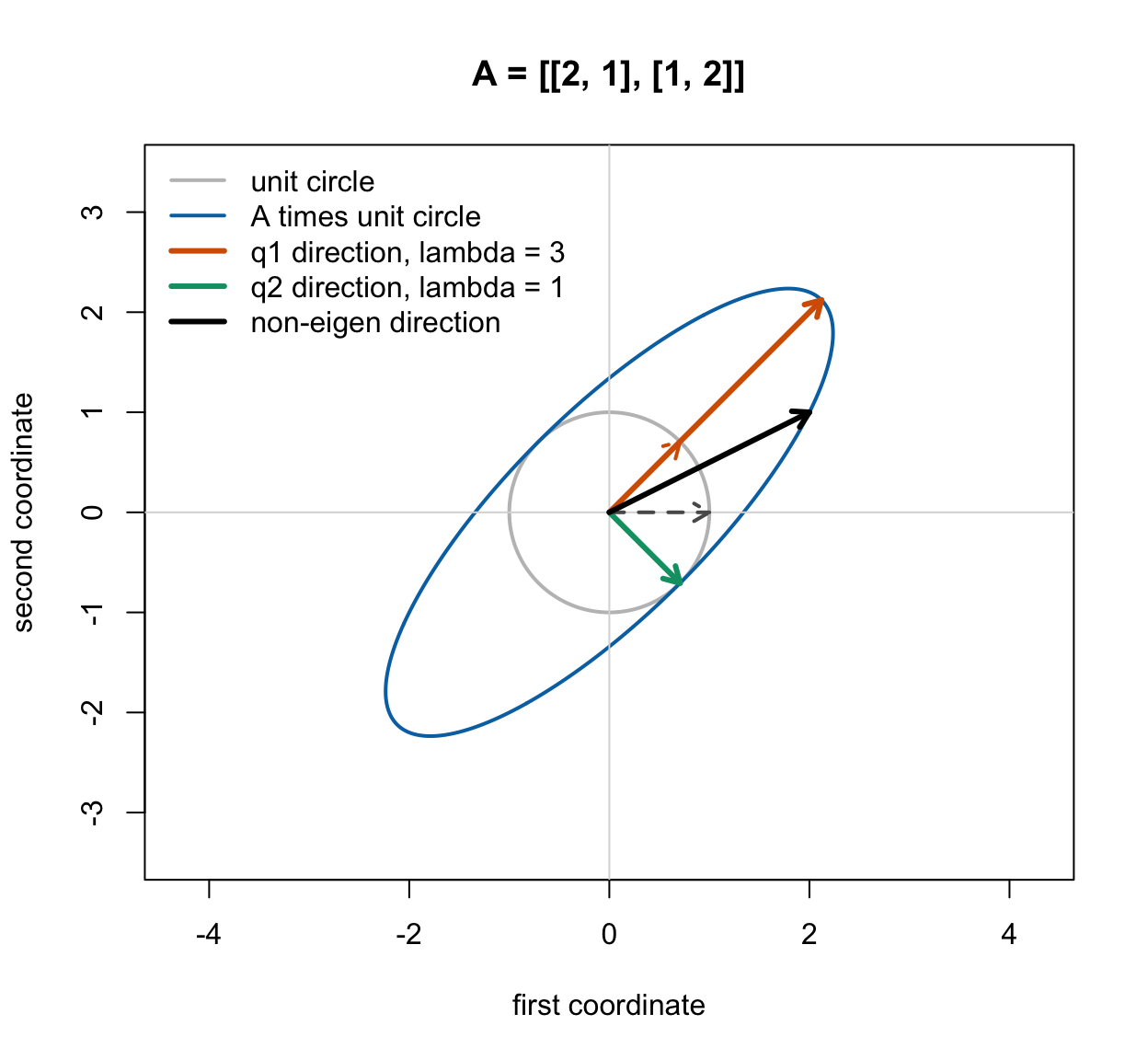
次の図では、薄い灰色の円がもとの単位円、青い楕円が行列 \(A\) を掛けた後の像である。破線の矢印は変換前のベクトル、太い実線の矢印は変換後のベクトルを表す。赤と緑の矢印は固有ベクトル方向である。固有ベクトル方向では、行列を掛けても同じ直線上に残り、長さだけが固有値倍になる。
A <- matrix(c(2, 1, 1, 2), nrow = 2, byrow = TRUE)
angle <- seq(0, 2 * pi, length.out = 500)
unit_circle <- rbind(cos(angle), sin(angle))
image_circle <- A %*% unit_circle
q1 <- c(1, 1) / sqrt(2)
q2 <- c(1, -1) / sqrt(2)
ordinary <- c(1, 0)
draw_arrow <- function(v, col, lty = 1, lwd = 2) {
arrows(0, 0, v[1], v[2], col = col, lty = lty, lwd = lwd, length = 0.1)
}
plot(
t(unit_circle),
type = "l", asp = 1,
xlim = c(-3.4, 3.4), ylim = c(-3.4, 3.4),
xlab = "first coordinate", ylab = "second coordinate",
col = "gray75", lwd = 2,
main = "A = [[2, 1], [1, 2]]"
)
lines(t(image_circle), col = "#0072B2", lwd = 2)
abline(h = 0, v = 0, col = "gray85")
# Original eigenvector directions.
draw_arrow(q1, col = "#D55E00", lty = 2, lwd = 2)
draw_arrow(q2, col = "#009E73", lty = 2, lwd = 2)
# Transformed eigenvectors.
draw_arrow(A %*% q1, col = "#D55E00", lwd = 3)
draw_arrow(A %*% q2, col = "#009E73", lwd = 3)
# A non-eigenvector direction bends away from the original line.
draw_arrow(ordinary, col = "gray35", lty = 2, lwd = 2)
draw_arrow(A %*% ordinary, col = "black", lwd = 3)
legend(
"topleft",
legend = c(
"unit circle",
"A times unit circle",
"q1 direction, lambda = 3",
"q2 direction, lambda = 1",
"non-eigen direction"
),
col = c("gray75", "#0072B2", "#D55E00", "#009E73", "black"),
lty = c(1, 1, 1, 1, 1),
lwd = c(2, 2, 3, 3, 3),
bty = "n"
)
破線の矢印は「変換前」の方向、太い実線の矢印は「変換後」の方向である。赤い固有方向 \(q_1=(1,1)'/\sqrt2\) は同じ方向のまま 3 倍に伸びる。緑の固有方向 \(q_2=(1,-1)'/\sqrt2\) は同じ方向のまま長さが変わらない。一方、黒い矢印で示した普通の方向 \((1,0)'\) は、\(A(1,0)'=(2,1)'\) となり、もとの方向から傾く。固有ベクトルとは、このような「傾かない特別な方向」のことである。
では、なぜこの「傾かない方向」を見つけるとうれしいのか。理由は、行列の働きを一番わかりやすい方向に分解できるからである。一般の方向にあるベクトルは、行列を掛けると向きも長さも同時に変わるので解釈しにくい。しかし固有ベクトル方向では、起きることは単純である。 \[
\text{固有ベクトル方向では、行列は「}\lambda\text{ 倍するだけ」である。}
\] したがって、行列 \(A\) がどの方向を強く伸ばし、どの方向をあまり伸ばさないのかを、固有値と固有ベクトルで読むことができる。
計量経済学では、この見方が何度も出てくる。分散共分散行列の固有ベクトルは「データのばらつきが大きい方向」を表し、固有値はその方向の分散の大きさを表す。Hessian の固有ベクトルは目的関数の曲率の方向を表し、固有値はその方向にどれくらい急に曲がっているかを表す。GMM の重み行列や漸近分散行列を考えるときも、行列を「方向ごとの伸び縮み」として理解できると、どの方向で推定が精密か、どの方向で不安定かが見えやすくなる。
固有値の計算方法
固有値は \[
Av=\lambda v
\] を \[
(A-\lambda I)v=0
\] と書き換えて求める。\(v\neq0\) の解が存在するためには、行列 \(A-\lambda I\) がランク落ちしている必要がある。したがって \[
\det(A-\lambda I)=0
\] を解けば固有値が得られる。
上の例 \[
A=
\begin{pmatrix}
2&1\\
1&2
\end{pmatrix}
\] では \[
A-\lambda I
=
\begin{pmatrix}
2-\lambda&1\\
1&2-\lambda
\end{pmatrix}
\] だから \[
\det(A-\lambda I)
=(2-\lambda)^2-1
=\lambda^2-4\lambda+3
=(\lambda-3)(\lambda-1).
\] したがって固有値は \[
\lambda=3,\quad 1
\] である。
固有ベクトルは、それぞれの固有値を代入して \[
(A-\lambda I)v=0
\] を解けばよい。例えば \(\lambda=3\) なら \[
A-3I=
\begin{pmatrix}
-1&1\\
1&-1
\end{pmatrix}
\] なので \[
-v_1+v_2=0
\] より \(v_1=v_2\) である。したがって固有ベクトルは \((1,1)'\) の定数倍である。\(\lambda=1\) なら \[
A-I=
\begin{pmatrix}
1&1\\
1&1
\end{pmatrix}
\] なので \[
v_1+v_2=0
\] より、固有ベクトルは \((1,-1)'\) の定数倍である。
一般の \(k\times k\) 行列でも考え方は同じである。
- \(\det(A-\lambda I)=0\) を解いて固有値を求める。
- 各固有値 \(\lambda\) について \((A-\lambda I)v=0\) を解いて固有ベクトルを求める。
ただし、次元が大きい行列では手計算で行列式を展開するのは現実的ではない。実務では、数値計算で固有値分解を行う。
対称行列では固有値は実数になり、異なる固有値に対応する固有ベクトルは直交する。したがって、対称行列は互いに直交する方向ごとの伸び縮みとして理解できる。計量経済学では、分散共分散行列、Hessian、GMM の重み行列などを理解するためにこの見方が重要である。
特に対称行列 \(A\) について、固有値を \(\lambda_1,\ldots,\lambda_k\)、対応する正規直交固有ベクトルを \(q_1,\ldots,q_k\) と書くと、 \[
A=Q\Lambda Q',
\qquad
Q=(q_1,\ldots,q_k),
\qquad
\Lambda=\operatorname{diag}(\lambda_1,\ldots,\lambda_k)
\] と分解できる。このとき任意の \(z\) について \[
z'Az
=
(Q'z)'\Lambda(Q'z)
=
\sum_{j=1}^k \lambda_j c_j^2,
\qquad
c=Q'z
\] である。したがって、すべての固有値が正なら \(z'Az>0\)、すべての固有値が 0 以上なら \(z'Az\ge0\) になる。この事実が、次に見る正定値・半正定値の判定につながる。
多変量正規分布と分散共分散行列
正定値行列の話に進む前に、分散共分散行列が何を表しているかを整理しておく。
1 変量の正規分布は \[
X\sim N(\mu,\sigma^2)
\] と書く。ここで \(\mu\) は平均、\(\sigma^2\) は分散である。多変量の場合、確率ベクトル \[
X=
\begin{pmatrix}
X_1\\
\vdots\\
X_k
\end{pmatrix}
\] が多変量正規分布に従うことを \[
X\sim N(\mu,\Sigma)
\] と書く。ここで \[
\mu=
\begin{pmatrix}
E[X_1]\\
\vdots\\
E[X_k]
\end{pmatrix}
\] は平均ベクトルであり、 \[
\Sigma
=
\operatorname{Var}(X)
=
E[(X-\mu)(X-\mu)']
\] は分散共分散行列である。
2 変量なら \[
\Sigma=
\begin{pmatrix}
\operatorname{Var}(X_1)&\operatorname{Cov}(X_1,X_2)\\
\operatorname{Cov}(X_2,X_1)&\operatorname{Var}(X_2)
\end{pmatrix}
\] である。対角成分は各変数の分散であり、非対角成分は変数間の共分散である。共分散が正なら、\(X_1\) が大きいとき \(X_2\) も大きくなりやすい。共分散が負なら、\(X_1\) が大きいとき \(X_2\) は小さくなりやすい。
\(\Sigma\) が正定値のとき、多変量正規分布の密度は \[
f(x)
=
\frac{1}{(2\pi)^{k/2}|\Sigma|^{1/2}}
\exp\left\{
-\frac12(x-\mu)'\Sigma^{-1}(x-\mu)
\right\}
\] である。ここで \[
(x-\mu)'\Sigma^{-1}(x-\mu)
\] は、分散共分散行列で調整した距離である。\(\Sigma\) が大きい方向では、同じだけ動いても「それほど珍しくない」と判断される。
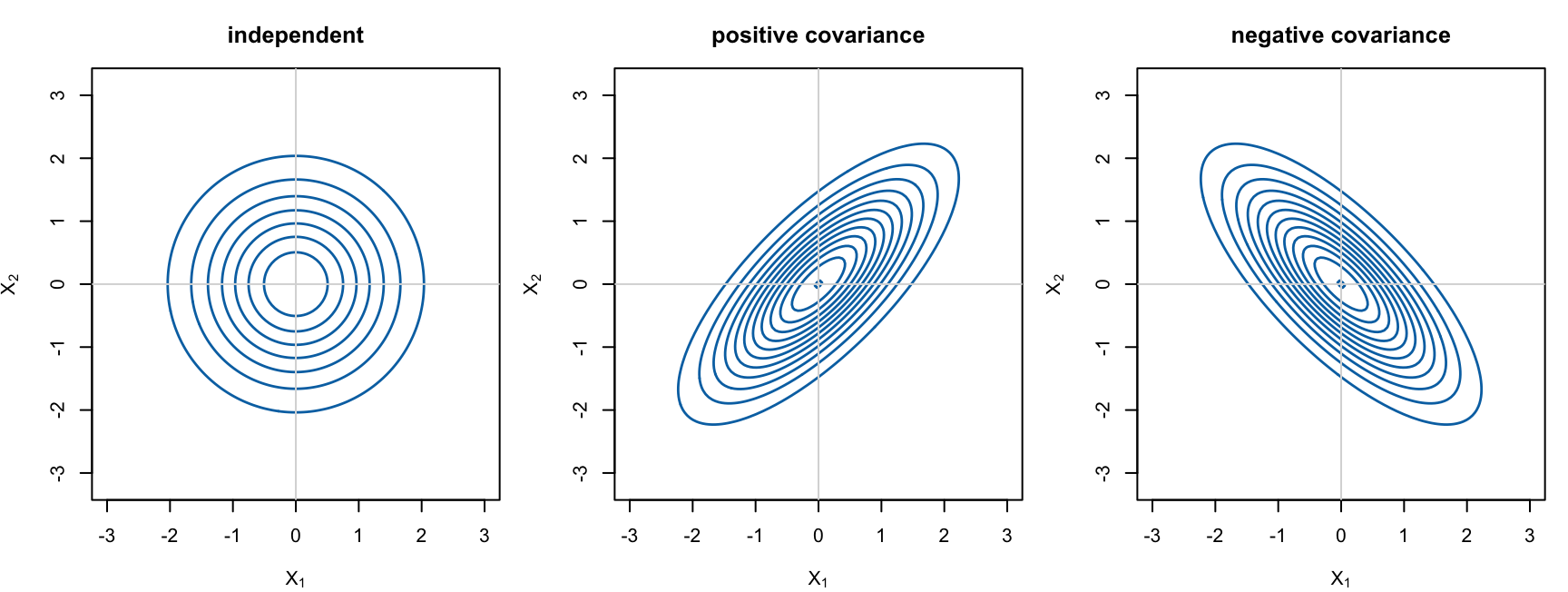
次の図では、平均 0 の 2 変量正規分布について、分散共分散行列を変えたときに等高線がどう変わるかを描いている。
dmvnorm2 <- function(x1, x2, Sigma) {
X <- cbind(as.vector(x1), as.vector(x2))
inv_Sigma <- solve(Sigma)
quad <- rowSums((X %*% inv_Sigma) * X)
dens <- exp(-0.5 * quad) / (2 * pi * sqrt(det(Sigma)))
matrix(dens, nrow = nrow(x1), ncol = ncol(x1))
}
grid <- seq(-3, 3, length.out = 120)
grid_xy <- expand.grid(x = grid, y = grid)
x_mat <- matrix(grid_xy$x, nrow = length(grid), ncol = length(grid))
y_mat <- matrix(grid_xy$y, nrow = length(grid), ncol = length(grid))
Sigmas <- list(
"independent" = matrix(c(1, 0, 0, 1), 2, 2),
"positive covariance" = matrix(c(1, 0.75, 0.75, 1), 2, 2),
"negative covariance" = matrix(c(1, -0.75, -0.75, 1), 2, 2)
)
old_par <- par(mfrow = c(1, 3), mar = c(4, 4, 3, 1))
for (name in names(Sigmas)) {
z <- dmvnorm2(x_mat, y_mat, Sigmas[[name]])
contour(
grid, grid, z,
xlab = expression(X[1]), ylab = expression(X[2]),
main = name,
asp = 1,
drawlabels = FALSE,
col = "#0072B2",
lwd = 1.4
)
abline(h = 0, v = 0, col = "gray85")
}
par(old_par)
独立な場合、等高線は軸に沿った円になる。正の共分散があると、等高線は右上がりに傾く。負の共分散があると、等高線は右下がりに傾く。したがって分散共分散行列は、「各変数がどれくらいばらつくか」だけでなく、「どの方向に一緒に動きやすいか」を表している。
この行列が半正定値でなければならない理由も自然である。任意のベクトル \(z\) について、線形結合 \(z'X\) の分散は \[
\operatorname{Var}(z'X)
=
z'\Sigma z
\] である。分散は負になれないので、必ず \[
z'\Sigma z\ge0
\] でなければならない。この性質が、次の半正定値・正定値の定義につながる。
半正定値行列と正定値行列
対称行列 \(A\) が 半正定値 であるとは、任意のベクトル \(z\) について \[
z'Az\ge0
\] が成り立つことである。このとき \[
A\succeq0
\] と書くことがある。
対称行列 \(A\) が 正定値 であるとは、任意の 0 でないベクトル \(z\) について \[
z'Az>0
\] が成り立つことである。
正定値行列は、2 次関数 \[
z'Az
\] が原点以外で必ず正になることを意味する。対称行列の場合、正定値であることは、すべての固有値が正であることと同値である。半正定値であることは、すべての固有値が 0 以上であることと同値である。
分散共分散行列は必ず半正定値である。確率ベクトル \(V\) の分散共分散行列を \[
\Omega=\operatorname{Var}(V)
\] とすると、任意の \(z\) について \[
z'\Omega z
=
\operatorname{Var}(z'V)
\ge0
\] だからである。もし \(z'V\) の分散が 0 になるような非ゼロの \(z\) が存在しなければ、\(\Omega\) は正定値である。
正定値行列は可逆であり、極値推定では目的関数の曲率や GMM の重み行列としてよく現れる。一方、半正定値行列は可逆とは限らない。例えば、分散共分散行列が特異である場合、データやモーメントの中に完全な線形関係があることを示している。
また、2 つの対称行列 \(A\) と \(B\) について \[
A\succeq B
\] と書くときは、 \[
A-B
\] が半正定値であるという意味である。GMM の効率性を比較するときに、この半正定値の意味での大小関係を使う。
ベクトルについての微分
パラメタ \(\theta=(\theta_1,\ldots,\theta_p)'\) に依存するスカラー関数 \(q(\theta)\) の勾配は \[
\frac{\partial q(\theta)}{\partial\theta}
=
\begin{pmatrix}
\partial q(\theta)/\partial\theta_1\\
\vdots\\
\partial q(\theta)/\partial\theta_p
\end{pmatrix}.
\]
2 階微分を並べた行列を Hessian という。 \[
\frac{\partial^2 q(\theta)}{\partial\theta\partial\theta'}
=
\left(
\frac{\partial^2 q(\theta)}{\partial\theta_i\partial\theta_j}
\right)_{i,j}.
\]
よく使う公式は次の通りである。\(a\) はベクトル、\(A\) は対称行列とする。 \[
\frac{\partial a'\theta}{\partial\theta}=a,
\qquad
\frac{\partial}{\partial\theta}\left(\frac12\theta'A\theta\right)=A\theta.
\]
また、\(b-A\theta\) という残差ベクトルに対して \[
\frac{\partial}{\partial\theta}(b-A\theta)'(b-A\theta)
=
-2A'(b-A\theta).
\]
ベクトル値関数 \(g(\theta)\in\mathbb R^K\) の微分はヤコビアンで表す。 \[
G(\theta)
=
\frac{\partial g(\theta)}{\partial\theta'}
\in\mathbb R^{K\times p}.
\]
応用:OLS の行列表記
観測を縦に積んで \[
y=
\begin{pmatrix}
y_1\\
\vdots\\
y_n
\end{pmatrix},
\qquad
X=
\begin{pmatrix}
x_1'\\
\vdots\\
x_n'
\end{pmatrix},
\qquad
\beta=
\begin{pmatrix}
\beta_1\\
\vdots\\
\beta_k
\end{pmatrix}
\] と書く。線形回帰モデルは \[
y=X\beta_0+u
\] である。
OLS は残差平方和 \[
S(\beta)=(y-X\beta)'(y-X\beta)
\] を最小化する。微分公式を使うと \[
\frac{\partial S(\beta)}{\partial\beta}
=
-2X'(y-X\beta).
\]
一階条件は \[
X'(y-X\hat\beta)=0
\] である。これを整理すると正規方程式 \[
X'X\hat\beta=X'y
\] が得られる。\(X'X\) が可逆なら \[
\hat\beta=(X'X)^{-1}X'y
\] である。
この式は、OLS 推定量が「残差をすべての説明変数と直交させる」ように選ばれていることを意味する。さらに \(y=X\beta_0+u\) を代入すると \[
\hat\beta-\beta_0=(X'X)^{-1}X'u
=
\left(\frac{X'X}{n}\right)^{-1}\left(\frac{X'u}{n}\right)
\] となる。両辺に \(\sqrt n\) を掛けると \[
\sqrt n(\hat\beta-\beta_0)
=
\left(\frac{X'X}{n}\right)^{-1}
\left(\frac{X'u}{\sqrt n}\right),
\] となり、後で出てくる極値推定量の漸近正規性と同じ構造が見える。
応用:OLS と射影行列
OLS は、幾何学的には \(y\) を \(X\) の列空間に射影する操作である。この見方を行列で表すと、回帰分析の多くの性質が短く書ける。
正方行列 \(P\) が \[
P^2=P
\] を満たすとき、\(P\) を 冪等行列 という。さらに \[
P'=P
\] も満たすとき、\(P\) は直交射影行列である。
\(X\) が full column rank のとき、 \[
P_X=X(X'X)^{-1}X'
\] は \(X\) の列空間への直交射影行列である。実際、OLS の fitted value は \[
\hat y
=
X\hat\beta
=
X(X'X)^{-1}X'y
=
P_Xy
\] と書ける。つまり、\(\hat y\) は \(y\) を説明変数の張る空間に落としたものである。
残差を作る行列は \[
M_X=I-P_X
\] である。OLS の残差は \[
\hat u
=
y-\hat y
=
(I-P_X)y
=
M_Xy
\] と書ける。
射影行列は次の性質をもつ。 \[
P_X^2=P_X,
\qquad
P_X'=P_X,
\qquad
M_X^2=M_X,
\qquad
M_X'=M_X.
\] また \[
X'M_X=0
\] である。これは、OLS 残差がすべての説明変数と直交することを行列で書いたものである。実際、 \[
X'\hat u
=
X'M_Xy
=0
\] であり、これは正規方程式 \(X'(y-X\hat\beta)=0\) と同じ内容である。
射影行列のランクは、射影先の空間の次元を表す。\(X\) が \(n\times k\) で full column rank なら \[
\operatorname{rank}(P_X)=k,
\qquad
\operatorname{rank}(M_X)=n-k.
\] この \(n-k\) は OLS の残差自由度として現れる。冪等行列では、トレースとランクが一致するので \[
\operatorname{tr}(P_X)=k,
\qquad
\operatorname{tr}(M_X)=n-k
\] でもある。