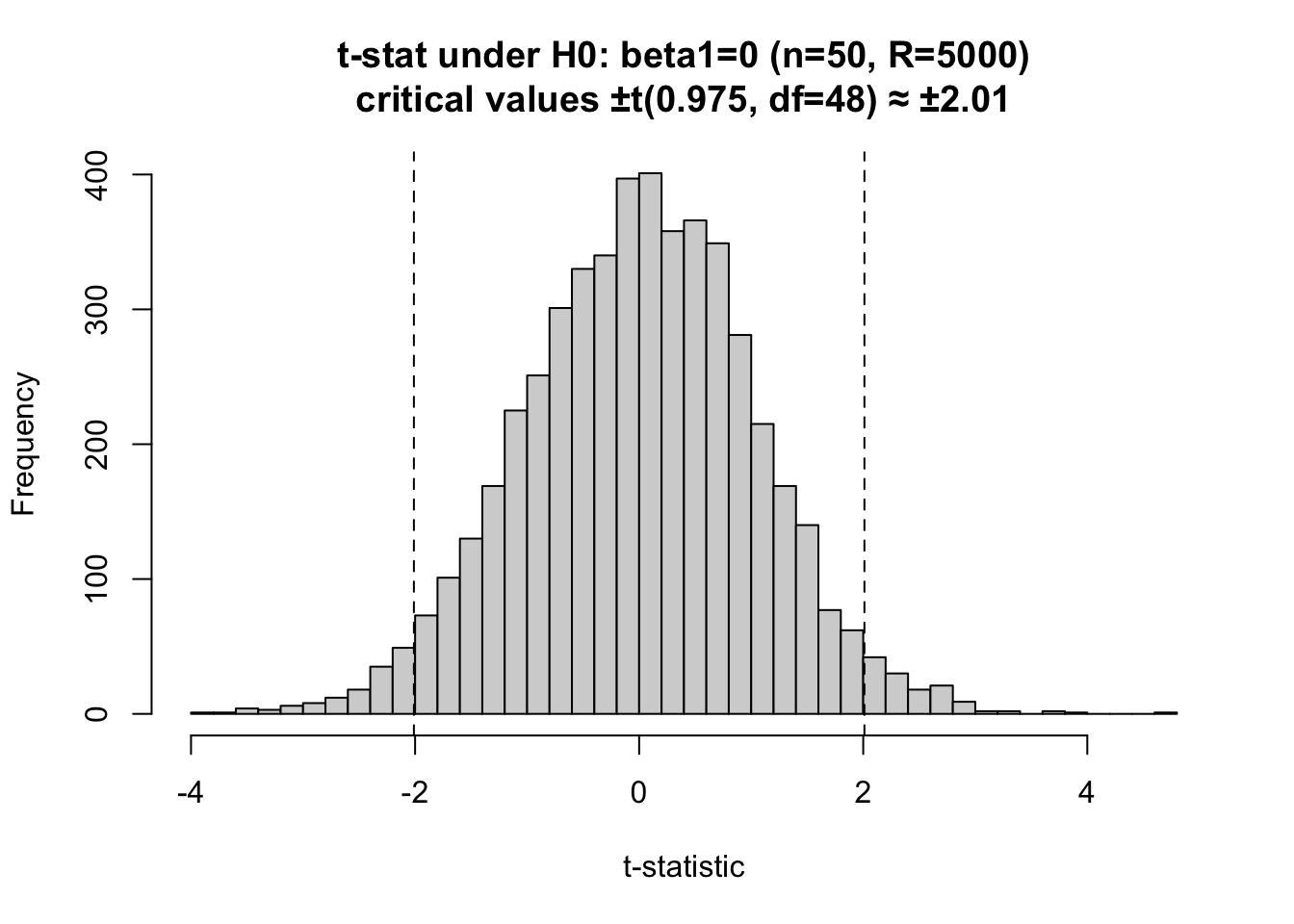
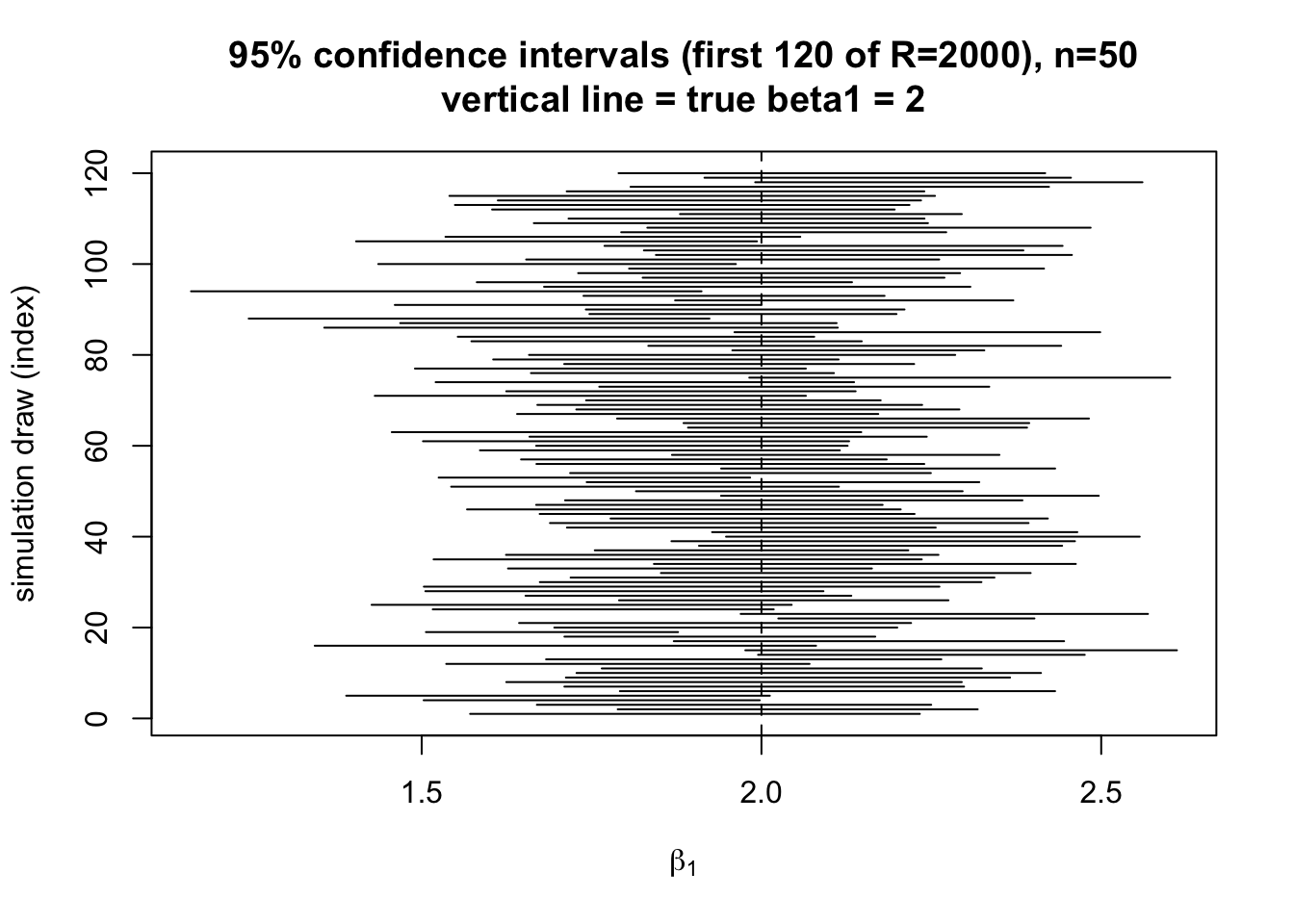
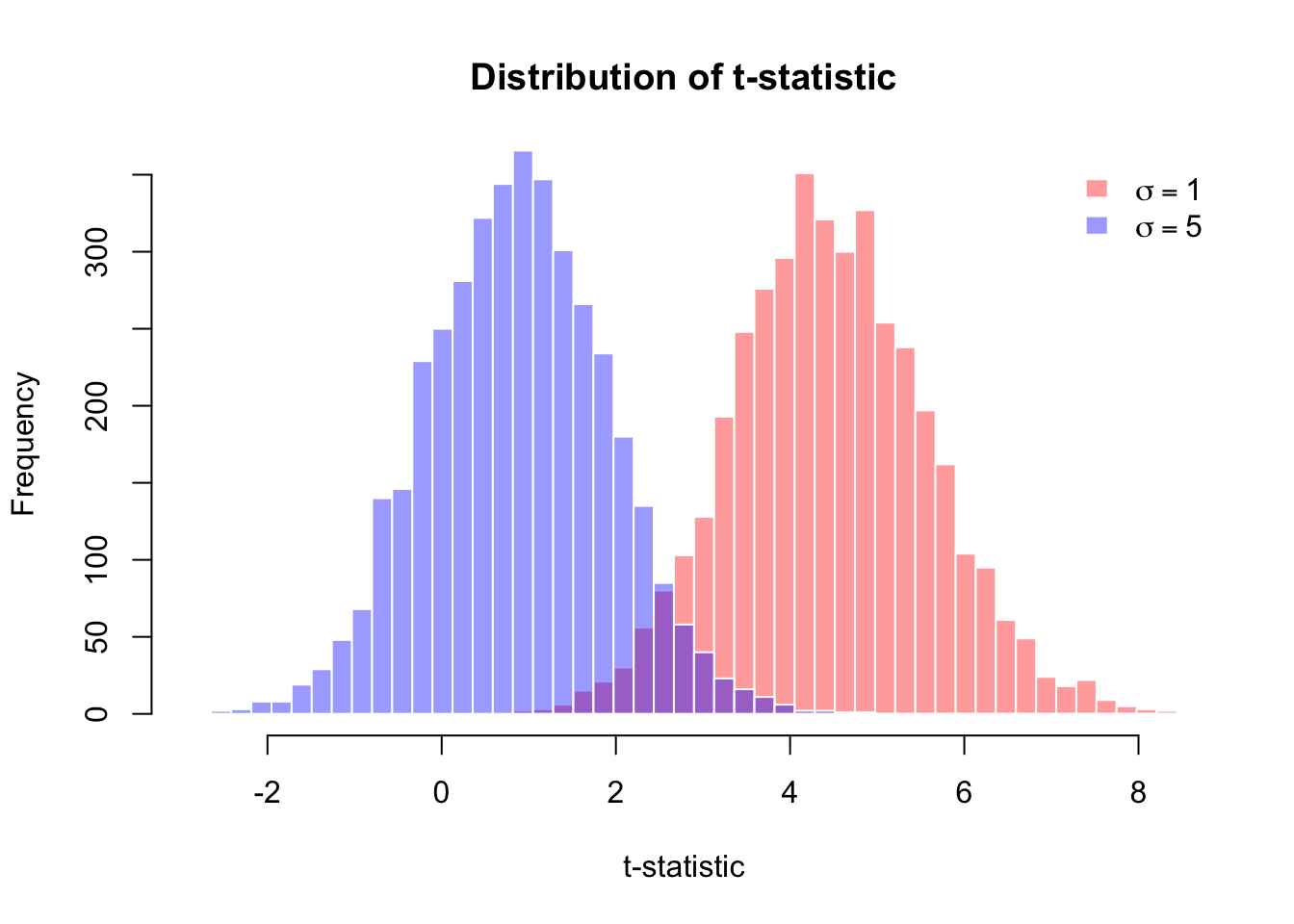
simulate_summary <- function(R, n, beta0, beta1, sigma, seed) {
set.seed(seed)
b1hat <- numeric(R)
se1 <- numeric(R)
tval <- numeric(R)
for (r in 1:R) {
x <- rnorm(n)
u <- rnorm(n, sd = sigma)
y <- beta0 + beta1 * x + u
fit <- lm(y ~ x)
summ <- summary(fit)$coefficients
b1hat[r] <- summ["x", "Estimate"]
se1[r] <- summ["x", "Std. Error"]
tval[r] <- summ["x", "t value"]
}
list(b1hat = b1hat, se = se1, t = tval)
}
R <- 4000
beta0 <- 0
beta1 <- 0.5
sigma <- 2
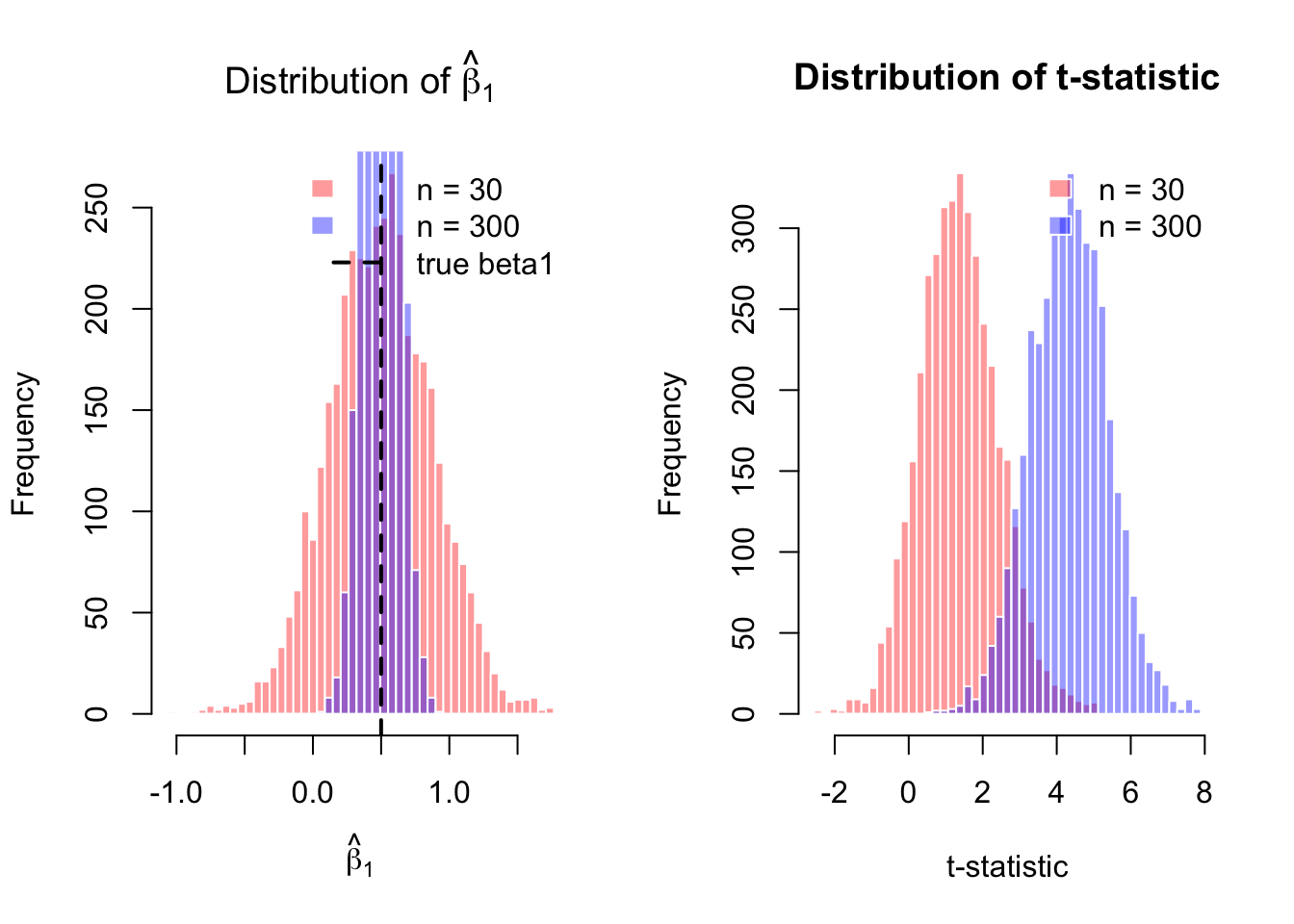
out30 <- simulate_summary(R, 30, beta0, beta1, sigma, seed = 21)
out300 <- simulate_summary(R, 300, beta0, beta1, sigma, seed = 22)
old_par <- par(no.readonly = TRUE)
par(mfrow = c(1, 2))
# -----------------------------
# 1. beta1_hat のヒストグラムを重ねる
# -----------------------------
breaks_b1 <- seq(
min(c(out30$b1hat, out300$b1hat)),
max(c(out30$b1hat, out300$b1hat)),
length.out = 50
)
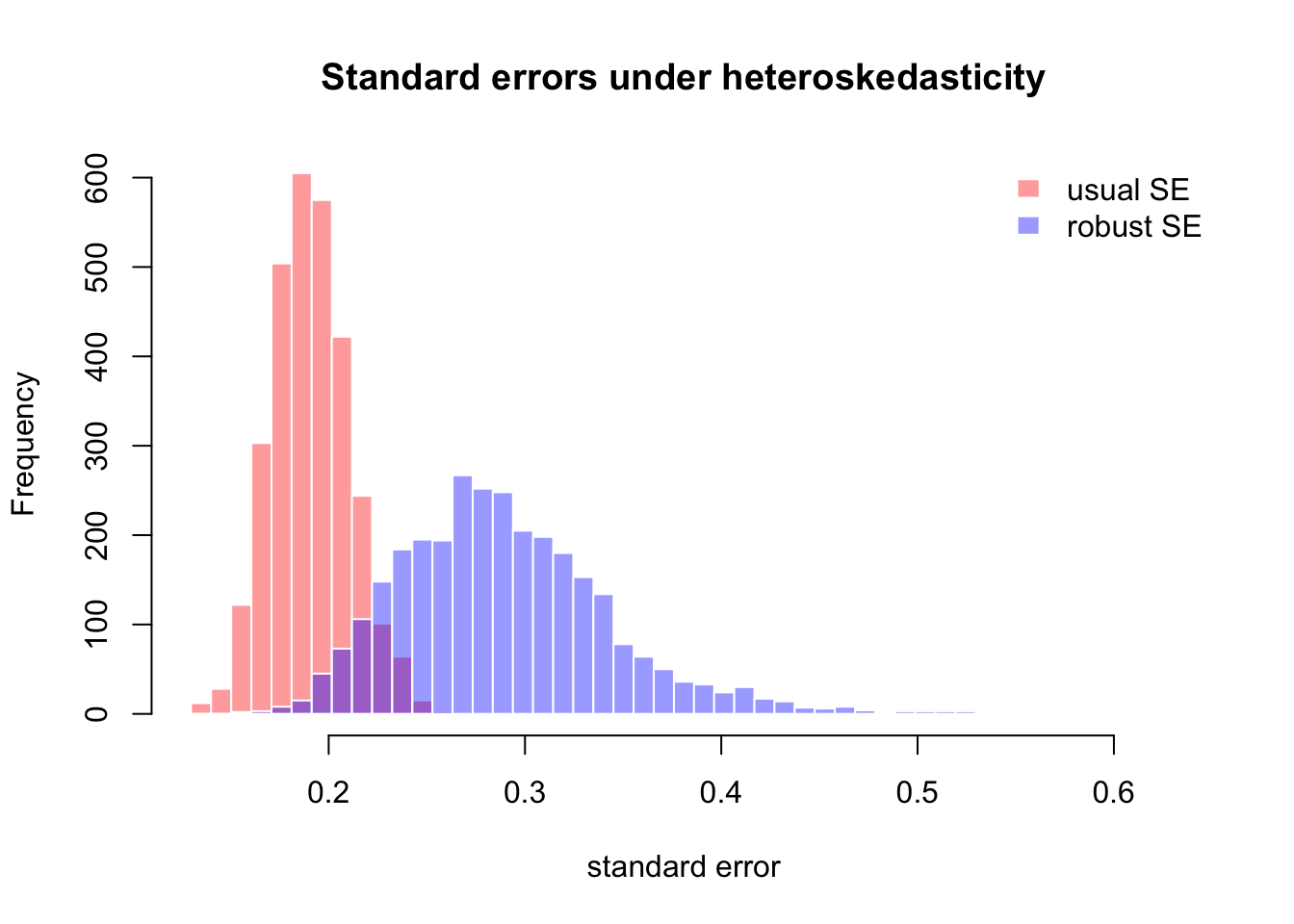
hist(out30$b1hat,
breaks = breaks_b1,
freq = TRUE,
col = rgb(1, 0, 0, 0.4),
border = "white",
main = expression("Distribution of " * hat(beta)[1]),
xlab = expression(hat(beta)[1]),
xlim = range(breaks_b1))
hist(out300$b1hat,
breaks = breaks_b1,
freq = TRUE,
col = rgb(0, 0, 1, 0.4),
border = "white",
add = TRUE)
abline(v = beta1, lwd = 2, lty = 2)
legend("topright",
legend = c("n = 30", "n = 300", "true beta1"),
fill = c(rgb(1, 0, 0, 0.4), rgb(0, 0, 1, 0.4), NA),
border = c("white", "white", NA),
lty = c(NA, NA, 2),
lwd = c(NA, NA, 2),
bty = "n")
# -----------------------------
# 2. t-stat のヒストグラムを重ねる
# -----------------------------
breaks_t <- seq(
min(c(out30$t, out300$t)),
max(c(out30$t, out300$t)),
length.out = 50
)
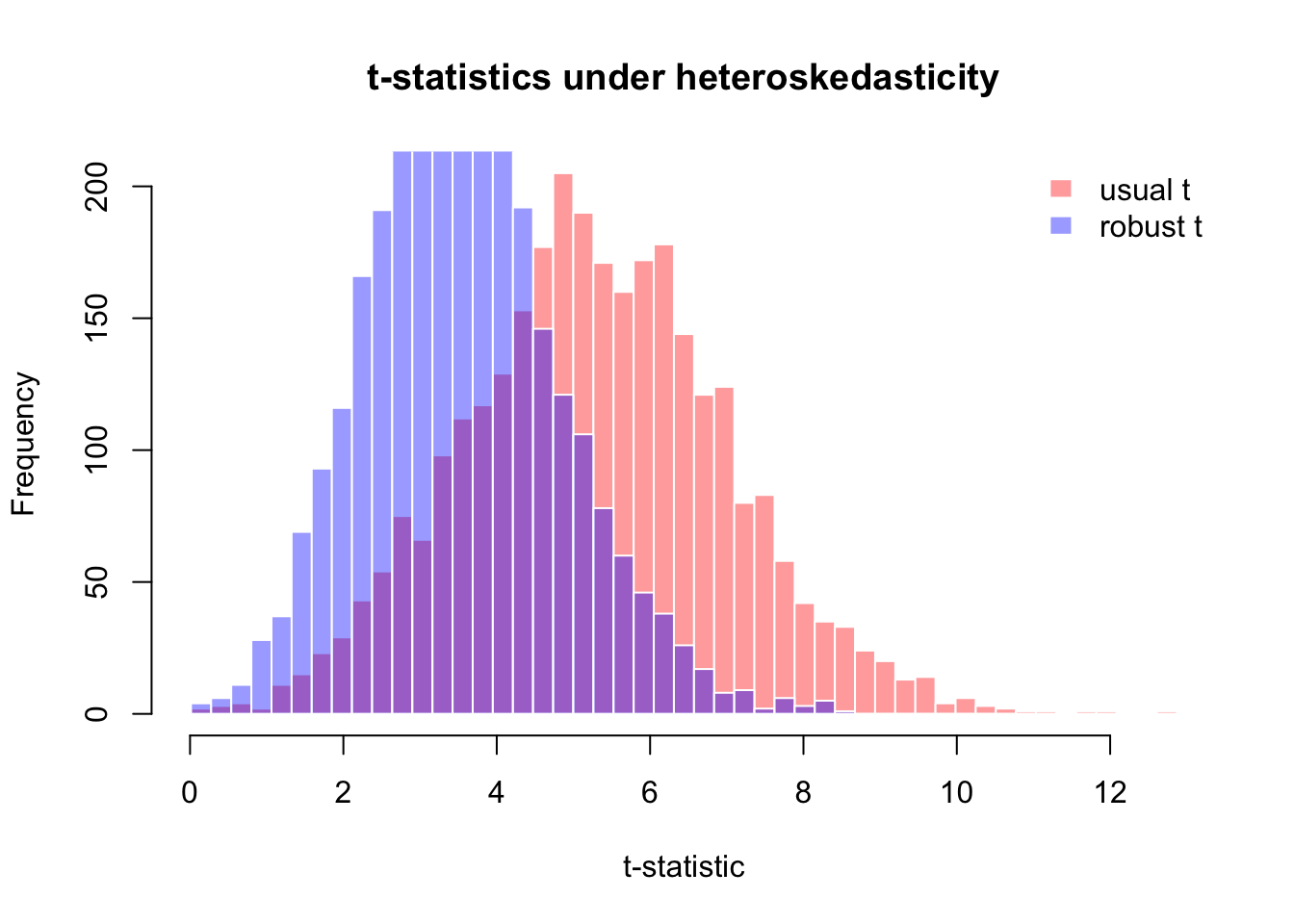
hist(out30$t,
breaks = breaks_t,
freq = TRUE,
col = rgb(1, 0, 0, 0.4),
border = "white",
main = "Distribution of t-statistic",
xlab = "t-statistic",
xlim = range(breaks_t))
hist(out300$t,
breaks = breaks_t,
freq = TRUE,
col = rgb(0, 0, 1, 0.4),
border = "white",
add = TRUE)
legend("topright",
legend = c("n = 30", "n = 300"),
fill = c(rgb(1, 0, 0, 0.4), rgb(0, 0, 1, 0.4)),
border = "white",
bty = "n")