OLS は「データにいちばん合う直線」を選ぶ方法 である。ただし、OLS がいつでも因果効果を教えてくれるわけではない。
定義から出る性質 と、仮定を置いたときの推定量としての性質 は分けて理解する。
今回は、まず説明変数が1つのケースにしぼって OLS を導入する。前半では「どうやって直線を決めるのか」を丁寧に追い、後半では「その直線をいつパラメータとして読めるのか」を考える。
OLS を 残差平方和を最小にする方法 として定義する。
そこから、平均点を通る・残差和が 0 になるなどの 機械的な性質 を見る。
最後に、E[u_i\mid x_i]=0 の意味を通じて、OLS がいつ 推定量 として意味を持つかを整理する。
今回は、まず説明変数が1つのケースにしぼって OLS の話をする。
OLSの導入:まずは「いちばん合う直線」から
まずはOLSをその発想から導入していく。
1. 直線を「いちばんそれっぽく」当てはめる
データが n 人(あるいは n 個体)ぶんあるとする。i=1,\dots,n について、次の2つを観測する。
説明変数(原因っぽいもの):x_i
被説明変数(結果っぽいもの):y_i
例として、
x_i :勉強時間(時間)y_i :テストの点数(点)
のような状況を想像すればよい。
ここで目標は単純で、
x が増えると y はどれくらい増えるのか?
を知ることになる。
そのために、x から y を予測する「直線」を考える。
\widehat{y}_i = a + b x_i
ここで
a :切片(x=0 のときの予測値)b :傾き(x が 1 増えると予測値がどれだけ変わるか)
という意味を持つ。a と b をデータから決めるのがOLSだ。
2. 予測が外れた分:残差
直線で予測した値 \widehat{y}_i と実際の値 y_i は一般には一致しない。
e_i = y_i - \widehat{y}_i
と定義する。これが 残差 だ。
直線の式を代入すると、
e_i = y_i - (a + b x_i)
となる。
3. どんな直線が「よい」直線か?
直線がよい、というのは「ズレ(残差)が小さい」ことを意味する。
単純に e_i を足す(\sum e_i )だけだと、プラスとマイナスが打ち消し合ってしまう。e_1=10 と e_2=-10 なら合計は 0 だが、ズレが大きい事実は消えない。
そこでズレを 二乗 して足し合わせる。
\text{残差平方和} \equiv \sum_{i=1}^n e_i^2
これを英語で Sum of Squared Errors と呼び、略して SSE と言う。
e_i = y_i - (a + b x_i) なので、SSEは
S(a,b) = \sum_{i=1}^n \left( y_i - (a + b x_i) \right)^2
という、a と b の関数になる。
4. OLSの定義:SSEを最小にする a,b を選ぶ
ここまで来たら、OLSの定義は一言で済む。
OLS(最小二乗法) とは、残差平方和 S(a,b) が最小になるように (a,b) を選ぶ方法。
つまり
(\widehat{a},\widehat{b})
= \arg\min_{a,b}\ \sum_{i=1}^n \left( y_i - (a + b x_i) \right)^2
これがOLSの 定義 だ。
この (\widehat{a},\widehat{b}) を
\widehat{a} :OLS切片(推定された切片)\widehat{b} :OLS傾き(推定された傾き)
と呼ぶ。
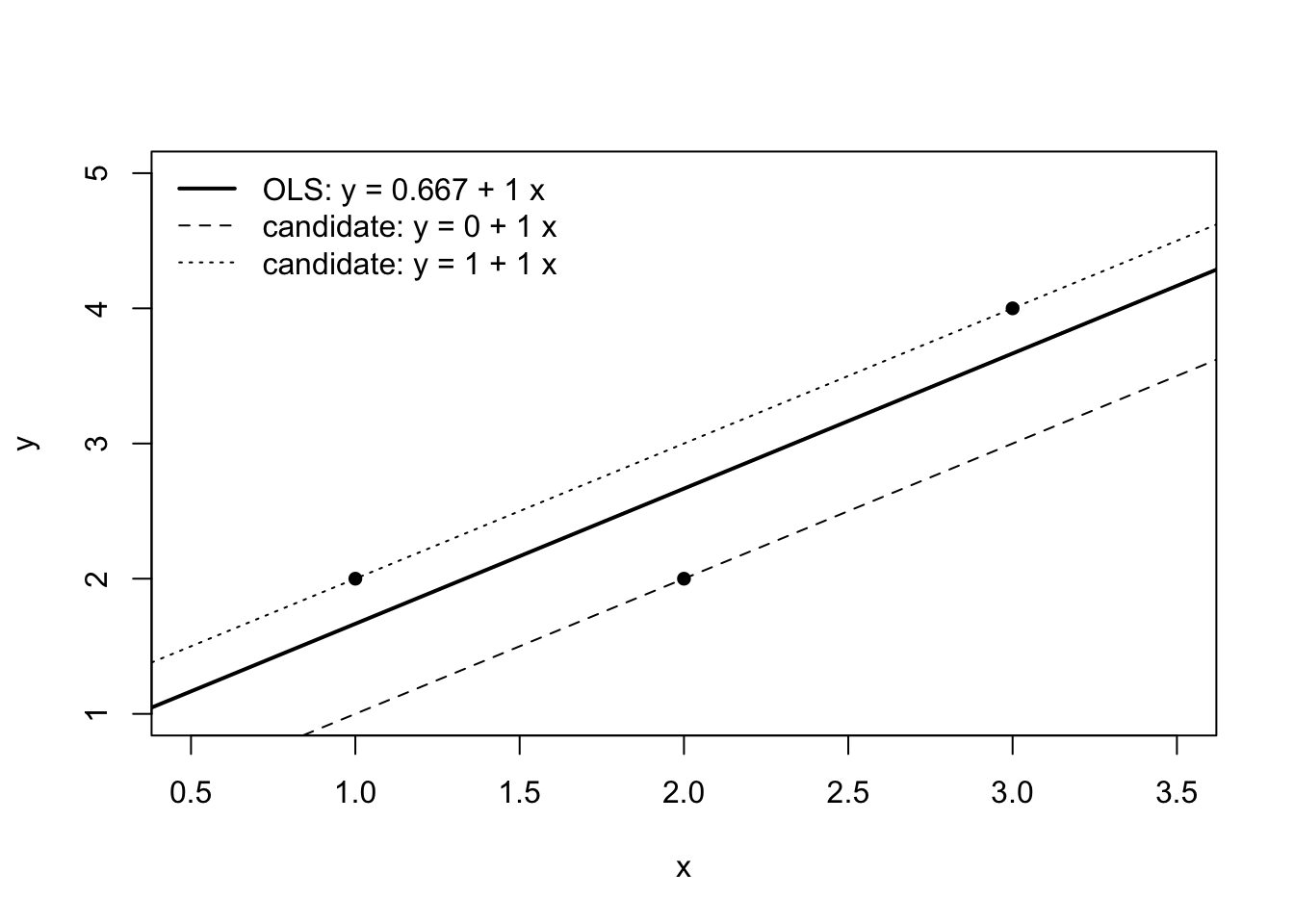
5. 具体例:3点だけのデータで考える
たとえば次の3点があったとする。
(x_1,y_1)=(1,2) (x_2,y_2)=(2,2) (x_3,y_3)=(3,4)
ある直線 \widehat{y}=a+bx を考え、仮に a=0 、b=1 とすると
x=1 の予測:\widehat{y}_1=1 (実際は2)x=2 の予測:\widehat{y}_2=2 (実際は2)x=3 の予測:\widehat{y}_3=3 (実際は4)
残差は
e_1=2-1=1 e_2=2-2=0 e_3=4-3=1
SSEは
S(0,1)=1^2+0^2+1^2=2
となる。
別の直線 a=1 、b=1 なら
予測:\widehat{y}_1=2,\widehat{y}_2=3,\widehat{y}_3=4
残差:e_1=0,e_2=-1,e_3=0
SSE:
S(1,1)=0^2+(-1)^2+0^2=1
この方がSSEが小さいので、「よりよい直線」だと言える。
OLSは、このように SSEが最小になる直線を探す 方法だ。
6. この3点の例でOLSを手計算する
やることは「S(a,b) を最小にする a,b を探す」だけだ。n=3 で、データは
(x_1,y_1)=(1,2) (x_2,y_2)=(2,2) (x_3,y_3)=(3,4)
だった。
まず残差平方和は
S(a,b)=\sum_{i=1}^3 \left(y_i-(a+bx_i)\right)^2
なので、具体的に代入して
S(a,b)=(2-(a+b\cdot 1))^2+(2-(a+b\cdot 2))^2+(4-(a+b\cdot 3))^2
つまり
S(a,b)=(2-a-b)^2+(2-a-2b)^2+(4-a-3b)^2
となる。これを a と b について最小化する。
6.1 微分して「最小」の条件を書く
S(a,b) は a,b の二次式なので、微分して 0 とおけば最小点が出る。
まず a で偏微分する。-a 」なので、微分すると -2(\text{中身}) が出る。
\frac{\partial S}{\partial a}
= -2(2-a-b)-2(2-a-2b)-2(4-a-3b)
これを 0 にする:
-2\{(2-a-b)+(2-a-2b)+(4-a-3b)\}=0
両辺を -2 で割って
(2-a-b)+(2-a-2b)+(4-a-3b)=0
左辺を整理すると
定数:2+2+4=8
a :-a-a-a=-3a b :-b-2b-3b=-6b
なので
8-3a-6b=0
つまり
3a+6b=8
これが1本目の条件だ。
次にb で偏微分する。(2-a-b) の b による微分は -1 、(2-a-2b) は -2 、(4-a-3b) は -3 なので
\frac{\partial S}{\partial b}
= -2\cdot 1\cdot(2-a-b)-2\cdot 2\cdot(2-a-2b)-2\cdot 3\cdot(4-a-3b)
これを 0 にする:
-2(2-a-b)-4(2-a-2b)-6(4-a-3b)=0
両辺を -2 で割ると
(2-a-b)+2(2-a-2b)+3(4-a-3b)=0
それぞれ展開する。
(2-a-b) 2(2-a-2b)=4-2a-4b 3(4-a-3b)=12-3a-9b
足し合わせると
定数:2+4+12=18
a :-a-2a-3a=-6a b :-b-4b-9b=-14b
よって
18-6a-14b=0
つまり
6a+14b=18
これが2本目の条件だ。
6.2 連立方程式を解く
今得た2本を並べる:
3a+6b=8
6a+14b=18
1本目を2倍すると
6a+12b=16
これを2本目から引く:
(6a+14b)-(6a+12b)=18-16
2b=2
よって
b=1
これを1本目に代入する:
3a+6\cdot 1=8
3a=2
したがって
a=\frac{2}{3}
結論として、この3点のOLSは
\widehat{y}=\widehat{a}+\widehat{b}x=\frac{2}{3}+1\cdot x
つまり
\widehat{y}=\frac{2}{3}+x
となる。
6.3 当てはまり(残差とSSE)を確認する
この直線での予測値は
x=1 :\widehat{y}_1=\frac{2}{3}+1=\frac{5}{3} x=2 :\widehat{y}_2=\frac{2}{3}+2=\frac{8}{3} x=3 :\widehat{y}_3=\frac{2}{3}+3=\frac{11}{3}
残差は e_i=y_i-\widehat{y}_i だから
e_1=2-\frac{5}{3}=\frac{1}{3} e_2=2-\frac{8}{3}=-\frac{2}{3} e_3=4-\frac{11}{3}=\frac{1}{3}
SSEは
S(\widehat{a},\widehat{b})
=\left(\frac{1}{3}\right)^2+\left(-\frac{2}{3}\right)^2+\left(\frac{1}{3}\right)^2
=\frac{1}{9}+\frac{4}{9}+\frac{1}{9}
=\frac{6}{9}
=\frac{2}{3}
となる。
この手計算は、手順としては
S(a,b) を具体的に書くa と b で微分して 0 とおく連立方程式を解く
という流れだった。
以下にこの3点の例を図示しておく。
# ---- data ---- <- data.frame (x = c (1 , 2 , 3 ),y = c (2 , 2 , 4 )# ---- OLS fit (y = a + b x) ---- <- lm (y ~ x, data = df)<- coef (fit)[1 ]<- coef (fit)[2 ]# ---- plot range ---- <- min (df$ x) - 0.5 <- max (df$ x) + 0.5 # ---- base plot ---- plot (df$ x, df$ y,xlab = "x" , ylab = "y" ,xlim = c (x_min, x_max),ylim = range (df$ y) + c (- 1 , 1 ),pch = 16 )# ---- OLS line ---- abline (a = a_hat, b = b_hat, lwd = 2 )# ---- optional: candidate lines from the text ---- abline (a = 0 , b = 1 , lty = 2 ) # a=0, b=1 abline (a = 1 , b = 1 , lty = 3 ) # a=1, b=1 # ---- legend ---- legend ("topleft" ,legend = c (paste0 ("OLS: y = " , round (a_hat, 3 ), " + " , round (b_hat, 3 ), " x" ),"candidate: y = 0 + 1 x" ,"candidate: y = 1 + 1 x" lty = c (1 , 2 , 3 ),lwd = c (2 , 1 , 1 ),bty = "n" )
7. n 個の点でOLS
いま、データが n 個あるとする。
観測:(x_1,y_1),(x_2,y_2),\dots,(x_n,y_n)
直線は
\widehat{y}_i = a + b x_i
残差は
e_i = y_i - \widehat{y}_i = y_i - (a+bx_i)
残差平方和(SSE)は
S(a,b)=\sum_{i=1}^n \left(y_i-(a+bx_i)\right)^2
OLSは、この S(a,b) を最小にする (a,b) を選ぶ方法だった。
(\widehat{a},\widehat{b})=\arg\min_{a,b}\ \sum_{i=1}^n \left(y_i-(a+bx_i)\right)^2
ここから先は、さっきの3点の例と全く同じで、a と b で微分して 0 とおき、連立方程式を解く。
7.1 a で微分して 0 とおく(1本目の条件)
まず a で偏微分する。
\frac{\partial S}{\partial a}
=\sum_{i=1}^n 2\left(y_i-(a+bx_i)\right)\cdot(-1)
= -2\sum_{i=1}^n \left(y_i-a-bx_i\right)
最小点ではこれが 0 になるので
-2\sum_{i=1}^n \left(y_i-a-bx_i\right)=0
-2 を消して
\sum_{i=1}^n \left(y_i-a-bx_i\right)=0
和をバラすと
\sum_{i=1}^n y_i - \sum_{i=1}^n a - \sum_{i=1}^n b x_i = 0
ここで a は i によらず一定なので \sum_{i=1}^n a = na 。同様に b も一定なので \sum_{i=1}^n b x_i = b\sum_{i=1}^n x_i 。
したがって
\sum_{i=1}^n y_i - na - b\sum_{i=1}^n x_i = 0
両辺を n で割ると
\frac{1}{n}\sum_{i=1}^n y_i
= a + b\frac{1}{n}\sum_{i=1}^n x_i
ここで
\bar{x}=\frac{1}{n}\sum_{i=1}^n x_i,\quad
\bar{y}=\frac{1}{n}\sum_{i=1}^n y_i
と置けば、1本目の条件は
\bar{y}=a+b\bar{x}
となる。
これは直感的に言うと、
OLSで引いた直線は、必ず点 (\bar{x},\bar{y}) (両変数の平均)を通る
という性質だ。
7.2 b で微分して 0 とおく(2本目の条件)
次に b で偏微分する。
\frac{\partial S}{\partial b}
=\sum_{i=1}^n 2\left(y_i-(a+bx_i)\right)\cdot(-x_i)
= -2\sum_{i=1}^n x_i\left(y_i-a-bx_i\right)
最小点ではこれが 0 なので
\sum_{i=1}^n x_i\left(y_i-a-bx_i\right)=0
これを展開して
\sum_{i=1}^n x_i y_i - a\sum_{i=1}^n x_i - b\sum_{i=1}^n x_i^2 = 0
ここまでが2本目の条件だ。
7.3 2本の条件から a,b を解く
いま手元にある条件は次の2本。
1本目:
\bar{y}=a+b\bar{x}
2本目:
\sum_{i=1}^n x_i y_i - a\sum_{i=1}^n x_i - b\sum_{i=1}^n x_i^2 = 0
ここで1本目から a を b で書くと
a=\bar{y}-b\bar{x}
これを2本目へ代入する。
\sum_{i=1}^n x_i y_i - (\bar{y}-b\bar{x})\sum_{i=1}^n x_i - b\sum_{i=1}^n x_i^2 = 0
\sum_{i=1}^n x_i = n\bar{x} を使うと
\sum_{i=1}^n x_i y_i - (\bar{y}-b\bar{x})n\bar{x} - b\sum_{i=1}^n x_i^2 = 0
整理すると
\sum_{i=1}^n x_i y_i - n\bar{x}\bar{y} + bn\bar{x}^2 - b\sum_{i=1}^n x_i^2 = 0
b の項をまとめると
b\left(n\bar{x}^2-\sum_{i=1}^n x_i^2\right)
= -\left(\sum_{i=1}^n x_i y_i - n\bar{x}\bar{y}\right)
両辺にマイナスをかけて順番を入れ替えると
b\left(\sum_{i=1}^n x_i^2-n\bar{x}^2\right)
= \sum_{i=1}^n x_i y_i - n\bar{x}\bar{y}
よって
\widehat{b}
=\frac{\sum_{i=1}^n x_i y_i - n\bar{x}\bar{y}}
{\sum_{i=1}^n x_i^2 - n\bar{x}^2}
そして
\widehat{a}=\bar{y}-\widehat{b}\bar{x}
が得られる。
7.4 「平均との差」に書き直してわかりやすくする
さっき出た式は少し見た目がごちゃつくので、よく使われる形に直す。
次の恒等式が成り立つ:
\sum_{i=1}^n (x_i-\bar{x})^2 = \sum_{i=1}^n x_i^2 - n\bar{x}^2
\sum_{i=1}^n (x_i-\bar{x})(y_i-\bar{y}) = \sum_{i=1}^n x_i y_i - n\bar{x}\bar{y}
これを使うと、\widehat{b} は
\widehat{b}
=\frac{\sum_{i=1}^n (x_i-\bar{x})(y_i-\bar{y})}
{\sum_{i=1}^n (x_i-\bar{x})^2}
となる。
この形の意味は明快で、
分子:x が平均との差で正にずれたとき、y も平均との差で正にずれやすいか(同方向に動くか)
分母:x 自体がどれくらい散らばっているか
を表している。
だから \widehat{b} は、ざっくり言えば
x と y が一緒に動く強さ(分子)を、x の散らばり(分母)で割ったもの
になっている。
7.5 3点の例に戻って確認
さっきの例では
\bar{x}=\frac{1+2+3}{3}=2 \bar{y}=\frac{2+2+4}{3}=\frac{8}{3}
分子:
\sum_{i=1}^3 (x_i-\bar{x})(y_i-\bar{y})
= (1-2)\left(2-\frac{8}{3}\right) + (2-2)\left(2-\frac{8}{3}\right) + (3-2)\left(4-\frac{8}{3}\right)
計算すると
= (-1)\left(-\frac{2}{3}\right) + 0\left(-\frac{2}{3}\right) + (1)\left(\frac{4}{3}\right)
= \frac{2}{3} + 0 + \frac{4}{3}
= 2
分母:
\sum_{i=1}^3 (x_i-\bar{x})^2 = (1-2)^2+(2-2)^2+(3-2)^2 = 1+0+1=2
だから
\widehat{b}=\frac{2}{2}=1
そして
\widehat{a}=\bar{y}-\widehat{b}\bar{x}=\frac{8}{3}-1\cdot 2=\frac{2}{3}
確かに手計算と一致する。
7.6 図で確認:n 個の点とOLS(Rで実行)
ここまでで、OLSは「残差平方和(SSE)を最小にする直線」を選ぶ方法だとわかった。
7.6.1 Rコード:データを作ってOLSを実行する
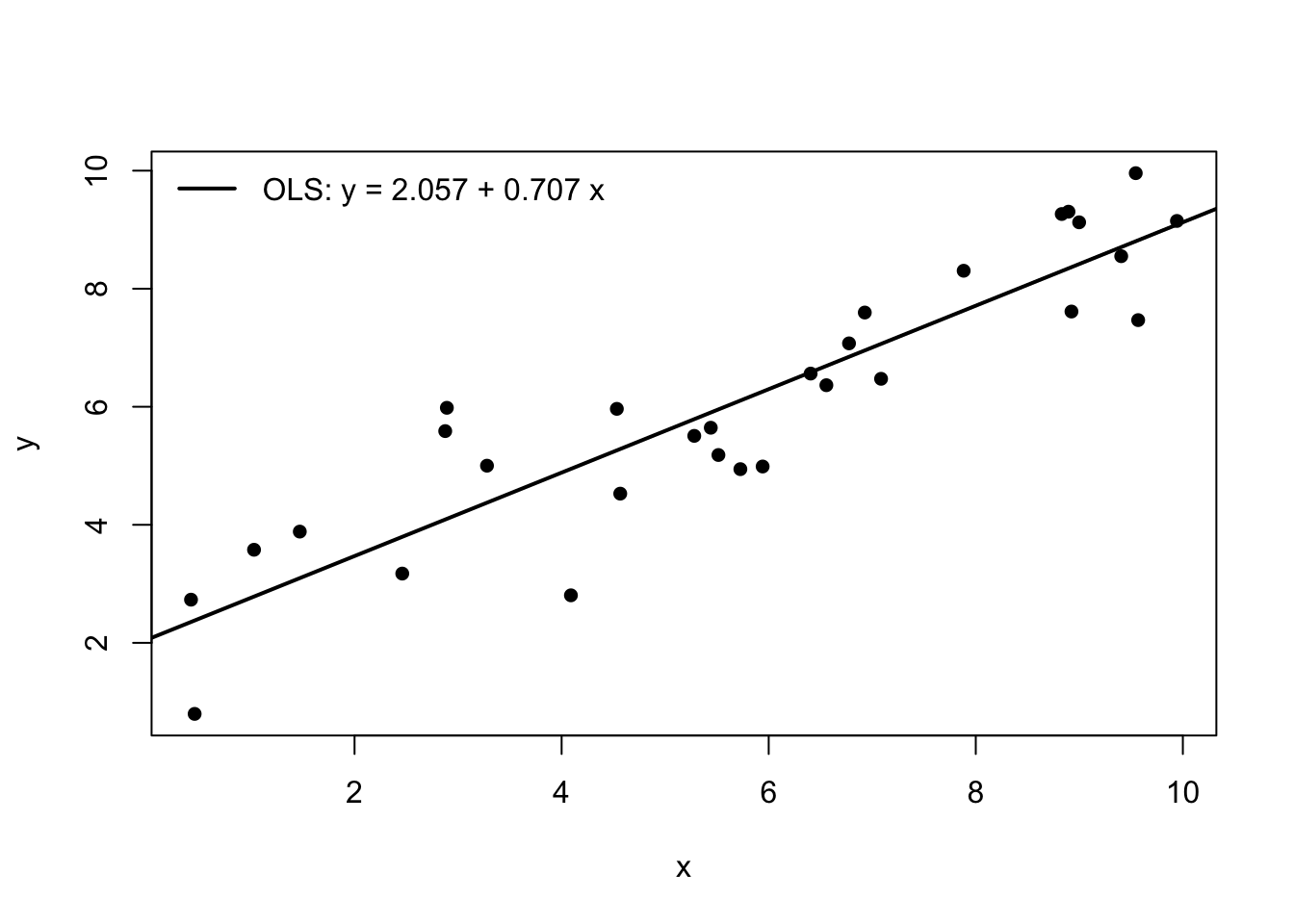
# ------------------------------------------------- # 1) データ(例として n 個の点を作る) # ------------------------------------------------- set.seed (123 )<- 30 <- runif (n, min = 0 , max = 10 ) # x をランダムに作る <- 1.5 + 0.8 * x + rnorm (n, mean = 0 , sd = 1 ) # 直線 + ノイズで y を作る <- data.frame (x = x, y = y)# ------------------------------------------------- # 2) OLS を実行する(y = a + b x) # ------------------------------------------------- <- lm (y ~ x, data = df)# 推定された a, b(切片と傾き) <- coef (fit)[1 ]<- coef (fit)[2 ]
lm(y ~ x, data = df) がOLSそのものだ。 y ~ x は「y を x の一次式 a+bx で説明する」という意味になる。
coef(fit) は推定された係数を返す。 ここで
coef(fit)[1] が \widehat{a} (切片)coef(fit)[2] が \widehat{b} (傾き)
に対応する。
7.6.2 Rコード:散布図とOLS直線を描く
# 散布図 plot (df$ x, df$ y,xlab = "x" , ylab = "y" ,pch = 16 )# OLS直線(推定された a_hat, b_hat を使う) abline (a = a_hat, b = b_hat, lwd = 2 )# 凡例 legend ("topleft" ,legend = paste0 ("OLS: y = " , round (a_hat, 3 ), " + " , round (b_hat, 3 ), " x" ),lwd = 2 , bty = "n" )
点がデータ (x_i,y_i) を表し、太い直線がOLSの直線 \widehat{y}= \widehat{a}+\widehat{b}x を表している。
7.6.3 「SSE最小」を実感する:残差とSSEを計算する
OLSはSSEを最小にするはずなので、実際にSSEを計算してみる。 各点の予測値は \widehat{y}_i=\widehat{a}+\widehat{b}x_i 、残差は e_i=y_i-\widehat{y}_i だった。
# 予測値と残差 <- predict (fit) # 各 i の予測値 \hat{y}_i <- df$ y - y_hat # 残差 e_i = y_i - \hat{y}_i # SSE = sum e_i^2 <- sum (e^ 2 )
predict(fit) は各点の予測値 \widehat{y}_i を返す。 そして sum(e^2) が
\sum_{i=1}^n e_i^2
すなわちSSEになっている。
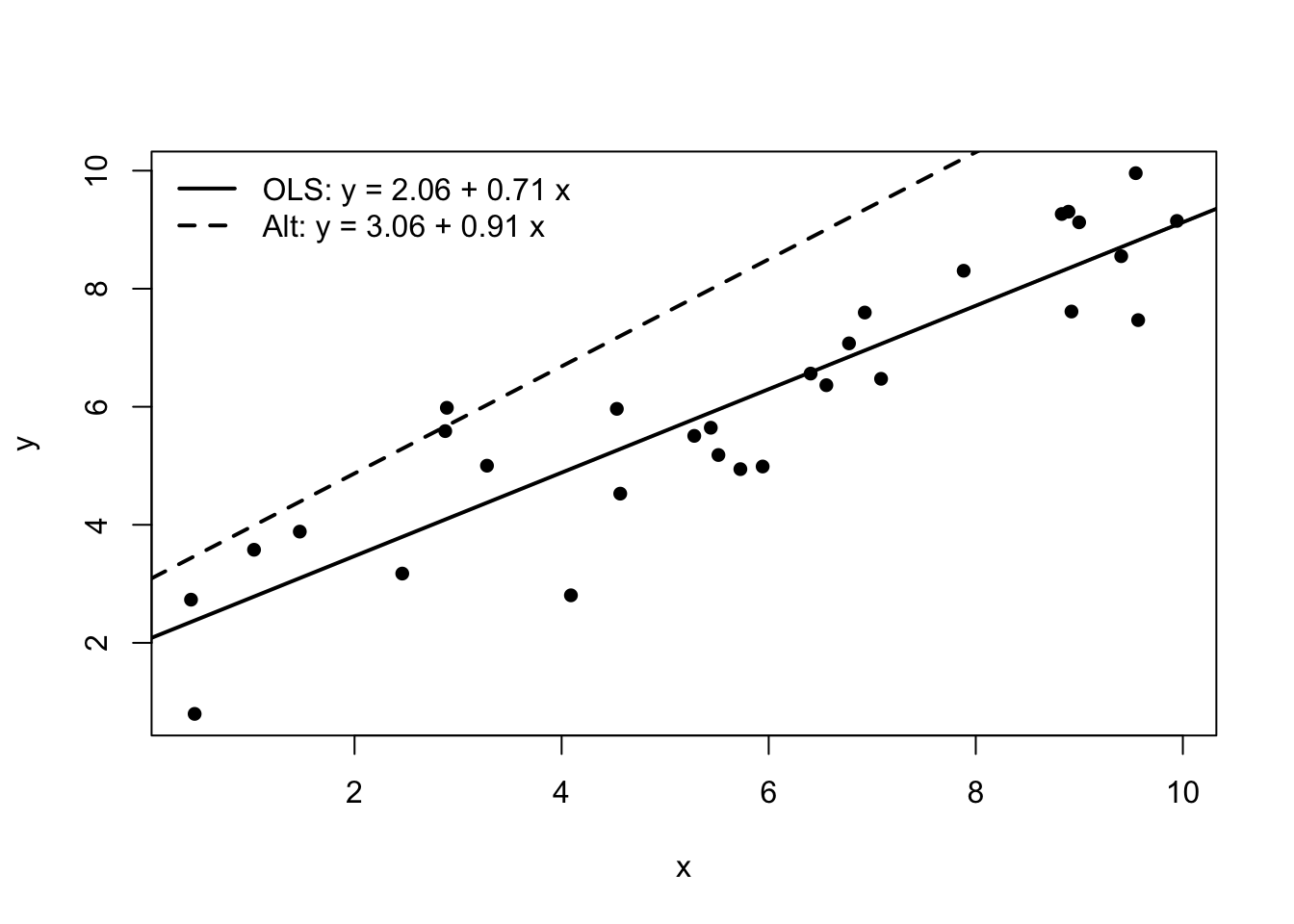
7.6.4 直線をわざとズラしてSSEを比べる
OLS直線の代わりに「少しズレた直線」を使うとSSEが大きくなるのを確認する。 たとえば切片を少し増やした直線 a=\widehat{a}+1 、傾きを少し増やした直線 b=\widehat{b}+0.2 を考える。
<- a_hat + 1 <- b_hat + 0.2 # 代替直線での予測値・残差・SSE <- a_alt + b_alt * df$ x<- df$ y - y_hat_alt<- sum (e_alt^ 2 )c (SSE_ols = SSE, SSE_alt = SSE_alt)
SSE_ols SSE_alt
27.30754 175.16007
ここで SSE_alt が SSE_ols より大きければ、
OLSが「SSEを最小にする直線」になっている
ことが数値でも確認できる。
7.6.5 図に「ズレた直線」も重ねて比較する
plot (df$ x, df$ y,xlab = "x" , ylab = "y" ,pch = 16 )# OLS直線 abline (a = a_hat, b = b_hat, lwd = 2 )# ズレた直線 abline (a = a_alt, b = b_alt, lty = 2 , lwd = 2 )legend ("topleft" ,legend = c (paste0 ("OLS: y = " , round (a_hat, 2 ), " + " , round (b_hat, 2 ), " x" ),paste0 ("Alt: y = " , round (a_alt, 2 ), " + " , round (b_alt, 2 ), " x" )lwd = 2 , lty = c (1 , 2 ), bty = "n" )
点の集まりに対して、OLS直線の方が「全体として」よく当たっている(ズレの二乗和が小さい)ことが視覚的にも確認できる。
以下の性質は、まだ「因果」や「外生性」を仮定しなくても、OLS の定義そのもの から出てくる。
OLS の性質:定義から自動的に出てくること
「OLSをSSE最小化として定義しただけで必ず成り立つ性質」をまとめる。(x_i,y_i) が与えられたら、必ずそうなる という話だけをする。
以下では、OLSで得られた係数を (\widehat{a},\widehat{b}) 、予測値と残差を
\widehat{y}_i=\widehat{a}+\widehat{b}x_i,\qquad
\widehat{e}_i=y_i-\widehat{y}_i
と書く。
(P1) 回帰直線は平均点 (\bar{x},\bar{y}) を通る
x と y の平均を
\bar{x}=\frac{1}{n}\sum_{i=1}^n x_i,\qquad
\bar{y}=\frac{1}{n}\sum_{i=1}^n y_i
とする。
このときOLSの直線は必ず
\bar{y}=\widehat{a}+\widehat{b}\bar{x}
を満たす。つまり、点 (\bar{x},\bar{y}) を通る。
直感としては「点群の重心を通る直線を探している」と思えばよい。
(P2) 残差の和は0
OLSで得られた残差は必ず
\sum_{i=1}^n \widehat{e}_i=0
を満たす。
(P3) 残差と x は「積の和」が0(直交性)
OLSで得られた残差はさらに
\sum_{i=1}^n x_i\widehat{e}_i=0
を満たす。
同じ内容を「平均からのズレ」で書き直すと
\sum_{i=1}^n (x_i-\bar{x})\widehat{e}_i=0
とも言える(こちらの方が直感に合うことが多い)。
この性質の意味はこうだ。
もし x が大きいほど残差が系統的にプラスになっているなら、傾き \widehat{b} を少し上げればSSEが下がるはず
逆に x が大きいほど残差が系統的にマイナスなら、傾き \widehat{b} を少し下げればSSEが下がるはず
OLSはSSEを最小にしているので、そのような「まだ直線を回転させたら改善できる」状態が残っていてはいけない。\sum x_i\widehat{e}_i=0 の直感になっている。
(P4) 分散分解(TSS = ESS + SSE)と R^2
まず、各点で
y_i=\widehat{y}_i+\widehat{e}_i
が成り立つ(これは定義そのもの)。
ここから、y の平均からのズレ (y_i-\bar{y}) の二乗和は
\sum_{i=1}^n (y_i-\bar{y})^2
と書ける。これを 全体のばらつき とみなす。
OLSには次の分解が成り立つ:
\sum_{i=1}^n (y_i-\bar{y})^2
=
\sum_{i=1}^n (\widehat{y}_i-\bar{y})^2
+
\sum_{i=1}^n \widehat{e}_i^2
左辺を TSS (Total Sum of Squares)、右辺の第1項を ESS (Explained Sum of Squares)、第2項を SSE (残差平方和)と呼ぶことが多い。
決定係数 R^2 を以下のように定義する
R^2
\equiv \frac{\sum_{i=1}^n (\widehat{y}_i-\bar{y})^2}{\sum_{i=1}^n (y_i-\bar{y})^2}
これは定義から明らかなように、「OLSの当てはまりの良さ」の尺度である。 先ほどの分解を使うとこれは、
R^2
=\frac{\sum_{i=1}^n (\widehat{y}_i-\bar{y})^2}{\sum_{i=1}^n (y_i-\bar{y})^2}
=1-\frac{\sum_{i=1}^n \widehat{e}_i^2}{\sum_{i=1}^n (y_i-\bar{y})^2}
と書ける。
R^2 は「y のばらつきのうち、直線(予測)で説明できた割合」を表す指標だということがわかりやすい。
(P5) 単位変更(尺度変換)に対するふるまい
x の単位を変えたとき、係数がどう変わるかを整理する。
例として、時間 x を「時間」から「分」に変えることを考える。
x_i' = 60x_i
と定義する(1時間 = 60分)。
同じデータを y を x' で回帰して
\widehat{y}_i = a' + b'x_i'
と書くと、予測値が同じになるためには
a'=\widehat{a},\qquad b'=\frac{\widehat{b}}{60}
となる。
要するに、
x を60倍(単位を細かく)すると、傾きは 1/60 倍になるただし予測値 \widehat{y}_i は変わらない(同じ直線を別の単位で書き直しただけ)
ということだ。
(P6) 平行移動(原点の取り方)に対するふるまい
次に、x に定数を足して
x_i' = x_i + c
のように「原点の取り方」だけを変えることを考える(平均との差を取る、などもこの例)。
同じデータを y を x' で回帰して
\widehat{y}_i = a' + b'x_i'
と書いたとき、予測値が同じであるためには
b'=\widehat{b},\qquad a'=\widehat{a}-\widehat{b}c
となる。
つまり、
x に定数 c を足しても、傾きは変わらないその代わり切片が調整される
という性質がある。
この性質が便利なのは、たとえば x_i-\bar{x} のように「平均からのズレ」に変換すると、切片の解釈がスッキリする点にある。x_i' = x_i-\bar{x} とすると、平均は \overline{x'}=0 なので、(P1) より
\bar{y}=\widehat{a}'
となり、「切片が y の平均そのもの」になる。
データに最もフィットする直線はもとまった。これで全て解決?
じゃないという話を今まで散々してきた。
もし被説明変数が賃金で、説明変数が教育年数なら、このOLSの結果をレポートした君のキャリアはたたれるのであった。
だからと言って、OLSはいついかなる時でもだめなのだろうか?
もちろんそうではない。例えば、Amazonがおすすめ商品リストの作成アルゴリズムを古いアルゴリズムAから新しいアルゴリズムBに変えるべきか迷っているとする。この時、AmazonほどのITシステムが整っていると、次のようなA/Bテスト を実行できる。
ユーザーの半分をランダム にグループAに、もう半分をグループBに割り振る。
グループAでのおすすめ商品リストは今のままアルゴリズムAで作成し、グループBに対しては新しいアルゴリズムBで作成する。
一定期間この状況を続け、各グループでの商品購入数を比較する。
これをOLSっぽく書くと以下のような感じになる。ユーザーをi とかく。
被説明変数が商品購入数 でこれをy_i とかく
説明変数をアルゴリズムBに切り替えたことをしめす変数 として、これをd_i とかく
すなわち、ユーザーi がグループBならd_i = 1 で、グループAならd_i = 0 である
OLSのモデルはy_i = \beta_0 + \beta_1 d_i + \epsilon_i である
ここで上記のOLSでパラメータ\beta_0,\beta_1 を推定する
この時、d_i はAmazonによって本当にランダムに割り振られている。Lecture 1で見た通り、このような「実験」の時、その効果は単なるパターンでもいい気がするのであった。
さて、
賃金と教育年数の関係
商品購入数とアルゴリズムの関係
この二つで前者はOLSじゃダメそうで、後者はOLSでも良さそう。
この二つを分ける「説明変数がランダムっぽいからOK」というのは一体どういうことなのか。今までふんわり話していたこのランダムっぽさについての話をする。
そしてそのために、識別 っていうのが一体なんなのかについてようやくちょっとだけフォーマルに話す。
ここまでで分かったのは、OLS が いちばんフィットする直線 を返すということだけである。
OLS はいつパターンではなくモデルのパラメータになるのか
回帰を走らせると「データに最もフィットする直線」は必ず求まる。全てが解決したわけではない 。
重要なのは
パターン(相関) :データの中で x が大きいと y も大きいパラメータ(因果効果) :x を外から1だけ増やしたら y がどれだけ変わるか
の違い。
OLSがいつも返してくれるのは「パターンに一番合う直線」だが、私たちが本当に欲しいのは後者の パラメータ である。
OLSはどんな時に何を識別できるか
ここでは「本当に欲しいパラメータ」を、次のモデルで x_i にかかっている係数 \beta_1
y_i=\beta_0+\beta_1 x_i + u_i
OLSで \beta_1 を識別、推定する。
「識別できる」とは?
この文脈で \beta_1 を識別できる(x_i,y_i) の出方)とモデルの仮定だけから、\beta_1 の値が 一意に定まる ことを指す。
言い換えると、同じデータの出方と両立する「別の \beta_1 」があり得ない 、という意味である。
意味がわからないと思うので、「識別できない具体例」を見る。
なんの仮定もないと識別できない
観測できるのは (x_i,y_i) だけで、誤差 u_i は見えない。仮定なしには \beta_1 は一意に決まらない ことが、数字を入れるとよく分かる。
例:3人だけのデータ
たとえば次のデータが観測されたとする:
ぱっと見ると「x が1増えると y が2増えてるっぽい」ので、真の傾きが \beta_1=2 だと主張したくなる。
仮に「真の係数」が (\beta_0,\beta_1)=(1,2) だとすると
このとき誤差は
u_i = y_i - 1 - 2x_i
だから、
u_1 = 1 - 1 - 0 = 0 u_2 = 3 - 1 - 2 = 0 u_3 = 5 - 1 - 4 = 0
つまり 誤差ゼロ でピッタリ当てはまる。
でも、別の傾きでも「誤差を作り直せてしまう」
たとえば、わざと傾きを \tilde\beta_1=1 にしてみる。\tilde\beta_0=1 のままにすると、誤差は
\tilde u_i = y_i - 1 - 1\cdot x_i
なので、
\tilde u_1 = 1 - 1 - 0 = 0 \tilde u_2 = 3 - 1 - 1 = 1 \tilde u_3 = 5 - 1 - 2 = 2
このときも
y_i = 1 + 1\cdot x_i + \tilde u_i
は 必ず成り立つ (右辺に合わせて \tilde u_i を定義しただけだから)。
見ての通り、\tilde u_i は x_i が大きいほど大きい。傾きを小さく言い過ぎた分が「x と相関する誤差」として押し込まれている 。
もっと極端に:\tilde\beta_1=0 でもいける
\tilde\beta_1=0,\ \tilde\beta_0=1 とすると
\tilde u_i = y_i - 1
だから
\tilde u_1 = 0 \tilde u_2 = 2 \tilde u_3 = 4
やっぱり
y_i = 1 + 0\cdot x_i + \tilde u_i
は完全に再現できる。
何が言いたいか
同じ (x_i,y_i) という観測データに対して、
(\beta_0,\beta_1)=(1,2) でも説明できるし(\tilde\beta_0,\tilde\beta_1)=(1,1) でも説明できるし(\tilde\beta_0,\tilde\beta_1)=(1,0) でも説明できる
ということが起きている。
違いはただ一つで、傾きを変えた分だけ、誤差 \tilde u_i が x_i と相関する形に変わる 。
だから、仮定がない状態では
「傾きが本当はどれで、どこからが誤差なのか」
をデータだけでは決められない(=\beta_1 は識別できない
識別するためにはモデルに追加の「仮定」が必要
今、モデルは
y_i = \beta_0 + \beta_1 x_i + u_i
という関数形がすでに仮定 されている。これを linear model(線形モデル) と呼ぶ。
先の例でわかったのは、linear model という仮定だけではこのモデルは識別できないということだ。
識別という強い結果を得るにはさらなる仮定が必要である。
ではどんな過程があればいいか?
識別の中心条件:E[u_i\mid x_i]=0
linear model の識別のためには、「x によって誤差の平均が偏らない」 という仮定を置くのが標準的である。すなわち、
E[u_i\mid x_i]=0
これは
x_i の値ごとに u_i の平均が偏らないつまり x_i と誤差が平均的に無関係
という縛りを入れることで、「\beta_1 をどう選んでもよい」状態を終わらせてくれる。
この縛りがあると、\beta_1 を好き勝手に動かして u_i を作り直すことができなくなり、 「データと仮定の両方に整合的な \beta_1 」が(典型的には)一意に定まるようになる。
「説明変数がランダム」の正体
A/Bテストのように x_i (あるいは処置 d_i )が本当にランダムに割り当てられていると、能力・嗜好・購買意欲などの「見えない要因」は、A群とB群で平均的に揃う。
その状況を数式にしたものが、まさに
E[u_i\mid x_i]=0
なのである。
つまり、「説明変数がランダムっぽいからOLSでも良さそう」 とは、正確には「説明変数の値によって誤差の平均が偏らないので、回帰の傾きが“単なるパターン”ではなく“因果パラメータ”として解釈できる」
以下でいくつかの例を通してこの条件が何を意味するかをもっと実感する。
シミュレーションの共通設定
真の係数:\beta_0=1,\ \beta_1=2
サンプルサイズ:n=200
繰り返し回数:R=2000
説明変数:x_i\sim N(0,1)
各実験で、誤差 u_i の作り方だけを変える。
共通のRコード(関数と設定)
set.seed (1 )# --- true parameters --- <- 1 <- 2 # --- simulation settings --- <- 200 <- 2000 # --- helper: one OLS slope/intercept from generated (x,y) --- <- function (x, y) {<- coef (lm (y ~ x))c (a_hat = unname (cf[1 ]), b_hat = unname (cf[2 ]))# --- helper: run many reps, given a generator for u (can depend on x) --- <- function (u_generator, label) {<- numeric (R)<- numeric (R)for (r in 1 : R) {<- rnorm (n, 0 , 1 )<- u_generator (x)<- beta0 + beta1 * x + u<- ols_coef (x, y)<- cf[1 ]<- cf[2 ]list (label = label, a_hat = a_hat, b_hat = b_hat)<- function (sim) {c (mean_a = mean (sim$ a_hat),mean_b = mean (sim$ b_hat),sd_a = sd (sim$ a_hat),sd_b = sd (sim$ b_hat)
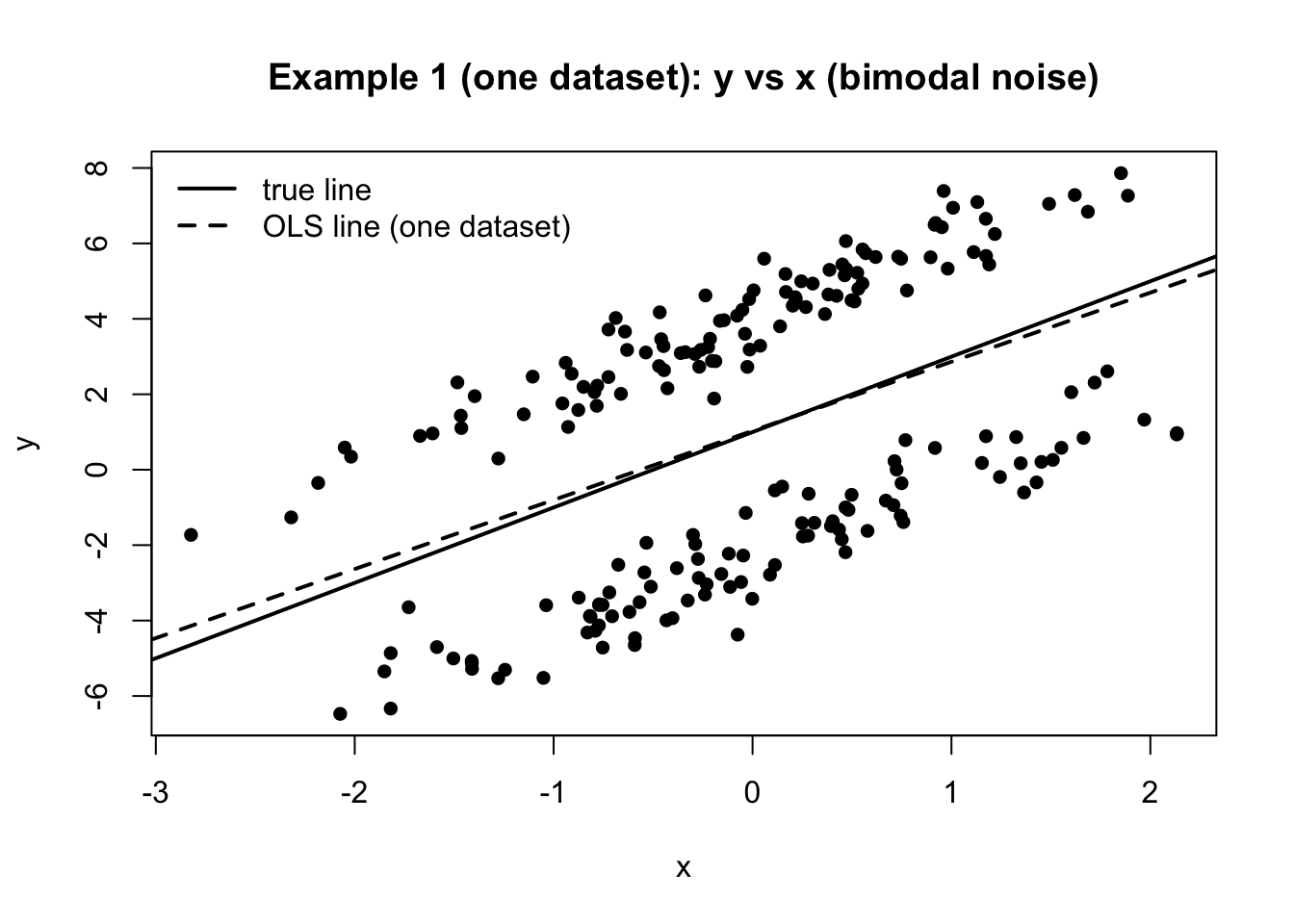
例1:ノイズの分布が正規分布じゃない時(しかも bimodal)
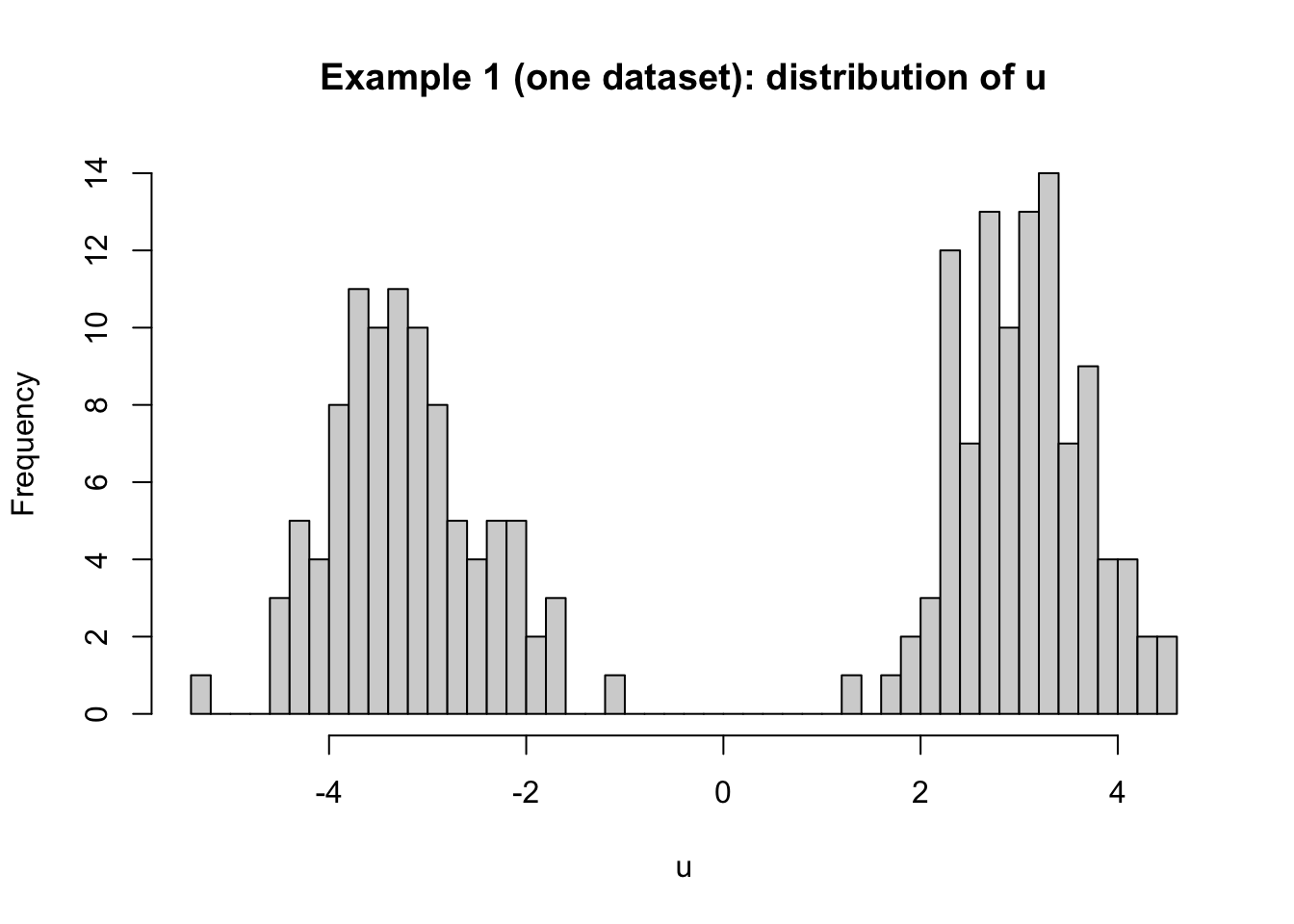
誤差 u_i が正規分布でなくても、条件 E[u_i\mid x_i]=0 が成り立つなら、OLSは \beta_1 を識別できる。二峰性(bimodal) をはっきり見せたいので、誤差を「2つの正規分布の混合(mixture)」で作る。
u_i は 正規ではない (二峰性になる)ただし x とは独立で、平均は0(外生性が成り立つ)
具体的には、確率 1/2 で +m の周り、確率 1/2 で -m の周りに誤差が出るようにする:
u_i=
\begin{cases}
m+\varepsilon_i & \text{with prob } 1/2 \\
-m+\varepsilon_i & \text{with prob } 1/2
\end{cases}
\qquad (\varepsilon_i\sim N(0,\sigma^2))
このとき E[u_i]=0 なので E[u_i\mid x_i]=0 が成り立つ。
まず1回だけ図示
set.seed (101 )# 1回分のデータを作る(図示用) <- rnorm (n, 0 , 1 )<- 3 # 2つの山の中心(±m) <- 0.7 # 各山の広がり <- sample (c (- 1 , 1 ), size = n, replace = TRUE ) # -1 or +1 を等確率で <- s * m + rnorm (n, 0 , sigma)<- beta0 + beta1 * x + u# 散布図:y vs x plot (x, y, pch = 16 ,xlab = "x" , ylab = "y" ,main = "Example 1 (one dataset): y vs x (bimodal noise)" )# 真の直線 abline (a = beta0, b = beta1, lwd = 2 )# OLS直線(この1回分) <- lm (y ~ x)abline (fit_one, lwd = 2 , lty = 2 )legend ("topleft" ,legend = c ("true line" , "OLS line (one dataset)" ),lwd = 2 , lty = c (1 , 2 ), bty = "n" )# 誤差uの分布(本当に二峰性か確認) hist (u, breaks = 40 ,main = "Example 1 (one dataset): distribution of u" ,xlab = "u" )
推定
「サンプルを作って、OLSを計算する」というのをたくさんやる。
出てくるサンプルごとにOLSの値は異なるので、一回こっきりのOLSがパラメータに近くても、それはたまたまかもしれない。
この懸念を払拭するため、何回も異なるサンプルからOLSを計算して、その結果がどのように分布するのかをみるのが、推定量がパラメータをちゃんと識別できているのかをチェックするために効果的である。
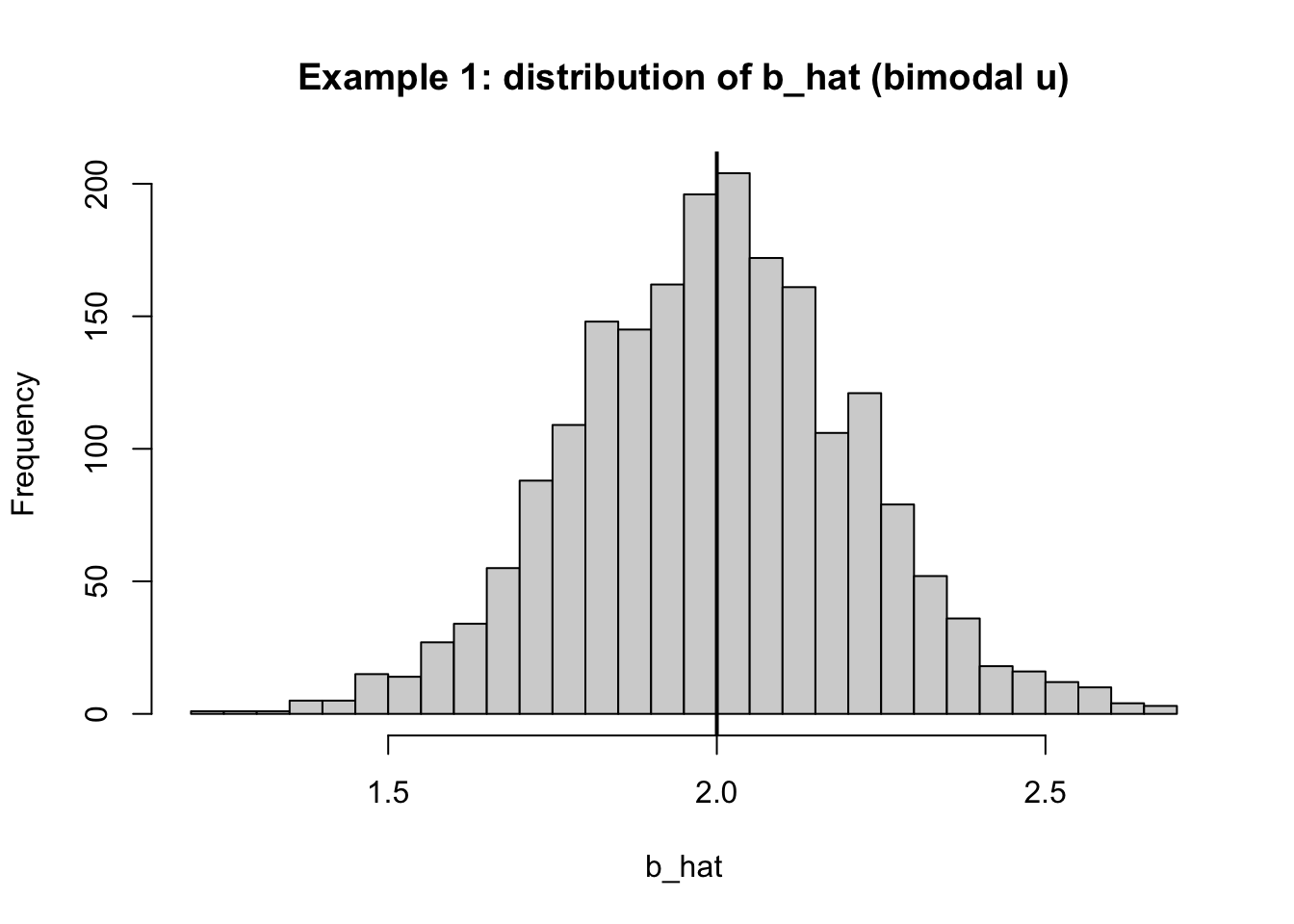
# bimodal error generator: mixture of two normals centered at ±m <- 3 <- 0.7 <- run_sim (u_generator = function (x) {<- sample (c (- 1 , 1 ), size = length (x), replace = TRUE )* m + rnorm (length (x), 0 , sigma)label = "Example 1: non-normal u (bimodal mixture), E[u|x]=0 holds" # b_hatの分布 hist (sim1$ b_hat, breaks = 40 ,main = "Example 1: distribution of b_hat (bimodal u)" ,xlab = "b_hat" )abline (v = beta1, lwd = 2 )
解説
誤差が正規である必要はない。重要なのは 平均的に x と無関係 (E[u\mid x]=0 )であることだ。 非正規だと外れ値が出やすく、推定値の分布が裾の厚い形になりやすいが、中心は \beta_1 の近くに来る。
例2:ノイズの分布の平均が 0 じゃない時
誤差の平均が0でないと聞くと「OLSが壊れそう」に見えるが、平均が一定のズレ (全員に同じ上乗せ)なら傾きは壊れない。 代わりに切片がそのズレを吸収する。
ここでは
u_i=c+v_i,\qquad E[v_i]=0
として c=1 を入れる。
E[u_i\mid x_i]=1 (0ではない)しかし x に依存しない一定ズレなので、傾きは識別できる
切片は \beta_0+c にズレる
Rコード(平均が0でないが一定)
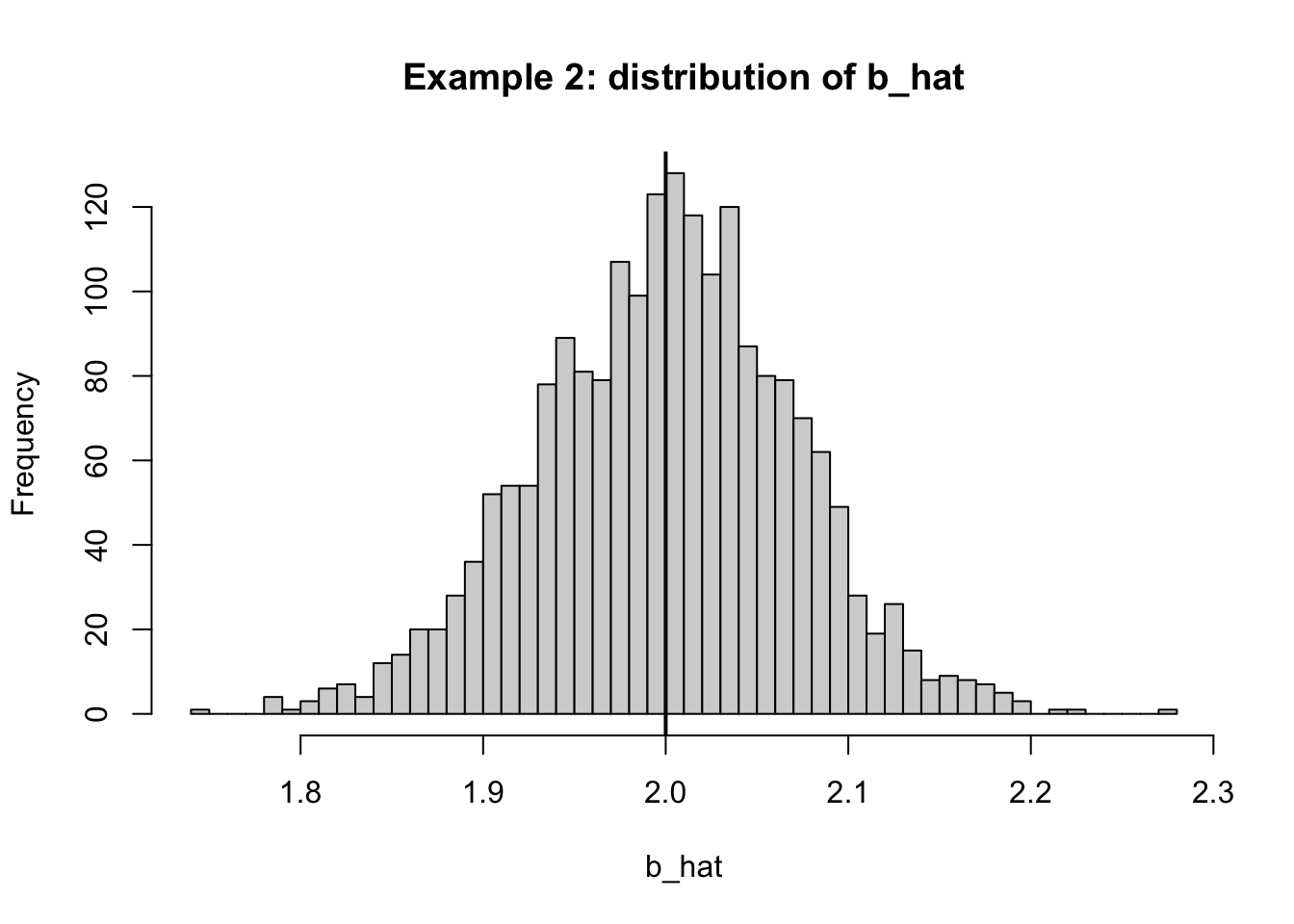
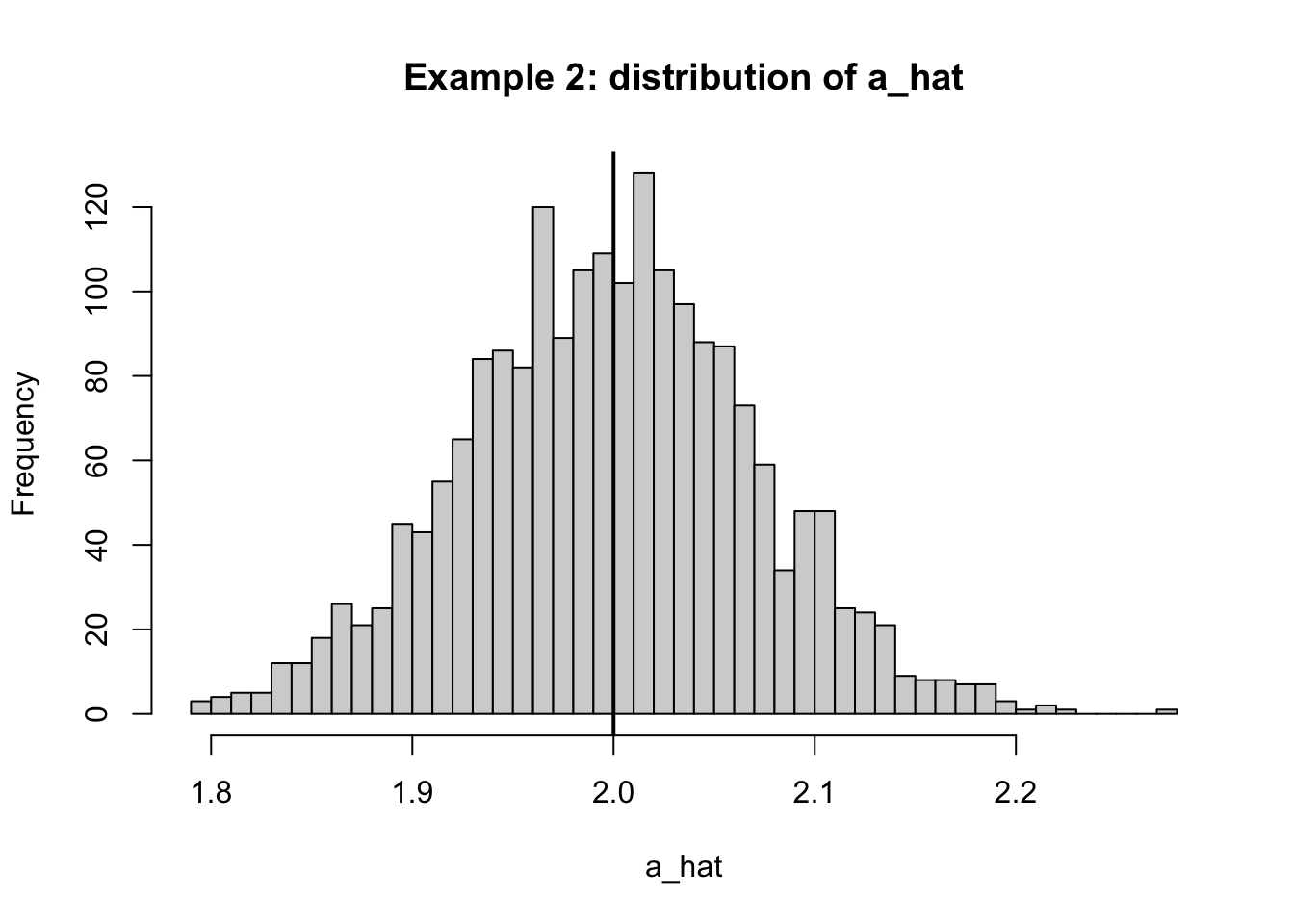
<- 1 <- run_sim (u_generator = function (x) c0 + rnorm (length (x), 0 , 1 ),label = "Example 2: E[u]=1 constant shift" summarize_sim (sim2)
mean_a mean_b sd_a sd_b
1.99815139 1.99998300 0.07201228 0.07020900
図で確認(切片と傾き)
hist (sim2$ b_hat, breaks = 40 ,main = "Example 2: distribution of b_hat" ,xlab = "b_hat" )abline (v = beta1, lwd = 2 )hist (sim2$ a_hat, breaks = 40 ,main = "Example 2: distribution of a_hat" ,xlab = "a_hat" )abline (v = beta0 + c0, lwd = 2 )
解説
u の平均が0でないこと自体が「即、傾きの識別失敗」を意味しない。 一定の平均ズレ は切片が吸収するので、傾き \beta_1 は平均的に正しく推定される。
例3:ノイズの分布が説明変数に依存する時
「依存する」の中身で話が変わる。
(3A) 分散だけが x に依存(不均一分散 ) E[u\mid x]=0 が成り立つなら傾きの識別は基本壊れない(ただし標準誤差の扱いが重要)。
(3B) 平均が x に依存(内生性 ) E[u\mid x]\neq 0 となり、傾きの識別が壊れる(バイアスが出る)。
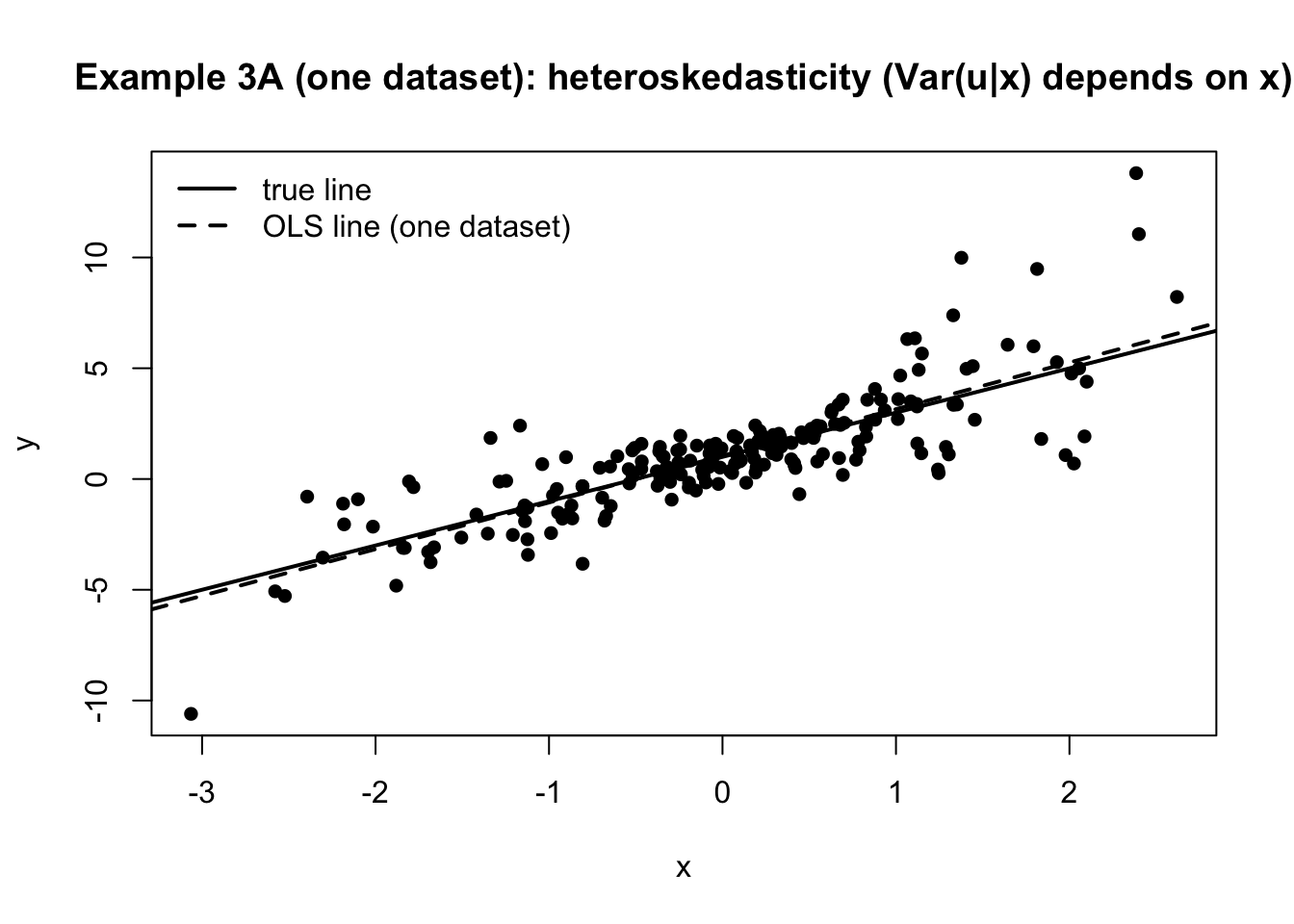
例3A:分散が x に依存する(不均一分散)
u_i = \sigma(x_i)v_i,\qquad E[v_i\mid x_i]=0
たとえば \sigma(x)=0.5+|x| とすると、x が大きいほど誤差の散らばりが増える。
散布図と一回だけOLS
set.seed (201 )# 1回分のデータ(図示用) <- rnorm (n, 0 , 1 )<- 0.5 + abs (x) # 分散(正確には標準偏差)がxに依存 <- sigma_x * rnorm (n, 0 , 1 )<- beta0 + beta1 * x + u# 散布図 + 真の直線 + OLS直線(この1回分) plot (x, y, pch = 16 ,xlab = "x" , ylab = "y" ,main = "Example 3A (one dataset): heteroskedasticity (Var(u|x) depends on x)" )abline (a = beta0, b = beta1, lwd = 2 ) # 真の直線 <- lm (y ~ x)abline (fit_one, lwd = 2 , lty = 2 ) # 1回こっきりOLS legend ("topleft" ,legend = c ("true line" , "OLS line (one dataset)" ),lwd = 2 , lty = c (1 , 2 ), bty = "n" )
Rコード(分散だけが依存)
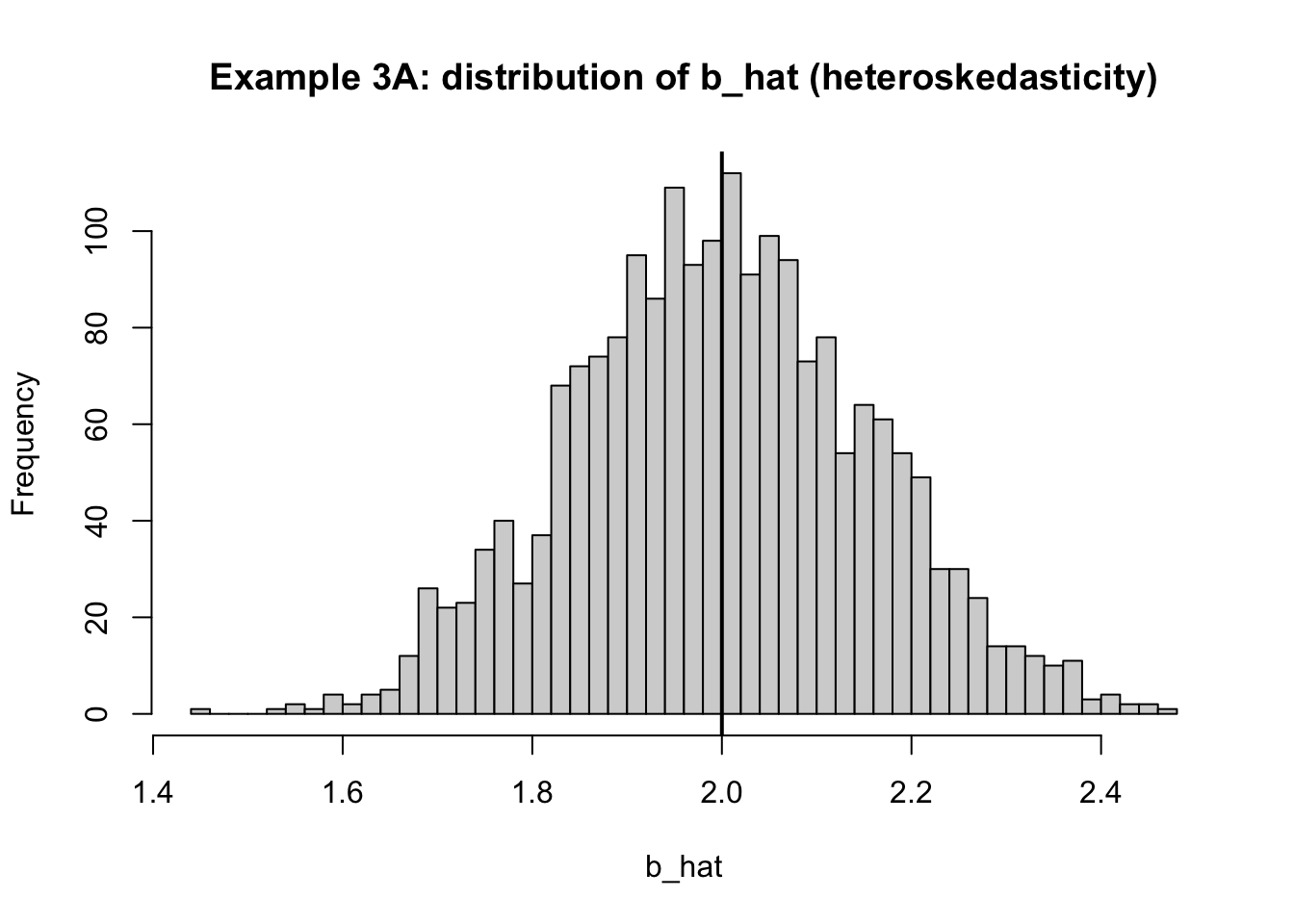
<- run_sim (u_generator = function (x) (0.5 + abs (x)) * rnorm (length (x), 0 , 1 ),label = "Example 3A: variance depends on x (heteroskedasticity)" summarize_sim (sim3A)
mean_a mean_b sd_a sd_b
0.99967608 1.99815642 0.09960058 0.15655209
図で確認(傾きの中心はだいたい合う)
hist (sim3A$ b_hat, breaks = 40 ,main = "Example 3A: distribution of b_hat (heteroskedasticity)" ,xlab = "b_hat" )abline (v = beta1, lwd = 2 )
解説(参考)
E[u\mid x]=0 が保たれている限り、傾きの中心は概ね \beta_1 にある。 ただし不均一分散は「推論」パートで注意が必要である。これについては後述。
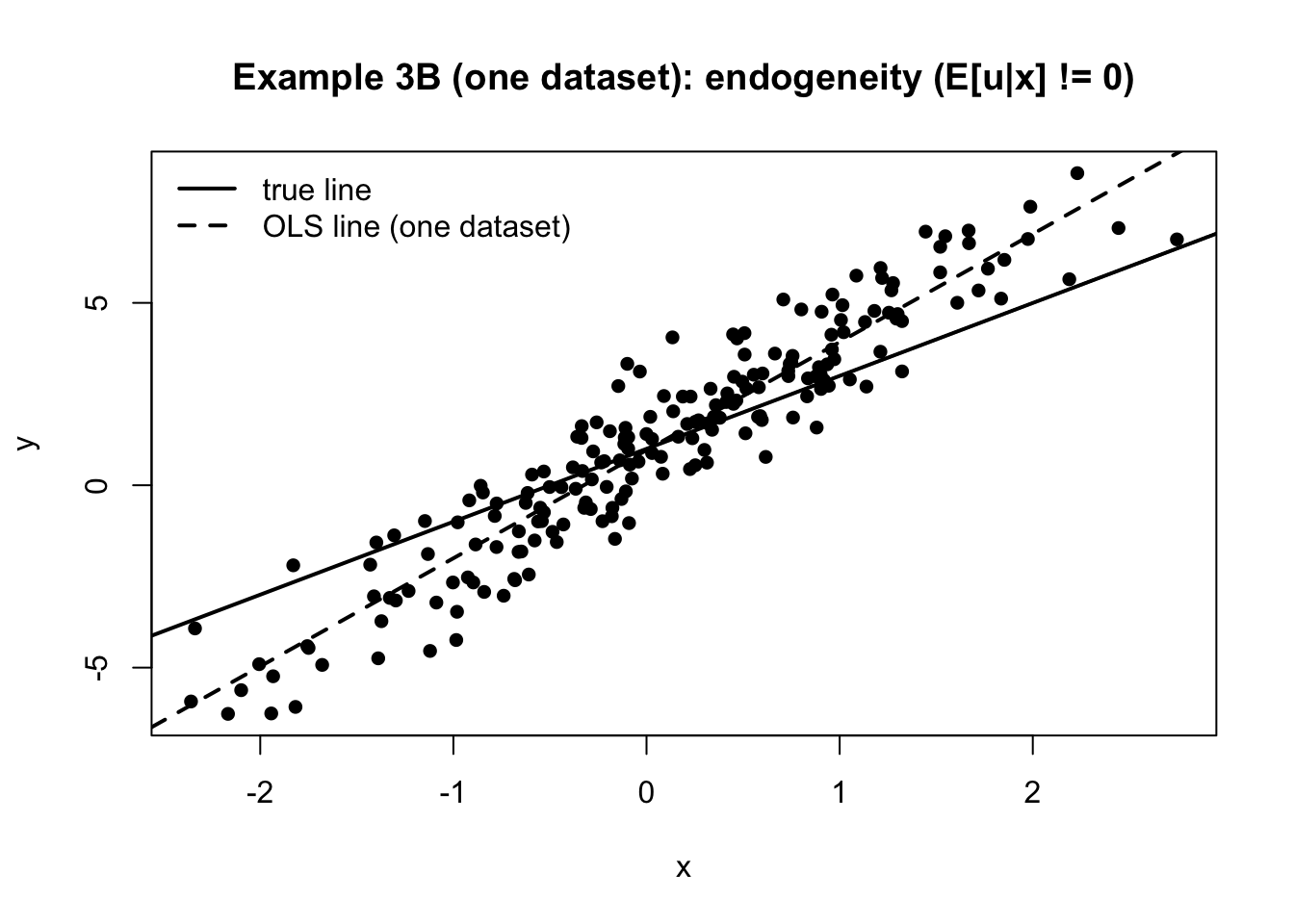
例3B:平均が x に依存する(内生性の最小例)
u_i = \rho x_i + v_i,\qquad E[v_i\mid x_i]=0
とすると
E[u_i\mid x_i]=\rho x_i
となり外生性が破れる。するとOLSの傾きはズレる。
散布図と一回だけOLS
set.seed (202 )# 1回分のデータ(図示用) <- rnorm (n, 0 , 1 )<- 1.0 <- rho * x + rnorm (n, 0 , 1 )<- beta0 + beta1 * x + u# 散布図 + 真の直線 + OLS直線(この1回分) plot (x, y, pch = 16 ,xlab = "x" , ylab = "y" ,main = "Example 3B (one dataset): endogeneity (E[u|x] != 0)" )abline (a = beta0, b = beta1, lwd = 2 ) # 真の直線 <- lm (y ~ x)abline (fit_one, lwd = 2 , lty = 2 ) # 1回こっきりOLS legend ("topleft" ,legend = c ("true line" , "OLS line (one dataset)" ),lwd = 2 , lty = c (1 , 2 ), bty = "n" )
Rコード(平均が x に依存)
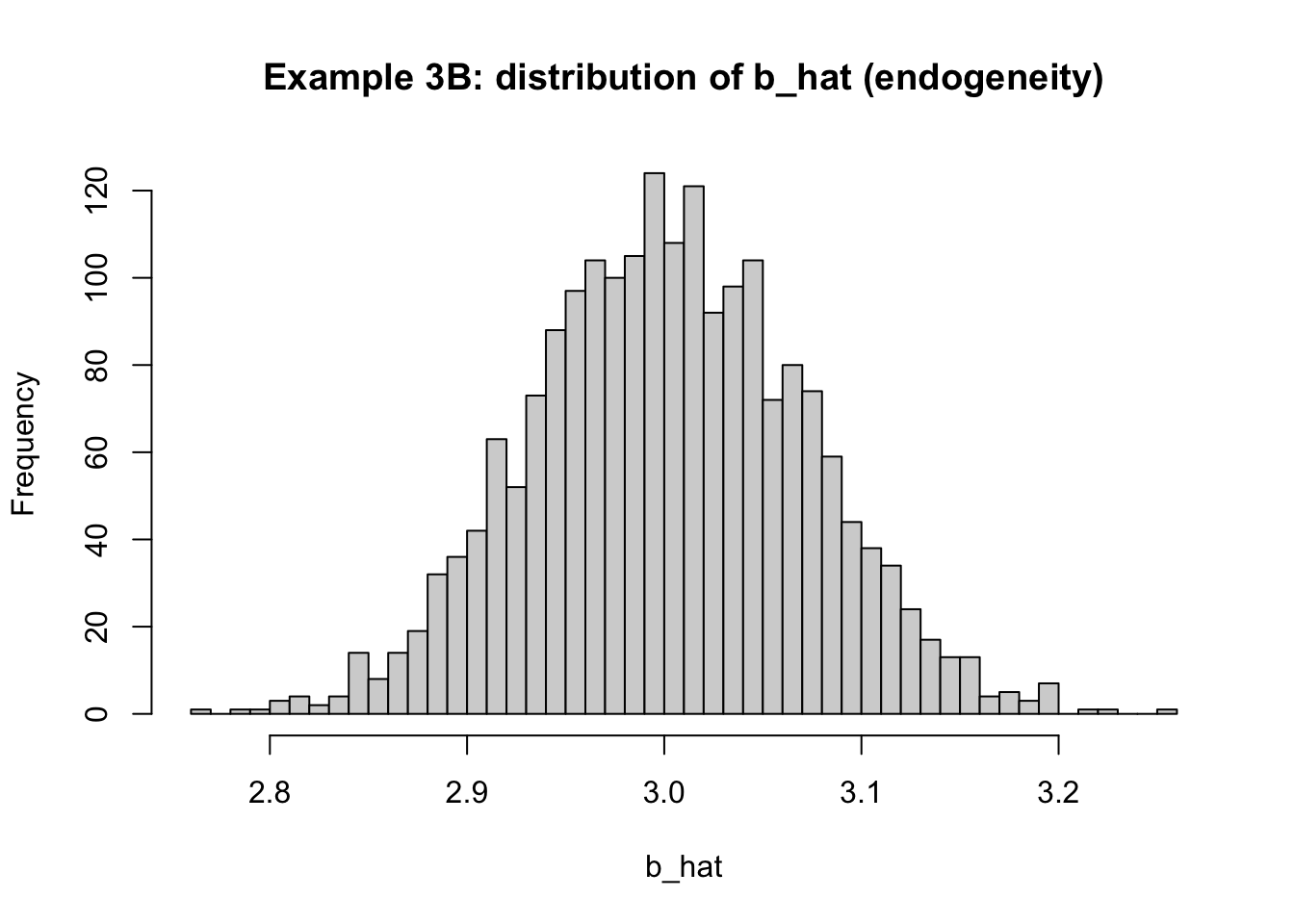
<- 1.0 <- run_sim (u_generator = function (x) rho * x + rnorm (length (x), 0 , 1 ),label = "Example 3B: mean depends on x (endogeneity)" summarize_sim (sim3B)
mean_a mean_b sd_a sd_b
1.00082801 3.00217339 0.06955953 0.06961053
図で確認(傾きがズレる)
hist (sim3B$ b_hat, breaks = 40 ,main = "Example 3B: distribution of b_hat (endogeneity)" ,xlab = "b_hat" )abline (v = beta1, lwd = 2 )
解説
u に \rho x が混ざると、y の中で x と一緒に動く部分が誤差にも入ってしまう。 OLSはそれを傾きとして回収するので、本来の \beta_1 に加えて \rho の分まで拾い、傾きがズレる。
例4:ノイズがサンプル間で相関するとき(時系列っぽい誤差)
ここまでは「各サンプル i の誤差 u_i は、別のサンプル j の誤差とは関係ない(独立っぽい)」という状況を暗黙に想定していた。
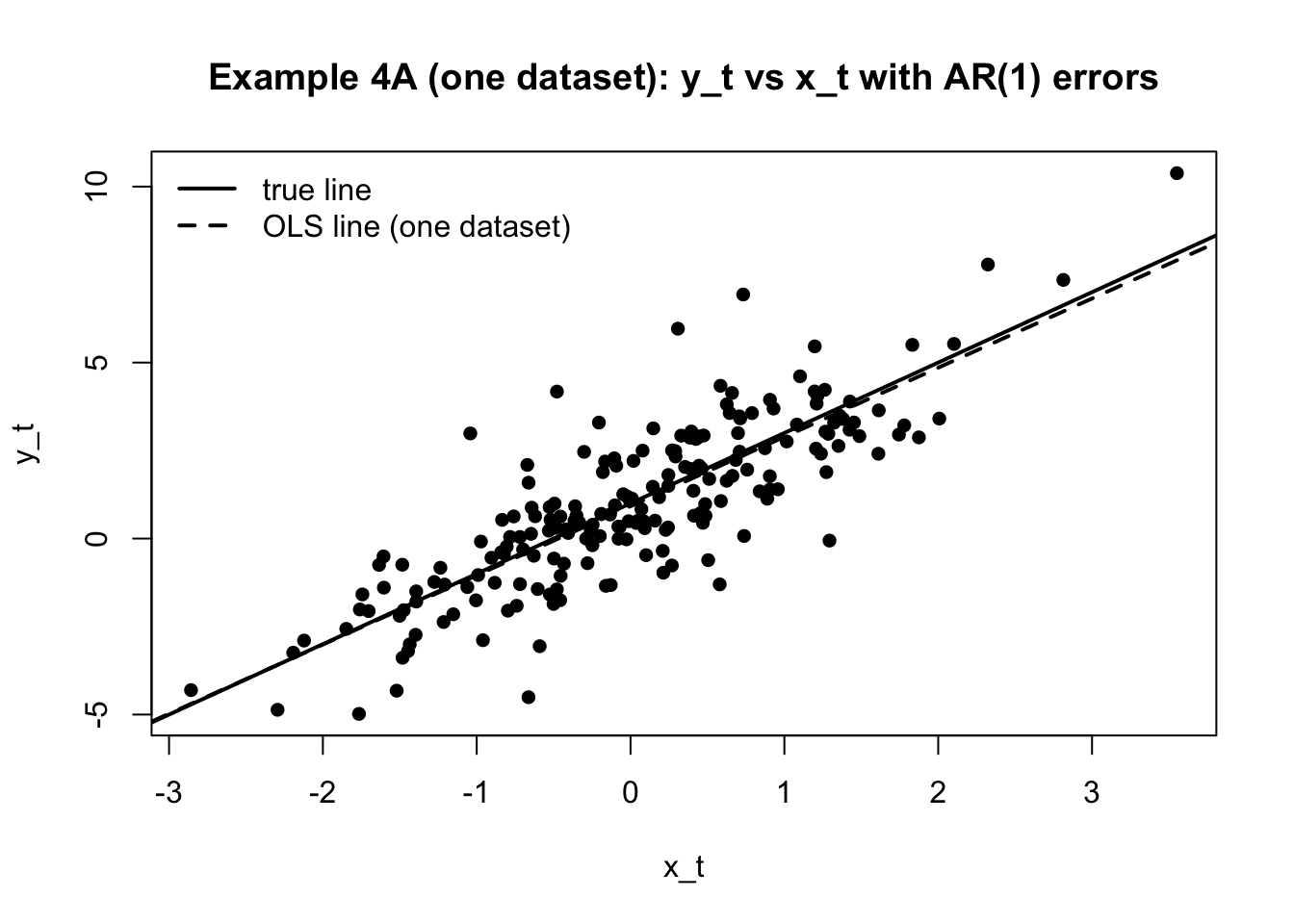
典型例は AR(1) で、誤差が
u_t=\rho u_{t-1}+\varepsilon_t,\qquad |\rho|<1
のように「前期の誤差を引きずる」形になる。ここで \varepsilon_t は平均0のショックだ。
このときx_t と誤差の平均が無関係(外生性)なら、傾きは概ね識別できる
モデルは
y_t=\beta_0+\beta_1 x_t + u_t
で、x_t は誤差と独立に作る。誤差 u_t はAR(1)にする。
このとき、OLSの傾き \widehat{b} は平均的には \beta_1 の近くに来るはずだ。
散布図と一回こっきりのOLS
set.seed (301 )# ----------------------------- # settings # ----------------------------- <- n # 既に n <- 200 を使っている想定 <- 0.7 <- 1 # ----------------------------- # generate one dataset # ----------------------------- <- 1 : n_ts# x_t is exogenous <- rnorm (n_ts, 0 , 1 )# AR(1) error: u_t = rho u_{t-1} + eps_t <- rnorm (n_ts, 0 , sigma_eps)<- numeric (n_ts)1 ] <- eps[1 ]for (k in 2 : n_ts) {<- rho_ar * u[k-1 ] + eps[k]# outcome <- beta0 + beta1 * x + u# one-shot OLS <- lm (y ~ x)# ----------------------------- # show coefficients (optional) # ----------------------------- coef (fit_one)
(Intercept) x
0.9221826 1.9661574
# ----------------------------- # plots # ----------------------------- # (1) time series of u_t plot (t, u, type = "l" ,xlab = "t" , ylab = "u_t" ,main = "Example 4A (one dataset): AR(1) errors u_t" )# (2) time series of y_t plot (t, y, type = "l" ,xlab = "t" , ylab = "y_t" ,main = "Example 4A (one dataset): y_t over time" )# (3) scatter + true line + OLS line plot (x, y, pch = 16 ,xlab = "x_t" , ylab = "y_t" ,main = "Example 4A (one dataset): y_t vs x_t with AR(1) errors" )abline (a = beta0, b = beta1, lwd = 2 ) # true line abline (fit_one, lwd = 2 , lty = 2 ) # OLS line (one dataset) legend ("topleft" ,legend = c ("true line" , "OLS line (one dataset)" ),lwd = 2 , lty = c (1 , 2 ), bty = "n" )
Rコード(AR(1)誤差でOLS)
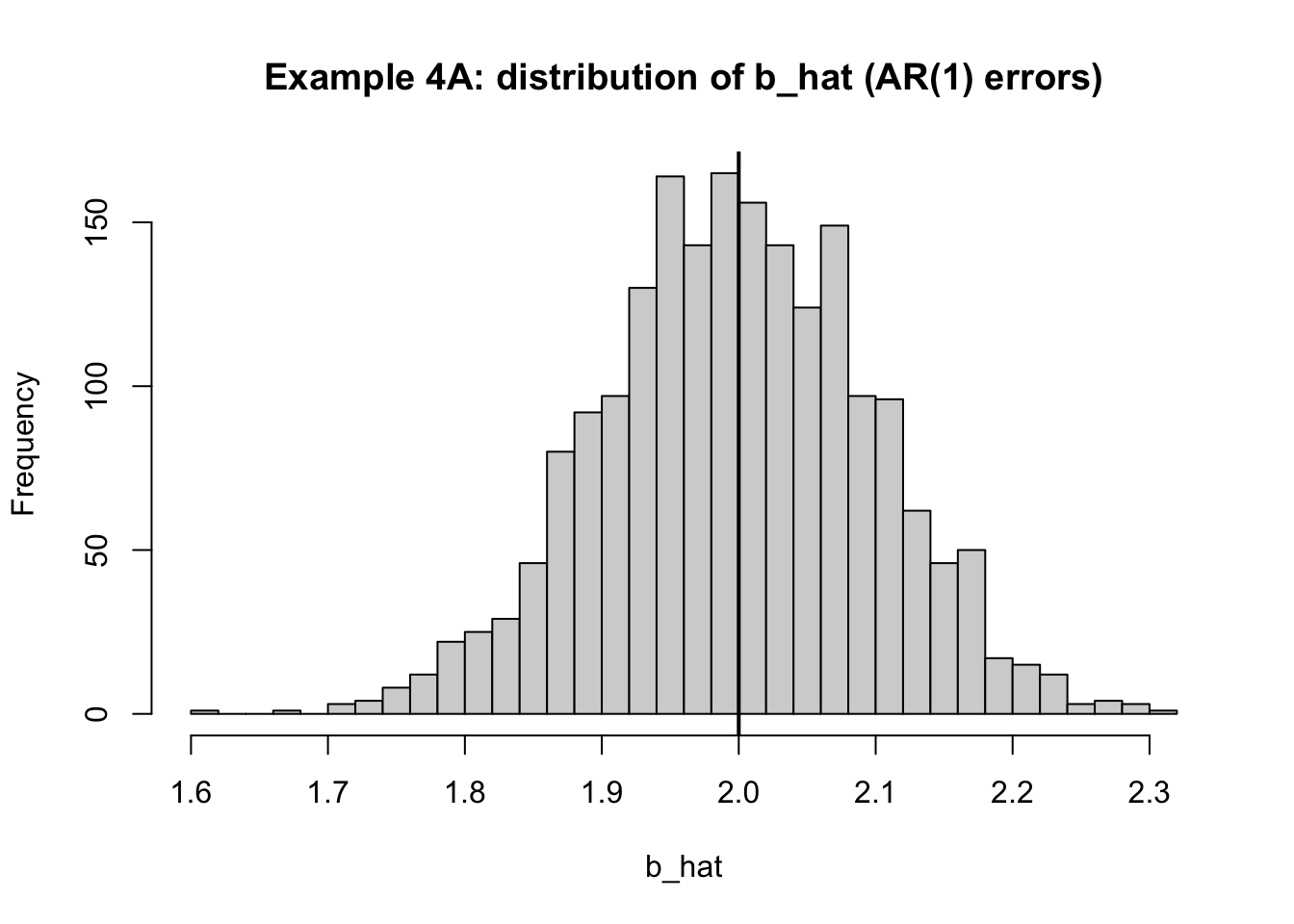
<- 0.7 # 誤差の自己相関 <- 1 # ショックの標準偏差 <- run_sim (u_generator = function (x) {# AR(1): u_t = rho u_{t-1} + eps_t <- rnorm (length (x), 0 , sigma_eps)<- numeric (length (x))1 ] <- eps[1 ]for (t in 2 : length (x)) {<- rho_ar * u[t-1 ] + eps[t]label = "Example 4A: serially correlated u (AR(1)), exogeneity holds" summarize_sim (sim4A)
mean_a mean_b sd_a sd_b
1.00056564 1.99820675 0.22907897 0.09860308
図で確認(傾きの推定値の分布)
hist (sim4A$ b_hat, breaks = 40 ,main = "Example 4A: distribution of b_hat (AR(1) errors)" ,xlab = "b_hat" )abline (v = beta1, lwd = 2 )
解説
誤差がサンプル間で相関していても、x_t と誤差の平均が無関係(E[u_t\mid x_t]=0 )なら、傾きは概ね狙える。
ただし誤差の相関は「推論」に効く。独立を仮定した標準誤差はだいたい間違う。 時系列だとHAC(Newey-West)みたいな標準誤差が必要、という話に繋がる。
以下の不偏性・分散・一致性・漸近正規性は、E[u_i \mid x_i]=0 などの仮定の下で
OLS の性質:推定量としての性質
欲しいパラメータを識別できているなら、OLS は「推定量」として妥当である。ここで述べる性質は、OLS の定義から直接導かれるものではなく、
E[u_i \mid x_i] = 0
という仮定の下で成立する性質である。
以下では、OLS 推定量を
\hat\beta_1=\frac{\sum_{i=1}^n (x_i-\bar x)(y_i-\bar y)}{\sum_{i=1}^n (x_i-\bar x)^2}
と書き、この推定量の性質を見ていく。
ここでのメッセージは、OLS はかなり扱いやすく、強い性質を持つ推定量である 、ということである。 ## 1. 不偏性(平均的に当たる)
E[u_i\mid x_i]=0 が成り立つとき、OLSは平均的に正しい 。
直感はこうだ:
y_i=\beta_0+\beta_1 x_i+u_i なので、OLSが見ている y のブレには u が混ざっているしかし E[u_i\mid x_i]=0 なら、x の大きさによって u が平均的に偏らない
その結果、x と y の共変動は「\beta_1 x の部分」から来るものとして回収できる
よりフォーマルには、
E[\hat\beta_1]=\beta_1
が成り立つ。
これを不偏性と呼ぶ。
先ほどのシミュレーションで、「一回こっきりのOLSではたまたまその結果かもしれないから何度もOLSをやって、その度に得られるOLSの結果をヒストグラムにした」ことを思い出そう。
あのヒストグラムが「本当の\beta_1 」に山の中心を持つようなグラフの時、平均的にはOLSは正しい値である ということで、これこそ不偏性である。
2. 分散と標準誤差の公式がある
推定値にはブレがある。ブレの大きさは概ね
誤差 u_i がどれくらい大きいか(ノイズが強いか)
x_i がどれくらい散らばっているか(説明変数の情報量があるか)サンプルサイズ n がどれくらい大きいか
で決まる。
特に重要な直感は:
x の分散が大きいほど、傾きは精密に推定できるn が大きいほど、標準誤差は小さくなる
である。これらはどちらも直感的に「推定量ならこうあってほしい」という性質で、OLSはこれらを満たす。
さらに、OLSの分散は以下のように直接計算することができる。
2.1 OLSの推定量を「誤差の重み付き平均」として書く
まず、単回帰(切片あり)では
\hat\beta_1=\frac{\sum_{i=1}^n (x_i-\bar x)(y_i-\bar y)}{\sum_{i=1}^n (x_i-\bar x)^2}
である。真のモデル y_i=\beta_0+\beta_1 x_i+u_i を代入すると
\hat\beta_1-\beta_1
=\frac{\sum_{i=1}^n (x_i-\bar x)u_i}{\sum_{i=1}^n (x_i-\bar x)^2}.
つまり、OLSの誤差は「u_i の重み付き平均」になっている。
重みは (x_i-\bar x) であり、x が平均から離れている観測ほど、傾きの推定に強く効く。
2.2 条件付き分散(x を固定して見た分散)
ここで x_1,\dots,x_n を固定したときの分散(条件付き分散)を考える。
追加の仮定として、誤差が
\mathrm{Var}(u_i\mid x_i)=\sigma^2 (同分散)\mathrm{Cov}(u_i,u_j\mid x)=0 \ (i\neq j) (相関なし)
を満たすとしよう(いわゆる 古典的仮定 )。
このとき
\mathrm{Var}(\hat\beta_1\mid x)
= \mathrm{Var}\!\left(
\frac{\sum_{i=1}^n (x_i-\bar x)u_i}{\sum_{i=1}^n (x_i-\bar x)^2}
\ \middle|\ x\right)
= \frac{\sigma^2}{\sum_{i=1}^n (x_i-\bar x)^2}.
これが単回帰OLSの分散の基本公式である。
2.3 直感の確認:「x が散らばるほど小さくなる」「n が増えるほど小さくなる」
上の式から、
分母に \sum (x_i-\bar x)^2 が入っているx がよく散らばっている(情報量が多い)ほど分散が小さい
典型的には \sum (x_i-\bar x)^2 は n に比例して大きくなる
がそのまま読める。
2.4 標準誤差:\sigma^2 は未知なので推定して代入する
分散公式には \sigma^2 が出てくるが、これは未知なのでデータから推定する。
まず残差を
\hat u_i = y_i-\hat\beta_0-\hat\beta_1 x_i
と定義し、誤差分散を
\hat\sigma^2=\frac{1}{n-2}\sum_{i=1}^n \hat u_i^2
で推定する(自由度が n-2 なのは、\beta_0,\beta_1 の2つを推定した分だけ「使った」から)。
ここで\frac{1}{n} とかにすると、不偏性がなくなる。
すると、\hat\beta_1 の分散推定量は
\widehat{\mathrm{Var}}(\hat\beta_1\mid x)
=\frac{\hat\sigma^2}{\sum_{i=1}^n (x_i-\bar x)^2}.
そして 標準誤差(standard error) は、この平方根:
\mathrm{se}(\hat\beta_1)
=\sqrt{\widehat{\mathrm{Var}}(\hat\beta_1\mid x)}
=\sqrt{\frac{\hat\sigma^2}{\sum_{i=1}^n (x_i-\bar x)^2}}.
なぜ分母が n-2 なのか
単回帰(切片あり)
y_i=\beta_0+\beta_1 x_i+u_i
を考える。OLS推定値 (\hat\beta_0,\hat\beta_1) による残差を
\hat u_i \equiv y_i-\hat\beta_0-\hat\beta_1 x_i
と書く。
ここで重要なのは、OLSは残差平方和
S(\beta_0,\beta_1)=\sum_{i=1}^n (y_i-\beta_0-\beta_1 x_i)^2
を最小化していることだ。
ステップ1:OLSの一階条件(正規方程式)
最小化の一階条件は
\frac{\partial S}{\partial \beta_0}= -2\sum_{i=1}^n (y_i-\hat\beta_0-\hat\beta_1 x_i)= -2\sum_{i=1}^n \hat u_i =0
\frac{\partial S}{\partial \beta_1}= -2\sum_{i=1}^n x_i (y_i-\hat\beta_0-\hat\beta_1 x_i)= -2\sum_{i=1}^n x_i\hat u_i =0
つまり
\sum_{i=1}^n \hat u_i =0,\qquad \sum_{i=1}^n x_i\hat u_i=0
が成り立つ(残差は「定数」と「x 」に直交する)。
ステップ2:残差を真の誤差で書き直す
真のモデル y_i=\beta_0+\beta_1 x_i+u_i を使うと
\hat u_i
= y_i-\hat\beta_0-\hat\beta_1 x_i
= u_i-(\hat\beta_0-\beta_0)-(\hat\beta_1-\beta_1)x_i.
ここで
a\equiv \hat\beta_0-\beta_0,\qquad b\equiv \hat\beta_1-\beta_1
と置けば
\hat u_i=u_i-a-bx_i.
ステップ3:SSE(残差平方和)を展開する
残差平方和(SSE)は \begin{align*}
\sum_{i=1}^n \hat u_i^2 &=\sum_{i=1}^n (u_i-a-bx_i)^2\\
&=\sum_{i=1}^n u_i^2 \;-\;2a\sum_{i=1}^n u_i \;-\;2b\sum_{i=1}^n x_i u_i
\;+\; a^2 n \;+\;2ab\sum_{i=1}^n x_i \;+\; b^2\sum_{i=1}^n x_i^2.
\end{align*}
ここでポイントは、OLSの一階条件 を真の誤差 u_i で書き直せること。
実際、\sum \hat u_i=0 と \sum x_i\hat u_i=0 に \hat u_i=u_i-a-bx_i を代入すると
\sum_{i=1}^n u_i = an + b\sum_{i=1}^n x_i,
\sum_{i=1}^n x_i u_i = a\sum_{i=1}^n x_i + b\sum_{i=1}^n x_i^2.
これをさっきのSSE展開式に代入すると、交差項がきれいに消えて
\sum_{i=1}^n \hat u_i^2
=\sum_{i=1}^n u_i^2 \;-\;\Big( a^2 n + 2ab\sum_{i=1}^n x_i + b^2\sum_{i=1}^n x_i^2 \Big).
つまり > SSE は「真の誤差の二乗和」から、a,b (2つの推定でフィットした分)だけ確実に差し引かれる。
ステップ4:期待値を取る(ここで初めて確率の仮定)
古典的仮定の下で(特に E[u_i\mid x_i]=0 と同分散)
E\!\left[\sum_{i=1}^n u_i^2 \mid x\right]=n\sigma^2.
また少し計算すると(ここは結論だけ覚えればOK)
E\!\left[a^2 n + 2ab\sum x_i + b^2\sum x_i^2 \mid x\right]=2\sigma^2.
よって
E\!\left[\sum_{i=1}^n \hat u_i^2 \mid x\right]
= n\sigma^2 - 2\sigma^2
= (n-2)\sigma^2.
結論:1/(n-2) なら不偏、1/n だと下に偏る
したがって
\hat\sigma^2=\frac{1}{n-2}\sum_{i=1}^n \hat u_i^2
は
E[\hat\sigma^2\mid x]=\sigma^2
を満たす(不偏)。
一方で
\tilde\sigma^2=\frac{1}{n}\sum_{i=1}^n \hat u_i^2
だと
E[\tilde\sigma^2\mid x]=\frac{n-2}{n}\sigma^2
となり、下方バイアス になる。
(ただし n が大きいと (n-2)/n\approx1 なので、実務上の違いは小さくなる。)
ここまでの二つの性質はデータの数、つまりサンプル数 が固定されている時の性質。
ここから先二つはサンプル数を増やすと良いことがある という性質。
3. 一致性(サンプルが増えると真値に近づく)
正直不偏かどうか以上に重要なのが 一致性 である。
\hat\beta_1 \xrightarrow[]{p} \beta_1 \qquad (n\to\infty)
つまり、データが大量に集まれば、OLSの推定値は確率的に真の \beta_1 に近づく。
E[u_i\mid x_i]=0 により「誤差の偏り」が平均的に打ち消されるn が増えるほどその打ち消しが効いてくる
というイメージで理解してよい。
今の知識で一致性の主張を正確に理解することは無理なので、データがいっぱいあると平均的にどころか、確実に真のパラメータの値に近くなる と思っておこう。
図で見る一致性(1):サンプルを1つずつ足したときの OLS の軌跡
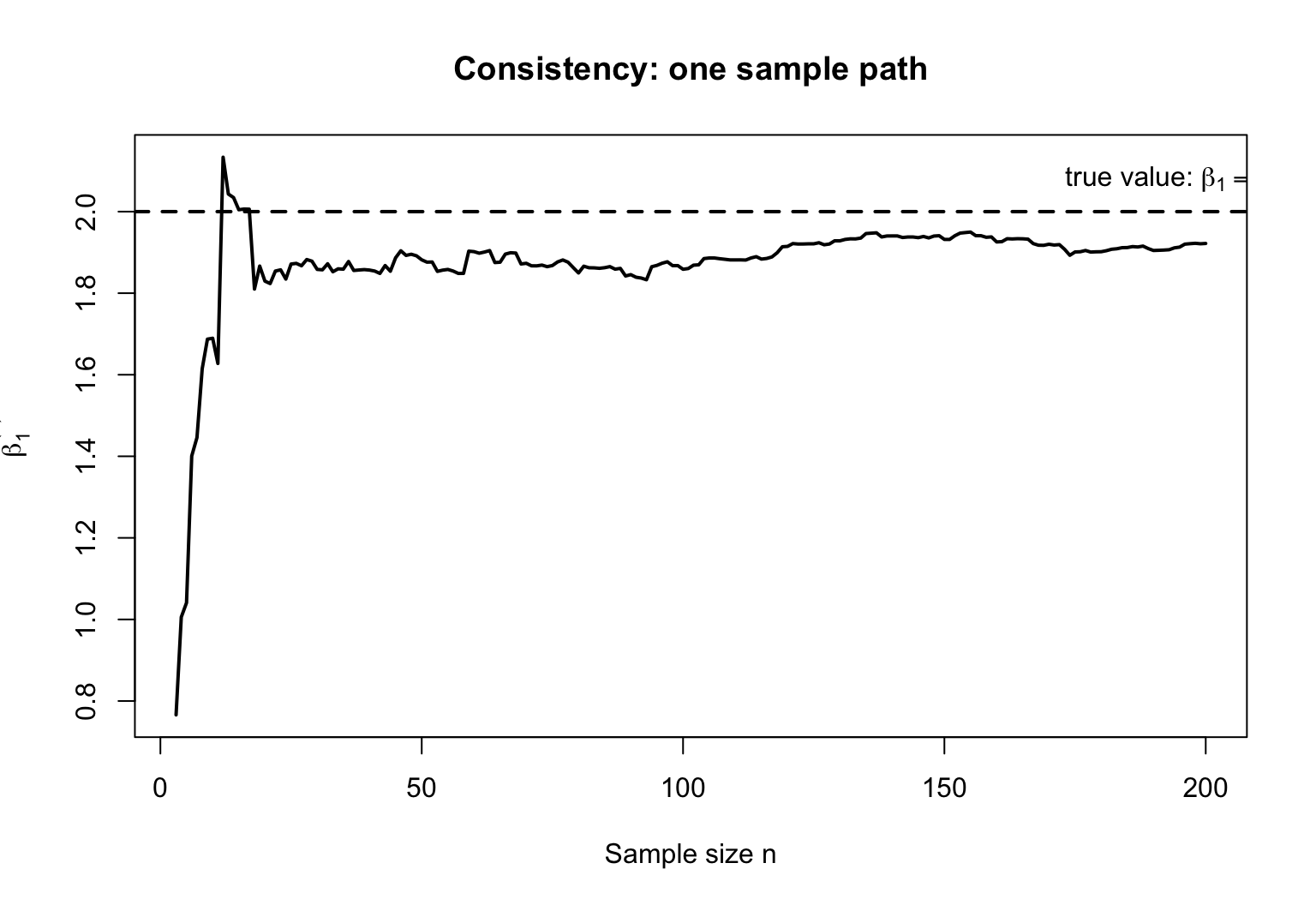
まずは1回の標本抽出について、サンプルを1つずつ追加しながら、そのたびに OLS の傾き推定量 \hat\beta_1^{(n)} を計算してみる。
set.seed (42 )<- 200 <- rnorm (n_path)<- rnorm (n_path)<- beta0 + beta1 * x_path + u_path<- 3 : n_path<- numeric (length (n_seq))for (j in seq_along (n_seq)) {<- n_seq[j]<- coef (lm (y_path[1 : nn] ~ x_path[1 : nn]))[2 ]plot (n_seq, b_path, type = "l" , lwd = 2 ,xlab = "Sample size n" ,ylab = expression (hat (beta)[1 ]^ {(n)}),main = "Consistency: one sample path" )abline (h = beta1, lty = 2 , lwd = 2 )text (170 , beta1 + 0.07 ,labels = bquote ("true value: " * beta[1 ] == .(beta1)),pos = 4 )
この図では、最初のうちは推定量がかなり大きく動く。しかし n が増えるにつれて、推定量は真の値 \beta_1 の近くで落ち着いていく。これが一致性の一番素朴なイメージである。
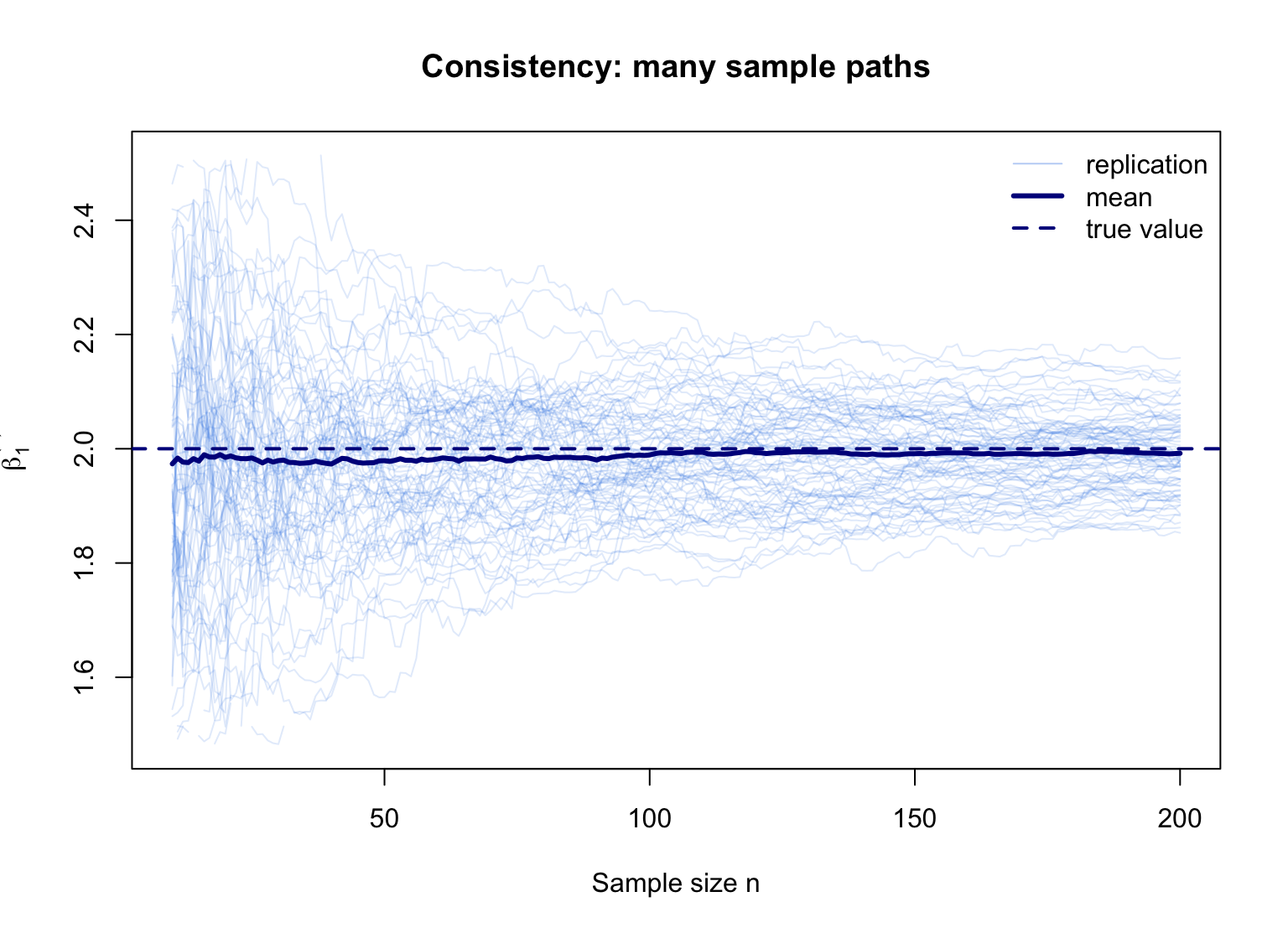
図で見る一致性(2):その軌跡を何度も重ねる
次に、上と同じことを何度も繰り返して、たくさんのサンプルパスを重ねてみる。
set.seed (123 )<- 80 <- 200 <- 10 <- n_min_plot: n_path<- matrix (NA_real_ , nrow = R_path, ncol = length (n_seq))for (r in 1 : R_path) {<- rnorm (n_path)<- rnorm (n_path)<- beta0 + beta1 * x_now + u_nowfor (j in seq_along (n_seq)) {<- n_seq[j]<- coef (lm (y_now[1 : nn] ~ x_now[1 : nn]))[2 ]<- colMeans (paths)<- quantile (as.vector (paths), probs = c (0.005 , 0.995 ), na.rm = TRUE )<- range (plot_limits, beta1)<- y_lim + c (- 1 , 1 ) * 0.08 * diff (y_lim)<- paths< y_lim[1 ] | paths_for_plot > y_lim[2 ]] <- NA plot (range (n_seq), y_lim, type = "n" ,xlab = "Sample size n" ,ylab = expression (hat (beta)[1 ]^ {(n)}),main = "Consistency: many sample paths" )for (r in 1 : R_path) {lines (n_seq, paths_for_plot[r, ], col = rgb (0.2 , 0.5 , 0.9 , 0.15 ), lwd = 1 )lines (n_seq, mean_path, lwd = 3 , col = "blue4" )abline (h = beta1, lty = 2 , lwd = 2 , col = "blue4" )legend ("topright" ,legend = c ("replication" , "mean" , "true value" ),lty = c (1 , 1 , 2 ),lwd = c (1 , 3 , 2 ),col = c (rgb (0.2 , 0.5 , 0.9 , 0.35 ), "blue4" , "blue4" ),bty = "n" )
たくさんの反復を重ねると、初期にはかなりバラついていた軌跡が、n が大きくなるにつれて真の値の近くに集まっていく。これが「確率的に真値へ近づく」という一致性の意味である。なお、図を見やすくするため、ここでは n=10 以降を表示し、上下に極端な一部の線分は表示から外している。
4. 漸近正規性(大標本で正規分布っぽくなる)
大標本では、OLS推定量は正規分布で近似できる:
\sqrt{n}\,(\hat\beta_1-\beta_1)\ \Rightarrow\ N(0,\,V)
これが成り立つから、私たちは
といった推論(inference)ができる。
今の知識で漸近正規性の主張を正確に理解することは無理なので、データがいっぱいあるとOLSと真のパラメータのズレは正規分布に従う と思っておこう。
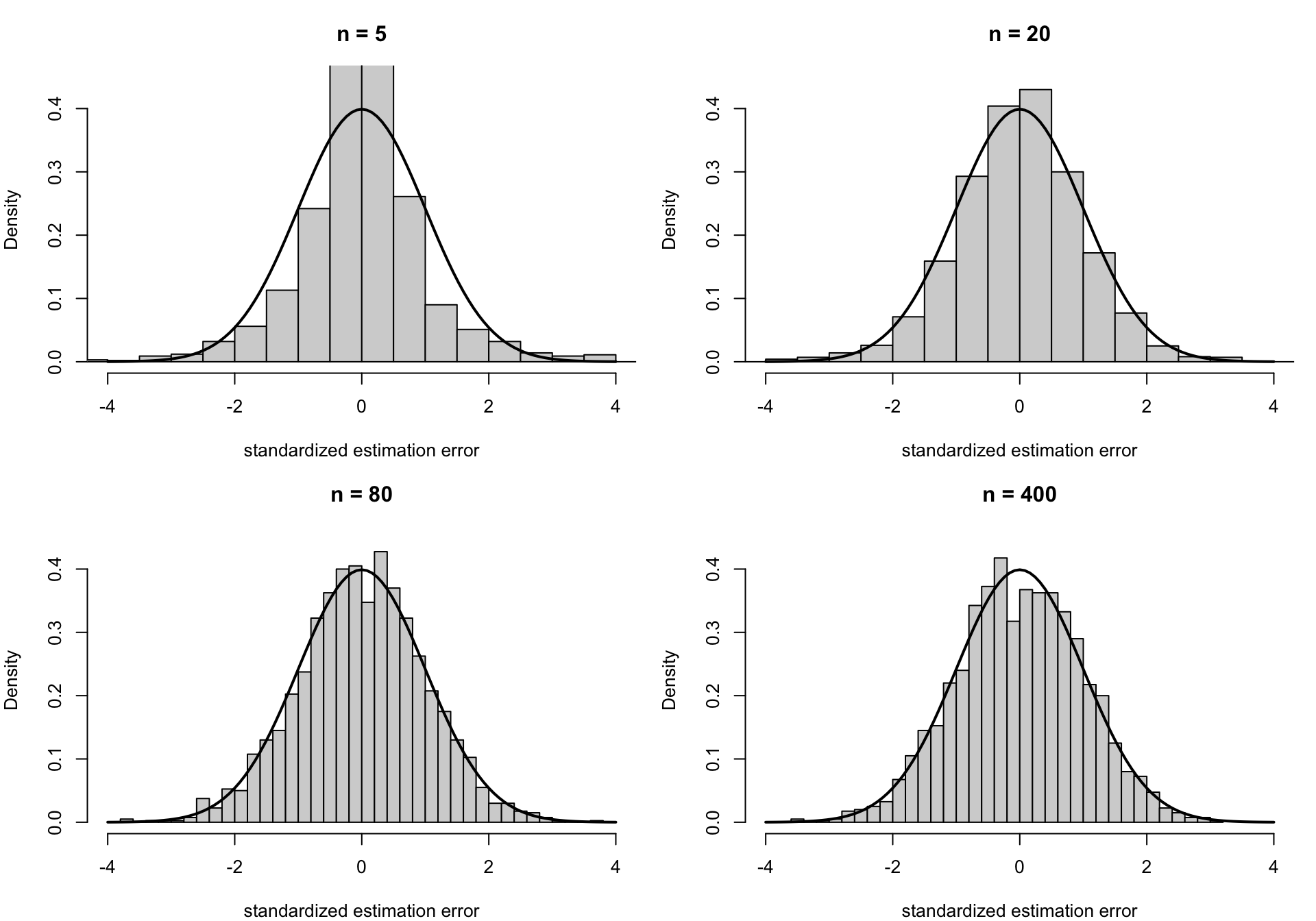
図で見る漸近正規性:標準化した推定誤差の分布
漸近正規性を見るには、\hat\beta_1 そのものではなく、
Z_n = \sqrt{n}(\hat\beta_1-\beta_1)
を何度も計算して、その分布を見るのが自然である。下の図では、標本サイズを大きくしながら、分布の形が正規分布に近づいていく様子を並べている。
set.seed (202 )<- 2000 <- c (5 , 20 , 80 , 400 )<- vector ("list" , length (n_grid))for (k in seq_along (n_grid)) {<- n_grid[k]<- numeric (R_asym)for (r in 1 : R_asym) {<- rnorm (n_asym)<- rexp (n_asym, rate = 1 ) - 1 <- beta0 + beta1 * x_now + u_now<- coef (lm (y_now ~ x_now))[2 ]<- sqrt (n_asym) * (b_hat_now - beta1)<- as.numeric (scale (z_now))par (mfrow = c (2 , 2 ), mar = c (4 , 4 , 3 , 1 ))for (k in seq_along (n_grid)) {hist (z_list[[k]], breaks = 35 , freq = FALSE ,xlim = c (- 4 , 4 ), ylim = c (0 , 0.45 ),main = paste0 ("n = " , n_grid[k]),xlab = "standardized estimation error" )curve (dnorm (x), from = - 4 , to = 4 , add = TRUE , lwd = 2 )
左上から右下に向かって n が大きくなる。小さい n では歪みや裾の厚さが残るが、n が大きくなるにつれて、ヒストグラムが重ねた正規分布の曲線に近づいていく。これが「大標本では正規分布で近似できる」という漸近正規性のイメージである。
ここでは分かりやすさのために、各 n でシミュレーションした Z_n = \sqrt{n}(\hat\beta_1-\beta_1) の平均と標準偏差をそろえてから図示している。実際の推論では、推定した標準誤差で割った統計量を使って信頼区間や検定を行う。
まとめ
OLS は、残差平方和を最小にする直線 として定義される。
平均点を通る・残差和が 0 になるなどの性質は、定義から自動的に出る 。
その傾きを「欲しいパラメータ」と読めるのは、E[u_i\mid x_i]=0
その条件の下で、OLS には不偏性・一致性・漸近正規性などの推定量としてのよい性質 がある。
宿題
と書いた部分の式展開を自分でやってみよう
OLS でも欲しいパラメータが識別できそうな例と、できなさそうな例を自分で考えてみよう
関数の最適化問題を完全に忘れていた人は、しっかり復習した方がよい
経済学に出てくる数学ちっくな問題は全て関数の最適化問題なので
OLSを求めるのに一階条件を見たが、これで本当にとけてるためには二階条件ってのも必要
OLSを求めるときにこの条件が満たされているのかを確認してみよう
次回はOLSの推論をやるので、t-testとかを復習しておこう
ChatGPTに統計的仮説検定について教えてもらおう
t-test, F-test, Z-testあたりを最小の例で教えてもらうといい