Lecture 5:重回帰
コントロール変数・バイアス・多重共線性
重要この講義で押さえたいこと
- 重回帰は、「他の条件を揃えた上で」の関係をみるための基本的な道具である。
- 関心のある変数とコントロール変数を区別して読むことが大事である。
- バイアスと多重共線性は別問題であり、何が崩れているのかを切り分けて考える必要がある。
今回は、Lecture 1・2 で見てきた「教育年数と賃金」の話に戻りながら、重回帰を導入する。まずはモデルと OLS の計算を確認し、そのあとで推定量としての性質、バイアス、多重共線性へと進む。
ノートこの lecture の流れ
- まず、重回帰が何をしたい道具なのかを整理する。
- 次に、OLS でどう推定するか、そしてどんな性質があるかを見る。
- そのうえで、バイアス と 多重共線性 を区別して理解する。
もう一度 Angrist and Krueger (1991) の例に戻る。
以下のようなストーリーであったことを思い出そう。
教育年数が上がった時に、賃金がどれくらい増えるのかを知りたい しかし、教育年数も賃金も「能力」という別の変数によって影響される そして「能力」は直接観測できない だから \mathrm{Wage}_i = \beta_0 + \beta_1 \mathrm{Education}_i + u_i の回帰分析では、E[u_i\mid \mathrm{Education}_i] \neq 0 となりそうで、\beta_1 が識別できない
さて、ここでは一旦、「能力」が見えてる世界を考える。すなわち、\mathrm{Ability}_iという変数が実際に観測できている世界である。
このとき、以下のような linear model(線形モデル)を考える。
\mathrm{Wage}_i = \beta_0 + \beta_1 \mathrm{Education}_i + \beta_2 \mathrm{Ability}_i + u_i
すると今度は
E[u_i \mid \mathrm{Education}_i, \mathrm{Ability}_i] = 0
が成り立ちそうである。なぜなら、教育年数と能力を同じにしたとき、残りの賃金の違いは教育年数と系統的には結びついていないように思えるからだ。 (もちろん現実には他にもいろいろな影響があるが、今のシンプルな設定なら、この二つの変数さえ一緒にしたら残りはランダムだと考えてよい。)
これが重回帰を考えるモチベーションである。
能力という変数が一緒の二人についてなら、賃金の変動はランダムなはずなので、欲しかった教育年数の賃金への影響を取り出すことができる、という具合である。
今いちばん知りたいパラメータが教育年数にくっついている係数 \beta_1 だとすると、単回帰では教育年数のことを 説明変数 と呼んでいた。
これに対して、「ある変数については値が同じ二人について比べたい」という時の揃えたい変数のことをコントロール変数、ないし共変量と呼ぶ。つまり今の例では能力がコントロール変数である。
重回帰では右辺に入る変数は全部 説明変数 と呼ぶが、その中に二種類いるという理解でよい。 1. 関心のある変数 - それらにくっつく係数が知りたいパラメータ 2. コントロール変数 - これらはあくまでも関心のある変数のパラメータを識別するためにコントロールしたい変数なので、これらにくっつくパラメータの値そのものには関心がない
以下ではこの重回帰について、その実際の計算方法、すなわち推定と推論の部分を見ていく。
重回帰のモデル
まずは、説明変数が2つある最も基本的な重回帰モデルを考えよう。 個人 i について、被説明変数を Y_i、2つの説明変数を X_{1i}, X_{2i} とすると、モデルは
Y_i = \beta_0 + \beta_1 X_{1i} + \beta_2 X_{2i} + u_i
と書かれる。
ここで
- Y_i:結果として観測したい変数
- X_{1i}:主に注目している説明変数
- X_{2i}:コントロール変数
- u_i:モデルで説明しきれない部分
である。
この式の意味は、X_{1i} と X_{2i} の値が与えられたとき、Y_i の平均的な大きさが
\beta_0 + \beta_1 X_{1i} + \beta_2 X_{2i}
で表される、ということである。
単回帰では右辺に説明変数が1つしかなかったが、重回帰では右辺に複数の変数を入れることができる。 そのぶん、「他の条件を揃えた上での関係」を見やすくなる。
OLS は何をしているのか
では、この \beta_0, \beta_1, \beta_2 は実際にはどうやって決めるのだろうか。
OLS(最小二乗法)は、各データ点についての予測誤差を考え、その二乗和ができるだけ小さくなるように係数を選ぶ方法である。
個人 i についての予測値を
\hat Y_i = \beta_0 + \beta_1 X_{1i} + \beta_2 X_{2i}
と書くと、誤差は
Y_i - \hat Y_i = Y_i - (\beta_0 + \beta_1 X_{1i} + \beta_2 X_{2i})
である。
OLS は、この誤差の二乗を全部足した
\sum_{i=1}^n \left( Y_i - \beta_0 - \beta_1 X_{1i} - \beta_2 X_{2i} \right)^2
を最小にするように \beta_0, \beta_1, \beta_2 を選ぶ。
これが重回帰の OLS の定義である。
4つのデータ点で見てみる
まずは非常に小さい例を考えよう。 次の4人のデータがあるとする。
| 個人 i | X_{1i} | X_{2i} | Y_i |
|---|---|---|---|
| 1 | 0 | 0 | 10 |
| 2 | 1 | 0 | 12 |
| 3 | 0 | 1 | 13 |
| 4 | 1 | 1 | 15 |
ここで考えたいモデルは
Y_i = \beta_0 + \beta_1 X_{1i} + \beta_2 X_{2i} + u_i
である。
このとき、各個人について予測値は次のようになる。
個人1では X_{11}=0, X_{21}=0 なので \hat Y_1 = \beta_0
個人2では X_{12}=1, X_{22}=0 なので \hat Y_2 = \beta_0 + \beta_1
個人3では X_{13}=0, X_{23}=1 なので \hat Y_3 = \beta_0 + \beta_2
個人4では X_{14}=1, X_{24}=1 なので \hat Y_4 = \beta_0 + \beta_1 + \beta_2
したがって、二乗誤差和は
\begin{aligned} SSR(\beta_0,\beta_1,\beta_2) &= (10-\beta_0)^2 +(12-\beta_0-\beta_1)^2 \\ &\quad +(13-\beta_0-\beta_2)^2 +(15-\beta_0-\beta_1-\beta_2)^2 \end{aligned}
となる。
OLS は、この式を最小にする \beta_0,\beta_1,\beta_2 を探している。
この例ではぴったり当てはまる
この例では、実は
\beta_0 = 10, \quad \beta_1 = 2, \quad \beta_2 = 3
と置くと、4つの点をすべてぴったり通る。
実際、
- 個人1の予測値: \hat Y_1 = 10
- 個人2の予測値: \hat Y_2 = 10+2=12
- 個人3の予測値: \hat Y_3 = 10+3=13
- 個人4の予測値: \hat Y_4 = 10+2+3=15
となり、すべて実際の Y_i と一致する。
したがって、このときの誤差は全部 0 であり、二乗誤差和も
SSR(10,2,3)=0
である。
二乗誤差和は負にはならないので、0 が達成できたならそれが最小値である。 よって、この例では OLS は
\hat\beta_0 = 10,\qquad \hat\beta_1 = 2,\qquad \hat\beta_2 = 3
を選ぶ。
この係数はどう読めるか
この例では係数の意味もかなりわかりやすい。
まず \hat\beta_0=10 は、
X_1=0,\quad X_2=0
のときの予測値である。
次に \hat\beta_1=2 は、X_2 を一定にしたまま X_1 が 1 増えると、予測値が 2 増えることを表している。
実際、
- X_2=0 のとき X_1=0 から X_1=1 に変わると Y は 10 から 12 に増えている
- X_2=1 のとき X_1=0 から X_1=1 に変わると Y は 13 から 15 に増えている
どちらの場合も増加分は 2 である。
同様に、\hat\beta_2=3 は、X_1 を一定にしたまま X_2 が 1 増えると、予測値が 3 増えることを表している。
ただし、いつもぴったり当てはまるわけではない
今の例は都合よく4点がきれいに1つの式
Y_i = \beta_0 + \beta_1 X_{1i} + \beta_2 X_{2i}
に乗っていた。 しかし、現実のデータではこのようにぴったり当てはまることは普通ない。
たとえば最後のデータだけ少し変えて、次のようになっていたとしよう。
| 個人 i | X_{1i} | X_{2i} | Y_i |
|---|---|---|---|
| 1 | 0 | 0 | 10 |
| 2 | 1 | 0 | 12 |
| 3 | 0 | 1 | 13 |
| 4 | 1 | 1 | 14 |
このとき、先ほどと同じ
\beta_0 = 10,\quad \beta_1 = 2,\quad \beta_2 = 3
を使うと、個人4の予測値は
\hat Y_4 = 10+2+3=15
となり、実際の値 14 とずれる。
つまり、誤差は完全には 0 にならない。
それでも OLS は、誤差を完全に消そうとするのではなく、誤差の二乗和ができるだけ小さくなるように係数を選ぶ。 これが「最小二乗法」という名前の意味である。
重回帰でも考え方は単回帰と同じ
ここで重要なのは、重回帰になっても OLS の考え方そのものは単回帰と変わらない、ということである。
単回帰では
Y_i = \beta_0 + \beta_1 X_i + u_i
として、
\sum_{i=1}^n (Y_i-\beta_0-\beta_1X_i)^2
を最小化した。
重回帰では説明変数が1つ増えて、
\sum_{i=1}^n \left( Y_i-\beta_0-\beta_1X_{1i}-\beta_2X_{2i} \right)^2
を最小化しているだけである。
つまり、やっていることは「予測誤差の二乗和を最小にする」という同じ操作であり、違うのは右辺に入る変数が増えたことだけである。
ノートここでの狙い
単回帰と同じく、重回帰でも OLS は 二乗誤差和を最小にする係数 を選んでいる。
ただし、説明変数が増えるぶん、正規方程式は少しだけ複雑になる。
OLS を FOC から求める
単回帰のときと同じように、重回帰でも OLS は二乗誤差和を最小にすることで定義される。 いま、2つの説明変数と定数項があるモデル
Y_i = \beta_0 + \beta_1 X_{1i} + \beta_2 X_{2i} + u_i
を考えよう。
OLS は
S(\beta_0,\beta_1,\beta_2) = \sum_{i=1}^n \left( Y_i-\beta_0-\beta_1X_{1i}-\beta_2X_{2i} \right)^2
を最小にする \beta_0,\beta_1,\beta_2 を選ぶ方法であった。
一階条件を立てる
この S(\beta_0,\beta_1,\beta_2) を、それぞれの係数で偏微分して 0 とおく。
まず \beta_0 について微分すると、
\frac{\partial S}{\partial \beta_0} = -2 \sum_{i=1}^n \left( Y_i-\beta_0-\beta_1X_{1i}-\beta_2X_{2i} \right) =0
である。
両辺を -2 で割ると、
\sum_{i=1}^n \left( Y_i-\beta_0-\beta_1X_{1i}-\beta_2X_{2i} \right)=0
を得る。
次に \beta_1 について微分すると、
\frac{\partial S}{\partial \beta_1} = -2 \sum_{i=1}^n X_{1i} \left( Y_i-\beta_0-\beta_1X_{1i}-\beta_2X_{2i} \right) =0
したがって、
\sum_{i=1}^n X_{1i} \left( Y_i-\beta_0-\beta_1X_{1i}-\beta_2X_{2i} \right)=0
となる。
同様に \beta_2 について微分すると、
\frac{\partial S}{\partial \beta_2} = -2 \sum_{i=1}^n X_{2i} \left( Y_i-\beta_0-\beta_1X_{1i}-\beta_2X_{2i} \right) =0
したがって、
\sum_{i=1}^n X_{2i} \left( Y_i-\beta_0-\beta_1X_{1i}-\beta_2X_{2i} \right)=0
となる。
正規方程式
この3つが、重回帰 OLS の一階条件である。 これらをまとめると、
\sum_{i=1}^n \left( Y_i-\beta_0-\beta_1X_{1i}-\beta_2X_{2i} \right)=0
\sum_{i=1}^n X_{1i} \left( Y_i-\beta_0-\beta_1X_{1i}-\beta_2X_{2i} \right)=0
\sum_{i=1}^n X_{2i} \left( Y_i-\beta_0-\beta_1X_{1i}-\beta_2X_{2i} \right)=0
である。
これを展開すると、
\sum_{i=1}^n Y_i = n\beta_0 + \beta_1\sum_{i=1}^n X_{1i} + \beta_2\sum_{i=1}^n X_{2i}
\sum_{i=1}^n X_{1i}Y_i = \beta_0\sum_{i=1}^n X_{1i} + \beta_1\sum_{i=1}^n X_{1i}^2 + \beta_2\sum_{i=1}^n X_{1i}X_{2i}
\sum_{i=1}^n X_{2i}Y_i = \beta_0\sum_{i=1}^n X_{2i} + \beta_1\sum_{i=1}^n X_{1i}X_{2i} + \beta_2\sum_{i=1}^n X_{2i}^2
となる。
この3本の連立方程式を解けば、OLS 推定量 \hat\beta_0,\hat\beta_1,\hat\beta_2 が得られる。 これを 正規方程式 と呼ぶ。
単回帰との違い
単回帰では、未知数が \beta_0,\beta_1 の2つだったので、FOC も2本であった。 重回帰では未知数が \beta_0,\beta_1,\beta_2 の3つになるので、FOC も3本になる。
考え方自体はまったく同じである。 違うのは、説明変数が1つ増えたことで、解くべき連立方程式が1本増えること、そして交差項
\sum_{i=1}^n X_{1i}X_{2i}
が現れることである。
この交差項が出てくるのは、2つの説明変数が互いに関係している可能性があるからである。 重回帰では、X_1 の効果を考えるときにも X_2 との関係を同時に調整しなければならない。
\hat\beta_0 は平均を使って書ける
最初の一階条件
\sum_{i=1}^n \left( Y_i-\hat\beta_0-\hat\beta_1X_{1i}-\hat\beta_2X_{2i} \right)=0
を n で割ると、
\bar Y-\hat\beta_0-\hat\beta_1\bar X_1-\hat\beta_2\bar X_2=0
となる。したがって、
\hat\beta_0= \bar Y-\hat\beta_1\bar X_1-\hat\beta_2\bar X_2
を得る。
これは単回帰のときの
\hat\beta_0=\bar Y-\hat\beta_1\bar X
の自然な拡張になっている。
つまり、重回帰でも定数項は 「平均的な Y から、説明変数の平均部分を差し引いたもの」 として決まる。
ここでは何が大事か
この段階で大事なのは、まだ \hat\beta_1,\hat\beta_2 のきれいな閉じた公式を覚えることではない。 重要なのは次の点である。
- OLS は二乗誤差和を最小化している
- その結果として、3本の一階条件が出てくる
- それを解くと OLS 推定量が得られる
- 重回帰では、各説明変数の係数が他の説明変数との関係も含めて同時に決まる
傾きの値の公式がある。あるけど…
まず、各変数の平均を
\bar Y = \frac{1}{n}\sum_{i=1}^n Y_i, \qquad \bar X_1 = \frac{1}{n}\sum_{i=1}^n X_{1i}, \qquad \bar X_2 = \frac{1}{n}\sum_{i=1}^n X_{2i}
とする。
さらに、平均からのずれを
\tilde Y_i = Y_i - \bar Y, \qquad \tilde X_{1i} = X_{1i} - \bar X_1, \qquad \tilde X_{2i} = X_{2i} - \bar X_2
と書く。
このとき、
\hat\beta_1 = \frac{ \left(\sum_{i=1}^n \tilde X_{2i}^2\right) \left(\sum_{i=1}^n \tilde X_{1i}\tilde Y_i\right)- \left(\sum_{i=1}^n \tilde X_{1i}\tilde X_{2i}\right) \left(\sum_{i=1}^n \tilde X_{2i}\tilde Y_i\right) }{ \left(\sum_{i=1}^n \tilde X_{1i}^2\right) \left(\sum_{i=1}^n \tilde X_{2i}^2\right) - \left(\sum_{i=1}^n \tilde X_{1i}\tilde X_{2i}\right)^2 }
\hat\beta_2 = \frac{ \left(\sum_{i=1}^n \tilde X_{1i}^2\right) \left(\sum_{i=1}^n \tilde X_{2i}\tilde Y_i\right)- \left(\sum_{i=1}^n \tilde X_{1i}\tilde X_{2i}\right) \left(\sum_{i=1}^n \tilde X_{1i}\tilde Y_i\right) }{ \left(\sum_{i=1}^n \tilde X_{1i}^2\right) \left(\sum_{i=1}^n \tilde X_{2i}^2\right) - \left(\sum_{i=1}^n \tilde X_{1i}\tilde X_{2i}\right)^2 }
であり、定数項は
\hat\beta_0 = \bar Y - \hat\beta_1 \bar X_1 - \hat\beta_2 \bar X_2
で与えられる。
幾何的な射影として見る
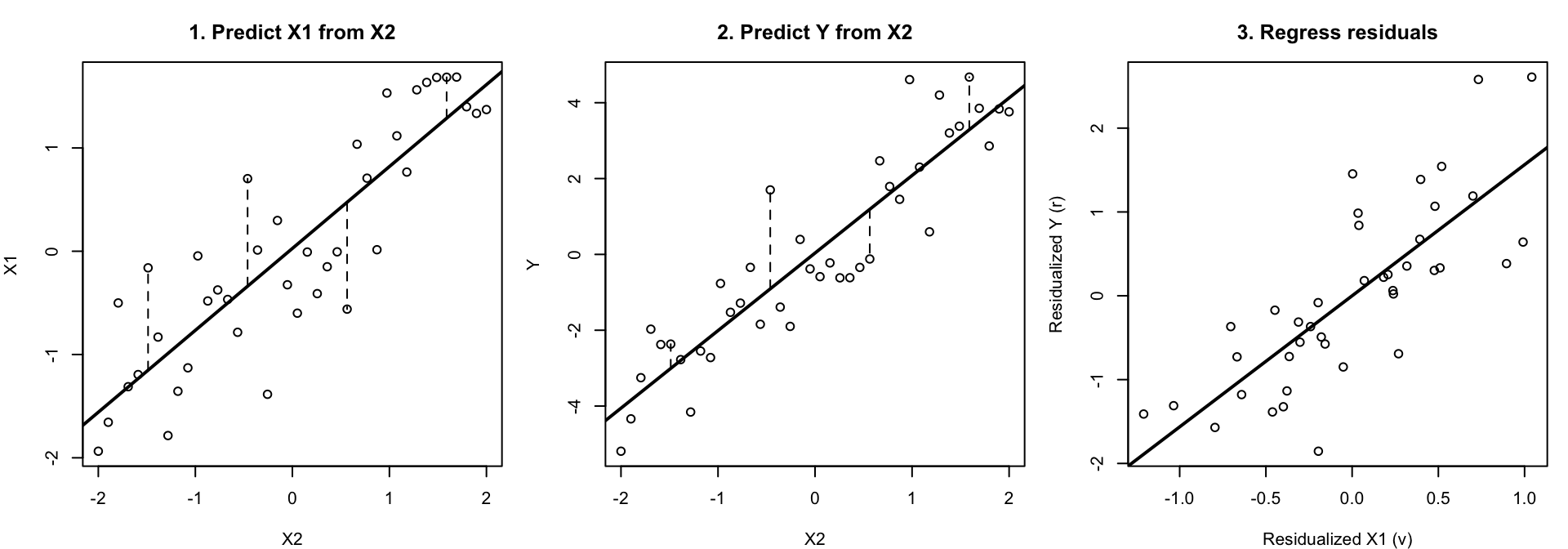
「射影」という言葉でイメージしているのは、次のような図である。

この図では、緑の平面が「説明変数を使って予測できる値」の集まりである。観測された Y は、その平面から少し浮いたところにある点として描かれている。OLS は、Y にできるだけ近い平面上の点を選ぶ。この平面上の点が予測値 \hat Y であり、Y から \hat Y までのズレが残差である。
このとき、残差は予測できる平面に対して垂直になる。直感的には、もし残差が平面上のどちらかの方向にまだ傾いているなら、その方向に予測値を少し動かすことで二乗誤差をさらに小さくできるはずである。OLS ではもうそれができないところまで予測値を動かしているので、残ったズレは予測できる部分に対して垂直になる。
FWL定理:重回帰係数を残りどうしの単回帰として読む
推定値の公式を覚えようとする必要はない。大事なのは、この公式が何をしているのかである。実は、重回帰における X_1 の係数は、X_1 と Y から X_2 で説明できる部分を取り除いたあと、残った部分どうしを単回帰した係数として読むことができる。これを Frisch-Waugh-Lovell 定理、あるいは FWL 定理と呼ぶ。
まず、説明変数が2つのケースで、数式を最後まで確認しておこう。先ほど定義した
\tilde Y_i,\qquad \tilde X_{1i},\qquad \tilde X_{2i}
を使う。
はじめに、X_1 を X_2 で単回帰する。平均からのずれを使えば、定数項を省いて
\tilde X_{1i}=\hat a\tilde X_{2i}+v_i
と書ける。単回帰の公式より、
\hat a= \frac{\sum_{i=1}^n \tilde X_{1i}\tilde X_{2i}} {\sum_{i=1}^n \tilde X_{2i}^2}
である。したがって、
v_i = \tilde X_{1i} - \frac{\sum_{j=1}^n \tilde X_{1j}\tilde X_{2j}} {\sum_{j=1}^n \tilde X_{2j}^2} \tilde X_{2i}
と書ける。ここで v_i は、X_1 のうち X_2 で説明できなかった残りである。
次に、Y を X_2 で単回帰する。同じく平均からのずれを使って、
\tilde Y_i=\hat c\tilde X_{2i}+r_i
と書く。単回帰の公式より、
\hat c= \frac{\sum_{i=1}^n \tilde X_{2i}\tilde Y_i} {\sum_{i=1}^n \tilde X_{2i}^2}
である。したがって、
r_i = \tilde Y_i - \frac{\sum_{j=1}^n \tilde X_{2j}\tilde Y_j} {\sum_{j=1}^n \tilde X_{2j}^2} \tilde X_{2i}
と書ける。ここで r_i は、Y のうち X_2 で説明できなかった残りである。
次に、r_i を v_i に単回帰する。
r_i = b v_i + \text{誤差}
単回帰の係数公式より、
\hat b = \frac{\sum_{i=1}^n v_i r_i} {\sum_{i=1}^n v_i^2}
である。
ここで計算すると、
\sum_{i=1}^n v_i r_i = \sum_{i=1}^n \tilde X_{1i}\tilde Y_i - \frac{ \left(\sum_{i=1}^n \tilde X_{1i}\tilde X_{2i}\right) \left(\sum_{i=1}^n \tilde X_{2i}\tilde Y_i\right) }{ \sum_{i=1}^n \tilde X_{2i}^2 }
また、
\sum_{i=1}^n v_i^2 = \sum_{i=1}^n \tilde X_{1i}^2 - \frac{ \left(\sum_{i=1}^n \tilde X_{1i}\tilde X_{2i}\right)^2 }{ \sum_{i=1}^n \tilde X_{2i}^2 }
である。したがって、
\hat b = \frac{ \sum_{i=1}^n \tilde X_{1i}\tilde Y_i - \frac{ \left(\sum_{i=1}^n \tilde X_{1i}\tilde X_{2i}\right) \left(\sum_{i=1}^n \tilde X_{2i}\tilde Y_i\right) }{ \sum_{i=1}^n \tilde X_{2i}^2 } }{ \sum_{i=1}^n \tilde X_{1i}^2 - \frac{ \left(\sum_{i=1}^n \tilde X_{1i}\tilde X_{2i}\right)^2 }{ \sum_{i=1}^n \tilde X_{2i}^2 } }
分母分子に \sum_{i=1}^n \tilde X_{2i}^2 をかけると、
\hat b = \frac{ \left(\sum_{i=1}^n \tilde X_{2i}^2\right) \left(\sum_{i=1}^n \tilde X_{1i}\tilde Y_i\right) - \left(\sum_{i=1}^n \tilde X_{1i}\tilde X_{2i}\right) \left(\sum_{i=1}^n \tilde X_{2i}\tilde Y_i\right) }{ \left(\sum_{i=1}^n \tilde X_{1i}^2\right) \left(\sum_{i=1}^n \tilde X_{2i}^2\right) - \left(\sum_{i=1}^n \tilde X_{1i}\tilde X_{2i}\right)^2 }
となり、これは直前に出した重回帰の \hat\beta_1 の公式と同じである。結論として、
\hat b=\hat\beta_1
である。
重要FWL定理の読み方
重回帰 Y_i=\beta_0+\beta_1X_{1i}+\beta_2X_{2i}+u_i における X_1 の係数 \hat\beta_1 は、
- X_1 から X_2 で説明できる部分を取り除く
- Y から X_2 で説明できる部分を取り除く
- その残りどうしを単回帰する
ことで得られる係数と同じである。
図で見る:予測できる部分と残り
まず、横軸 X_2、縦軸 X_1 の散布図を考える。回帰直線で予測される部分が \hat X_{1i}、点から回帰直線までの縦のズレが v_i である。
次に、横軸 X_2、縦軸 Y の散布図を考える。回帰直線で予測される部分が \hat Y_i、点から回帰直線までの縦のズレが r_i である。
最後に、横軸 v_i、縦軸 r_i の散布図を描き、その単回帰直線の傾きを見る。この傾きが、もとの重回帰の \hat\beta_1 である。
左の図では、X_1 のうち X_2 で予測できる部分を回帰直線で表している。点から線までの縦のズレが v_i である。中央の図では、Y のうち X_2 で予測できる部分を回帰直線で表している。点から線までの縦のズレが r_i である。右の図では、その残りどうしを比べている。この右の図の傾きが、もとの重回帰における X_1 の係数である。
コントロール変数が複数あっても同じ
コントロール変数が複数ある場合も、考え方は同じである。たとえば、
Y_i= \beta_0+\beta_1X_{1i} +\beta_2X_{2i} +\cdots +\beta_KX_{Ki} +u_i
というモデルを考える。ここで関心があるのは X_1 の係数 \beta_1 で、X_2,\ldots,X_K はコントロール変数であるとする。
このときも、やることは同じである。まず、X_1 をコントロール変数で回帰する。
X_{1i} = a_0+a_2X_{2i}+\cdots+a_KX_{Ki}+v_i
ここで v_i は、X_1 のうち X_2,\ldots,X_K で説明できなかった残りである。
次に、Y をコントロール変数で回帰する。
Y_i = c_0+c_2X_{2i}+\cdots+c_KX_{Ki}+r_i
ここで r_i は、Y のうち X_2,\ldots,X_K で説明できなかった残りである。
最後に、
r_i = b v_i + \text{誤差}
を単回帰する。このときの \hat b が、もとの重回帰の \hat\beta_1 と一致する。
コントロール変数が1つだけなら、予測される部分は回帰直線で表せる。コントロール変数が2つなら、予測される部分は回帰平面で表せる。もっと多くなると図には描きにくくなるが、考え方は同じである。つまり、X_1 と Y から、コントロール変数で予測できる部分を取り除き、残った部分どうしを比べている。
とにかく重要なのは、先ほども述べた通り、
FOCの式を連立して解くと、OLS 推定量が得られる
という流れである。これは説明変数が何個あっても変わらない。FWL定理が教えてくれるように、重回帰の係数は「他の説明変数で説明できる部分を取り除いたあとに残る関係」として読むのがよい。
そして、パソコンはこういう連立方程式をとくという作業が大得意である。パソコンに任せよう。
この見方は、あとで出てくるバイアスや多重共線性の理解にも役に立つ。必要なコントロール変数を落とすと、取り除くべき部分が残ってしまう。逆に、説明変数どうしがあまりに似ていると、X_1 のうち他の変数では説明できない残り v_i が小さくなり、係数の推定が不安定になる。
重要ここからは推定量としての話
以下の不偏性・一致性・漸近正規性は、E[u_i\mid x_{1i},x_{2i}]=0 のような外生性条件の下で成り立つ。
OLS の性質:推定量としての性質
単回帰の時に見た性質は全てこちらでも成立する。基本的にはLecture 3を参照してもらうとして、ざっと書いておく
重回帰においても OLSをSSE最小化として定義しただけで必ず成り立つ性質 をまとめる。 つまり、データ (x_{1i},x_{2i},y_i) が与えられたら、必ずそうなるという話だけをする。
以下では、OLSで得られた係数を
(\widehat{\beta}_0,\widehat{\beta}_1,\widehat{\beta}_2)
とし、予測値と残差を
\widehat{y}_i=\widehat{\beta}_0+\widehat{\beta}_1x_{1i}+\widehat{\beta}_2x_{2i}, \qquad \widehat{e}_i=y_i-\widehat{y}_i
と書く。
(P1) 回帰平面は平均点を通る
各変数の平均を
\bar{x}_1=\frac{1}{n}\sum_{i=1}^n x_{1i},\qquad \bar{x}_2=\frac{1}{n}\sum_{i=1}^n x_{2i},\qquad \bar{y}=\frac{1}{n}\sum_{i=1}^n y_i
とする。
このとき、OLSで得られた回帰平面は必ず
\bar{y} = \widehat{\beta}_0+\widehat{\beta}_1\bar{x}_1+\widehat{\beta}_2\bar{x}_2
を満たす。
つまり、単回帰で「回帰直線が平均点 (\bar{x},\bar{y}) を通る」と言ったのに対応して、重回帰では 回帰平面が (\bar{x}_1,\bar{x}_2,\bar{y}) を通る ことになる。
直感としては、データ全体の「重心」を回帰平面が通る、と思えばよい。
(P2) 残差の和は0
OLSで得られた残差は必ず
\sum_{i=1}^n \widehat{e}_i=0
を満たす。
これは単回帰のときとまったく同じである。 定数項が入っているOLSでは、残差のプラスとマイナスがちょうど打ち消し合う。
(P3) 残差は各説明変数と直交する
重回帰では、残差は各説明変数とも「積の和」が0になる。
具体的には
\sum_{i=1}^n x_{1i}\widehat{e}_i=0, \qquad \sum_{i=1}^n x_{2i}\widehat{e}_i=0
が成り立つ。
さらに、残差の和が0であることと合わせると、
\sum_{i=1}^n (x_{1i}-\bar{x}_1)\widehat{e}_i=0, \qquad \sum_{i=1}^n (x_{2i}-\bar{x}_2)\widehat{e}_i=0
とも書ける。
この性質の直感は単回帰と同じである。
- もし x_1 が大きいほど残差が系統的にプラスなら、\widehat{\beta}_1 を少し動かせばSSEがもっと下がるはず
- もし x_2 が大きいほど残差が系統的にプラスまたはマイナスなら、\widehat{\beta}_2 を少し動かせばSSEがもっと下がるはず
OLSはすでにSSEを最小にしているので、そのような「まだ改善できる方向」が残っていてはいけない。 それが、残差と各説明変数の直交性に対応している。
(P4) 予測値の平均は実際の平均に一致する
(P1) を見ればすぐわかるように、予測値の平均は実際の y の平均に一致する。
実際、
\frac{1}{n}\sum_{i=1}^n \widehat{y}_i = \widehat{\beta}_0+\widehat{\beta}_1\bar{x}_1+\widehat{\beta}_2\bar{x}_2 = \bar{y}
である。
したがって、
\overline{\widehat{y}}=\bar{y}
が成り立つ。
これは「OLSは少なくとも平均の水準はきちんと合わせている」という意味で理解できる。
(P5) 分散分解(TSS = ESS + SSE)と R^2
各点で
y_i=\widehat{y}_i+\widehat{e}_i
が成り立つのは定義そのものである。
ここから、y の平均からのズレの二乗和
\sum_{i=1}^n (y_i-\bar{y})^2
を考える。これを y 全体のばらつきとみなす。
OLSでは、単回帰と同じく次の分散分解が成り立つ:
\sum_{i=1}^n (y_i-\bar{y})^2 = \sum_{i=1}^n (\widehat{y}_i-\bar{y})^2 + \sum_{i=1}^n \widehat{e}_i^2
左辺を TSS、右辺第1項を ESS、第2項を SSE と呼ぶことが多い。
この分解が成り立つ理由は、OLSでは
\sum_{i=1}^n \widehat{e}_i(\widehat{y}_i-\bar{y})=0
が成り立つからである。 つまり、予測値の変動部分と残差部分が直交している。
決定係数 R^2 を
R^2 \equiv \frac{\sum_{i=1}^n (\widehat{y}_i-\bar{y})^2} {\sum_{i=1}^n (y_i-\bar{y})^2}
と定義すると、分散分解より
R^2 = 1- \frac{\sum_{i=1}^n \widehat{e}_i^2} {\sum_{i=1}^n (y_i-\bar{y})^2}
とも書ける。
したがって R^2 は、 y の全体のばらつきのうち、回帰式が説明できた割合 として理解できる。
(P6) 単位変更(尺度変換)に対するふるまい
たとえば x_1 の単位を変えて
x_{1i}'=c x_{1i}
とする。 このとき、同じ予測値を保つには、新しい回帰式
\widehat{y}_i=\beta_0'+\beta_1'x_{1i}'+\beta_2'x_{2i}
の係数は
\beta_0'=\widehat{\beta}_0,\qquad \beta_1'=\frac{\widehat{\beta}_1}{c},\qquad \beta_2'=\widehat{\beta}_2
となる。
つまり、
- x_1 を c 倍すると、その係数は 1/c 倍になる
- 他の変数の係数と予測値は変わらない
同様に、x_2 の単位を変えれば \widehat{\beta}_2 だけが逆向きに調整される。
要するに、係数の大きさそのものは変数の単位に依存する。 したがって、係数の数値を読むときは「この変数は何の単位で測られているのか」に注意が必要である。
(P7) 平行移動(原点の取り方)に対するふるまい
次に、説明変数の原点だけをずらして
x_{1i}'=x_{1i}+c_1,\qquad x_{2i}'=x_{2i}+c_2
とする。
このとき同じ予測値を保つには、傾きは変わらず、切片だけが調整される。 実際、
\beta_1'=\widehat{\beta}_1,\qquad \beta_2'=\widehat{\beta}_2
であり、
\beta_0' = \widehat{\beta}_0-\widehat{\beta}_1 c_1-\widehat{\beta}_2 c_2
となる。
つまり、
- 説明変数に定数を足しても、傾きは変わらない
- その代わり切片が調整される
という性質がある。
この性質は、説明変数を平均中心化するときに便利である。 たとえば
x_{1i}'=x_{1i}-\bar{x}_1,\qquad x_{2i}'=x_{2i}-\bar{x}_2
とすると、新しい変数の平均は 0 になるので、(P1) より
\beta_0'=\bar{y}
となる。 つまり、平均中心化した変数で回帰すると、切片は y の平均そのものになる。
ここからは、単なる「SSE最小化の定義から自動的に出てくる性質」ではなく、 重回帰モデルが正しく指定されていて、誤差項が説明変数と系統的に関係していない という仮定の下での性質を述べる。
重回帰モデルを
y_i=\beta_0+\beta_1 x_{1i}+\beta_2 x_{2i}+u_i
と書こう。
そして、外生性の仮定として
E[u_i\mid x_{1i},x_{2i}]=0
を置く。
これは、「x_1 と x_2 を与えたとき、誤差項 u_i の平均は0」という仮定である。 この仮定が成り立っているとき、OLSは推定量として望ましい性質を持つ。
メインメッセージは単回帰と同じで、 重回帰の OLS もとてもよい推定量である ということである。
1. 不偏性
外生性
E[u_i\mid x_{1i},x_{2i}]=0
が成り立つとき、OLS推定量は不偏である。
つまり、
E[\hat\beta_0\mid X]=\beta_0,\qquad E[\hat\beta_1\mid X]=\beta_1,\qquad E[\hat\beta_2\mid X]=\beta_2
が成り立つ。ここで X は全ての説明変数のデータをまとめて表していると思えばよい。
特に重要なのは、\hat\beta_1 は x_2 をコントロールした上での x_1 の効果 を平均的に正しく当てている、ということである。
単回帰との違いは、重回帰では \beta_1 の意味そのものが 「x_2 を一定にしたときの x_1 の部分効果」 になっている点である。
2. 分散と標準誤差の公式がある
重回帰OLSにも、単回帰と同じく分散の公式がある。
直感はやはり同じで、
- 誤差 u_i のばらつきが大きいほど、推定値はぶれやすい
- 説明変数に十分なばらつきがあるほど、係数は精密に推定しやすい
- サンプルサイズ n が大きいほど、標準誤差は小さくなる
というものである。
ただし重回帰では、\hat\beta_1 の分散は単純に x_1 の分散だけでは決まらない。 なぜなら x_1 と x_2 が強く相関していると、x_1 の「独自の変動」が少なくなり、\hat\beta_1 を精密に推定しにくくなるからである。
つまり、
- x_1 に十分なばらつきがあること
- しかもそのばらつきの中に、x_2 では説明できない独自部分があること
が重要になる。
重回帰でも標準誤差は、誤差分散の推定値を使って計算される。 そしてその標準誤差を使って、信頼区間や検定ができる。
3. 一致性
外生性が成り立ち、さらに標準的な正則条件が満たされると、OLS推定量は一致する。
つまり、
\hat\beta_0 \xrightarrow[]{p} \beta_0,\qquad \hat\beta_1 \xrightarrow[]{p} \beta_1,\qquad \hat\beta_2 \xrightarrow[]{p} \beta_2
が成り立つ。
意味としては、データが十分たくさん集まれば、推定値は真のパラメータに近づいていくということである。
重回帰で特に重要なのは、\hat\beta_1 は x_2 をコントロールした上での真の部分効果 \beta_1 に近づく、という点である。
4. 漸近正規性
サンプルサイズが大きくなると、OLS推定量は正規分布で近似できる。
たとえば \hat\beta_1 については、
\sqrt{n}(\hat\beta_1-\beta_1)\Rightarrow N(0,V_1)
のような形が成り立つ。
同様に \hat\beta_2 や \hat\beta_0 にも対応する漸近分布がある。
これにより、重回帰でも
- 信頼区間
- t検定
- p値
といった推論が可能になる。
したがって、重回帰OLSも単回帰OLSと同じく、 点推定だけでなく、その不確実性まで評価できる という意味で非常に便利である。
シミュレーション
ここでは、2変数の重回帰モデルを自分で人工的に作り、そのデータに対して実際にOLSを実行してみる。
目的は次の3つである。
- 重回帰で何を推定しているのかを具体的に見る
- 真の係数と推定値を比べる
- 回帰表に出てくる係数、標準誤差、t値、R^2 などの意味に慣れる
1. 人工データを作る
次のような真のモデルからデータを生成する。
Y_i = \beta_0 + \beta_1 X_{1i} + \beta_2 X_{2i} + u_i
ここでは真の値を
\beta_0 = 1,\qquad \beta_1 = 2,\qquad \beta_2 = -1
とする。
つまり、真のデータ生成過程は
Y_i = 1 + 2X_{1i} - X_{2i} + u_i
である。
以下のコードでは、まず X_1 を正規分布から発生させ、次に X_2 を X_1 と少し相関するように作る。 その上で、誤差項 u を加えて Y を作る。
set.seed(123)
n <- 500
# 説明変数を生成
x1 <- rnorm(n, mean = 0, sd = 1)
x2 <- 0.5 * x1 + rnorm(n, mean = 0, sd = 1)
# 誤差項
u <- rnorm(n, mean = 0, sd = 1)
# 真のパラメータ
beta0 <- 1
beta1 <- 2
beta2 <- -1
# 被説明変数
y <- beta0 + beta1 * x1 + beta2 * x2 + u
# データフレームにまとめる
df <- data.frame(y = y, x1 = x1, x2 = x2)
head(df) y x1 x2
1 -0.2346193 -0.56047565 -0.8821307
2 0.6084773 -0.23017749 -1.1087873
3 2.2932972 1.55870831 1.8061392
4 0.2225262 0.07050839 0.7863155
5 0.1537554 0.12928774 -1.4445227
6 4.7083184 1.71506499 0.7623850このコードでは、x_1 と x_2 が少し相関するようにしてある。 これは現実のデータで説明変数どうしが無関係とは限らないことを意識した設定である。
2. 重回帰を実行する
このデータに対して、次の重回帰を実行する。
Y_i = \beta_0 + \beta_1 X_{1i} + \beta_2 X_{2i} + u_i
R では lm() を使えばよい。
fit <- lm(y ~ x1 + x2, data = df)
summary(fit)
Call:
lm(formula = y ~ x1 + x2, data = df)
Residuals:
Min 1Q Median 3Q Max
-2.7201 -0.6886 0.0193 0.6573 3.2828
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.02415 0.04438 23.08 <2e-16 ***
x1 2.03617 0.04967 40.99 <2e-16 ***
x2 -0.94686 0.04397 -21.53 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.9917 on 497 degrees of freedom
Multiple R-squared: 0.7752, Adjusted R-squared: 0.7743
F-statistic: 857.1 on 2 and 497 DF, p-value: < 2.2e-16この出力が、回帰表である。
3. 推定値と真の値を比べる
実際に、真の値と推定値を並べてみよう。
true_values <- c("(Intercept)" = beta0, "x1" = beta1, "x2" = beta2)
estimated_values <- coef(fit)
comparison <- data.frame(
term = names(estimated_values),
true_value = true_values[names(estimated_values)],
estimate = as.numeric(estimated_values)
)
comparison term true_value estimate
(Intercept) (Intercept) 1 1.0241545
x1 x1 2 2.0361708
x2 x2 -1 -0.9468557この表を見ると、OLSが真の値にかなり近い係数を返していることが確認できる。
4. モデルを間違えた時
せっかくなので、x_2 を落として単回帰したときに何が起こるかも見てみよう。
つまり、本当は
Y_i = 1 + 2X_{1i} - X_{2i} + u_i
なのに、誤って
Y_i = a + bX_{1i} + e_i
だけを推定してみる。
fit_short <- lm(y ~ x1, data = df)
summary(fit_short)
Call:
lm(formula = y ~ x1, data = df)
Residuals:
Min 1Q Median 3Q Max
-4.1244 -0.9213 -0.0738 0.9509 4.6064
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.02460 0.06163 16.62 <2e-16 ***
x1 1.61385 0.06338 25.46 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 1.377 on 498 degrees of freedom
Multiple R-squared: 0.5656, Adjusted R-squared: 0.5647
F-statistic: 648.3 on 1 and 498 DF, p-value: < 2.2e-16もし x_1 と x_2 が相関していて、しかも x_2 が y に影響しているなら、x_2 を落とした単回帰の係数は正しい値を回復できない
こういう状況では、推定値に バイアス(bias)がかかっているという。次に、このバイアスについてより詳しく見る。
6. まとめ
このシミュレーションでは、真のモデル
Y_i = 1 + 2X_{1i} - X_{2i} + u_i
から人工データを生成し、そのデータに対して重回帰を実行した。
その結果、
- 重回帰OLSは真の係数に近い値を返すこと
- 回帰表には係数、標準誤差、t値、p値などが表示されること
- 本当は必要な変数を落とすと、係数がずれてしまうこと
を確認できた。
このように、重回帰は「他の条件を揃えた上での関係」を推定するための基本的な道具になっている。
警告ここが計量経済学の核心
重回帰を入れたからといって、自動的に問題が解決するわけではない。
説明変数と誤差項が相関してしまうと、OLS にはバイアスが生じる。
バイアス
計量経済学で最も重要なバイアスは、外生性の仮定
E[u_i \mid X_i] = 0
が崩れることで生じるものである。
教科書には、内生性バイアス、欠落変数バイアス、同時性バイアス、測定誤差バイアスなど、さまざまな名前のついたバイアスが登場する。 しかし、少なくとも回帰分析の基本的な理解としては、それらをバラバラに暗記する必要はない。
大事なのは、説明変数 X_i が誤差項 u_i と相関してしまうと、OLS は本来推定したい係数からずれてしまう、という一点である。
ここでは、そのズレがどのように生じるのかを数式で確認する。 具体的な目標は、
この specification だと、推定値は上にずれそうか、下にずれそうか
を予想できるようになることである。
1. バイアスとは何か
まず、推定量 \hat\beta_1 の バイアス とは、
E[\hat\beta_1] - \beta_1
のことである。
つまり、何度も標本を取り直してそのたびに推定を繰り返したとき、推定量の平均が真の値 \beta_1 からどれだけずれているかを表す。
- これが 0 なら 不偏
- 0 でなければ バイアスがある
という。
したがって、バイアスとは「たまたま一回の推定でずれた」という話ではなく、 平均的に見て系統的にずれているかどうか の話である。
2. 単回帰でバイアスのメカニズムを見る
まず、単回帰モデル
Y_i = \beta_0 + \beta_1 X_i + u_i
を考える。
OLS 推定量は
\hat\beta_1 = \frac{\sum_{i=1}^n (X_i-\bar X)(Y_i-\bar Y)}{\sum_{i=1}^n (X_i-\bar X)^2}
である。
ここに真のモデル
Y_i = \beta_0 + \beta_1 X_i + u_i
を代入すると、
\hat\beta_1 = \frac{\sum_{i=1}^n (X_i-\bar X)\bigl(\beta_0+\beta_1X_i+u_i-\bar Y\bigr)} {\sum_{i=1}^n (X_i-\bar X)^2}
となる。整理すると、
\hat\beta_1 - \beta_1 = \frac{\sum_{i=1}^n (X_i-\bar X)u_i}{\sum_{i=1}^n (X_i-\bar X)^2}
が得られる。
これはとても重要な式である。 この式は、OLS の誤差が X_i とu_i の共変動 から生まれていることを示している。
3. 外生性が成り立つとき
もし
E[u_i \mid X_i] = 0
が成り立つなら、ざっくり言えば X_i の大きい観測だからといって u_i が平均的にプラスになったりマイナスになったりしない。
このとき、
E[\hat\beta_1 \mid X_1,\dots,X_n] = \beta_1
が成り立ち、したがって
E[\hat\beta_1] = \beta_1
となる。
つまり、OLS は不偏である。
ここでのメッセージは単純で、
説明変数 X_i が誤差項 u_i と無関係なら、OLS は平均的に正しい
ということである。
4. 外生性が崩れると何が起こるか
一方で、
E[u_i \mid X_i] \neq 0
なら、X_i の大きさと u_i の大きさに系統的な関係があることになる。
すると、先ほどの式
\hat\beta_1 - \beta_1 = \frac{\sum_{i=1}^n (X_i-\bar X)u_i}{\sum_{i=1}^n (X_i-\bar X)^2}
の分子が平均的に 0 ではなくなる。 その結果、
E[\hat\beta_1] \neq \beta_1
となり、OLS にバイアスが生じる。
つまり、OLS の係数は 真の因果効果 \beta_1 だけでなく、X_i と誤差項 u_i の相関も拾ってしまう のである。
5. バイアスの向きはどう決まるか
重要なのは、バイアスがあるかどうか だけでなく、 どちら向きにバイアスがかかるか を考えられるようになることである。
上の式を見ると、
\hat\beta_1 - \beta_1 = \frac{\sum_{i=1}^n (X_i-\bar X)u_i}{\sum_{i=1}^n (X_i-\bar X)^2}
であり、分母は常に正である。 したがって、バイアスの向きは分子
\sum_{i=1}^n (X_i-\bar X)u_i
の符号で決まる。
つまり、
- X_i が大きい観測ほど u_i もプラスになりやすいなら、\hat\beta_1 は 上方バイアス
- X_i が大きい観測ほど u_i がマイナスになりやすいなら、\hat\beta_1 は 下方バイアス
になる。
6. 欠落変数バイアスの見方
このメカニズムが最もわかりやすく現れるのが、コントロール変数を落としてしまった時に出てくるバイアスである。これを欠落変数バイアスと呼んだりする。
たとえば真のモデルが
Y_i = \beta_0 + \beta_1 X_i + \beta_2 Z_i + u_i
だったとする。 ここで Z_i は本当は入れるべき変数だが、観測できないので回帰から落としてしまったとする。
すると、実際に推定する式は
Y_i = a + bX_i + e_i
となる。
このとき誤差項 e_i の中には、本来入れるべきだった
\beta_2 Z_i
が入ってしまう。つまり、
e_i = \beta_2 Z_i + u_i
である。
この時、
E[e_i \mid X_i] = \beta_2 E[Z_i \mid X_i] + E[u_i\mid X_i] = \beta_2 E[Z_i \mid X_i]
となる。
ここで、何らかの定数\mu_zについて
E[Z_i \mid X_i] = \mu_z
だったら、e_iを定数\mu_z分ずらして定数項aに\mu_z押し付けることで、
E[e_i \mid X_i] = 0
とできる。(これは回帰の性質で見た話である)
しかし、
E[Z_i \mid X_i] = \mu_z(X_i)
のように、これが定数ではなく X_i の関数であったとしよう。
すなわち、Z_i は平均的に X_i と一緒に動いており、Z_i と X_i の間に相関関係があることを意味している。
この時、
E[e_i \mid X_i] = \beta_2 \mu_z(X_i)
となって、定数項だけのずらしでは外生性の仮定を満たせなくなってしまう。
これによって OLS にバイアスが生じる。
具体的には、単回帰の OLS 推定量は
\hat{\beta}_1 = \frac{\sum_{i=1}^n (X_i-\bar X)Y_i}{\sum_{i=1}^n (X_i-\bar X)^2}
である。ここで真のモデル
Y_i=\beta_0+\beta_1 X_i+\beta_2 Z_i+u_i
を代入すると、
\hat{\beta}_1 = \beta_1 + \beta_2 \frac{\sum_{i=1}^n (X_i-\bar X)Z_i}{\sum_{i=1}^n (X_i-\bar X)^2} + \frac{\sum_{i=1}^n (X_i-\bar X)u_i}{\sum_{i=1}^n (X_i-\bar X)^2}
となる。
したがって、E[u_i\mid X_i]=0 を仮定すると、最後の項の期待値は 0 なので、
E[\hat{\beta}_1\mid X_1,\dots,X_n] = \beta_1 + \beta_2 \frac{\sum_{i=1}^n (X_i-\bar X)E[Z_i\mid X_i]}{\sum_{i=1}^n (X_i-\bar X)^2}
となる。すなわち、
E[\hat{\beta}_1\mid X_1,\dots,X_n]-\beta_1 = \beta_2 \frac{\sum_{i=1}^n (X_i-\bar X)\mu_z(X_i)}{\sum_{i=1}^n (X_i-\bar X)^2}
である。
これが、欠落変数 Z_i によるバイアスの一般的な形である。
特に、Z_i の条件付き平均が X_i に対してほぼ線形に
E[Z_i\mid X_i]=\pi_0+\pi_1 X_i
と書けるなら、
E[\hat{\beta}_1\mid X_1,\dots,X_n]-\beta_1 = \beta_2 \pi_1
となる。
したがって、バイアスの向きは
- Z_i が Y_i に与える影響の符号(\beta_2 の符号)
- X_i と Z_i の相関の符号(\mathrm{Cov}(X_i,Z_i) の符号, linear modelなら\pi_1)
の 2 つで決まる。
たとえば、
- \beta_2>0 で
- \mathrm{Cov}(X_i,Z_i)>0
なら、\hat{\beta}_1 には 上方バイアス がかかる。
逆に、
- \beta_2>0 で
- \mathrm{Cov}(X_i,Z_i)<0
なら、\hat{\beta}_1 には 下方バイアス がかかる。
つまり、欠落変数バイアスとは、X_i と相関した別の要因 Z_i の効果を、OLS が X_i の効果として誤って拾ってしまうことなのである。
7. 教育と賃金の例
教育年数 X_i が賃金 Y_i に与える効果を知りたいとしよう。 しかし、本当は能力 Z_i も賃金に影響している。
真のモデルは
\mathrm{Wage}_i = \beta_0 + \beta_1 \mathrm{Education}_i + \beta_2 \mathrm{Ability}_i + u_i
だとする。
ところが能力が観測できないので、実際には
\mathrm{Wage}_i = a + b\,\mathrm{Education}_i + e_i
だけを推定してしまう。
このとき、
- 能力が高いほど賃金は高い (\beta_2>0)
- 能力が高い人ほど教育年数も長い
なら、教育年数の係数 b には 上方バイアス がかかる。
つまり、OLS は教育の真の効果だけでなく、能力の効果の一部まで教育年数の係数に押しつけてしまう。
意地悪な例:誤差項が説明変数と明らかに関係するのにバイアスが出ない
X_i \sim N(0,1)
として、
E[Z_i\mid X_i]=\mu_z(X_i)=X_i^2-1
とする。
これは明らかに X_i の関数なので、X_i は Z_i に影響していて、しかも \mu_z(X_i) は 0 定数ではない。
しかし、
E[X_i(X_i^2-1)] = E[X_i^3]-E[X_i]=0-0=0
なので、X_i と \mu_z(X_i) は共分散 0 。したがって、線形回帰での傾きバイアスは出ない。
真のモデルを
Y_i=\beta_0+\beta_1 X_i+\beta_2 Z_i+u_i
とし、さらに
Z_i=(X_i^2-1)+v_i
と置けば、
Y_i=\beta_0+\beta_1 X_i+\beta_2(X_i^2-1)+(\beta_2 v_i+u_i)
ここで Y_i を X_i だけに回帰すると、X_i^2-1 を落としているのでモデルは misspecified だが、X_i との共分散が 0 なので、\beta_1 の推定値は平均的にはずれない。
set.seed(123)
R <- 2000
n <- 1000
beta0 <- 1
beta1 <- 2
beta2 <- 3
b1_hat_simple <- numeric(R)
b1_hat_quad <- numeric(R)
for (r in 1:R) {
x <- rnorm(n)
v <- rnorm(n, sd = 1)
u <- rnorm(n, sd = 1)
z <- (x^2 - 1) + v
y <- beta0 + beta1 * x + beta2 * z + u
fit1 <- lm(y ~ x)
fit2 <- lm(y ~ x + I(x^2 - 1))
b1_hat_simple[r] <- coef(fit1)["x"]
b1_hat_quad[r] <- coef(fit2)["x"]
}
mean(b1_hat_simple)[1] 2.000432mean(b1_hat_quad)[1] 1.99753sd(b1_hat_simple)[1] 0.3203404sd(b1_hat_quad)[1] 0.1044253hist(b1_hat_simple, breaks = 40,
main = "Distribution of slope estimates from lm(y ~ x)",
xlab = expression(hat(beta)[1]))
abline(v = beta1, lwd = 2, lty = 2)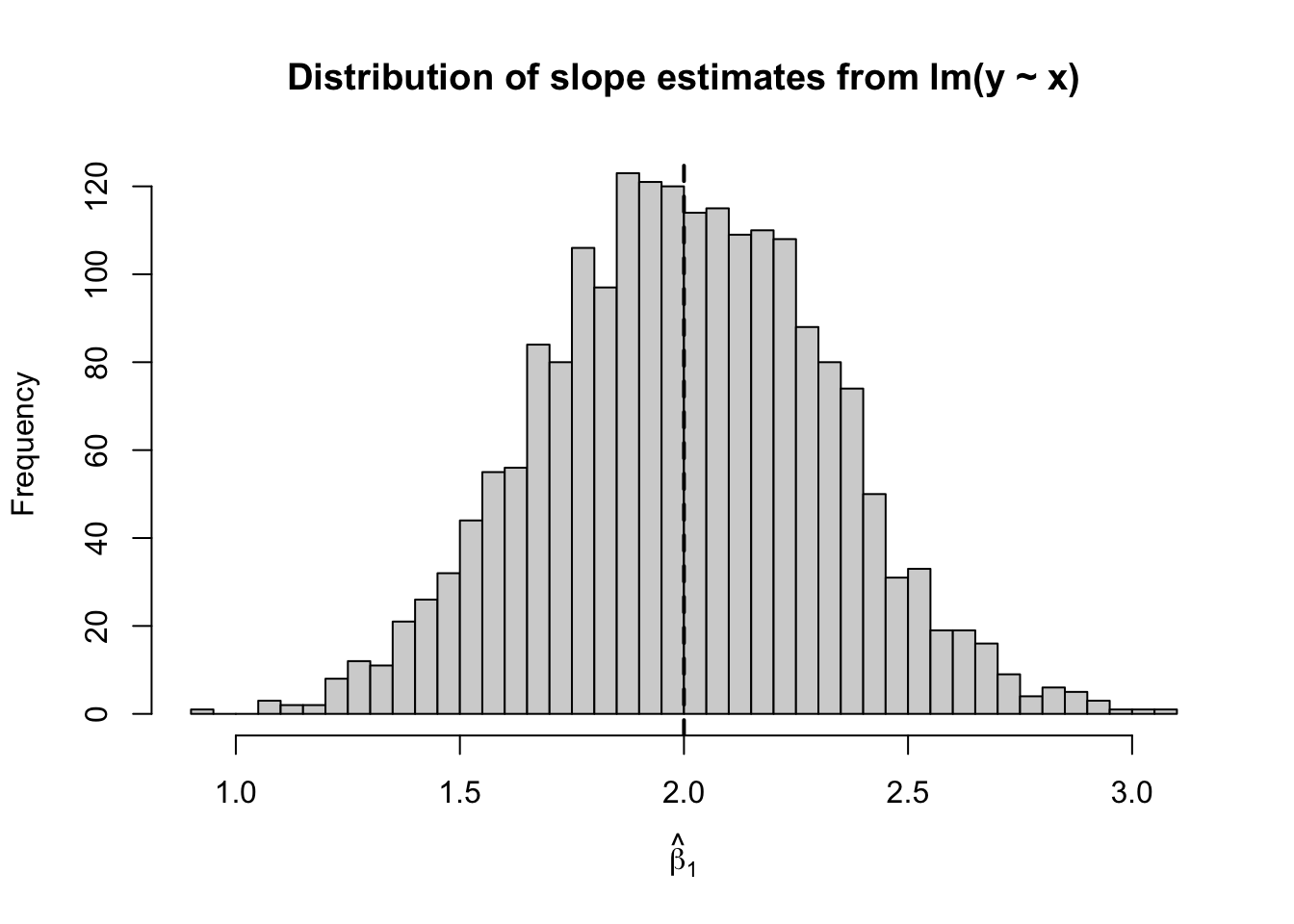
hist(b1_hat_quad, breaks = 40,
main = "Distribution of slope estimates from lm(y ~ x + I(x^2 - 1))",
xlab = expression(hat(beta)[1]))
abline(v = beta1, lwd = 2, lty = 2)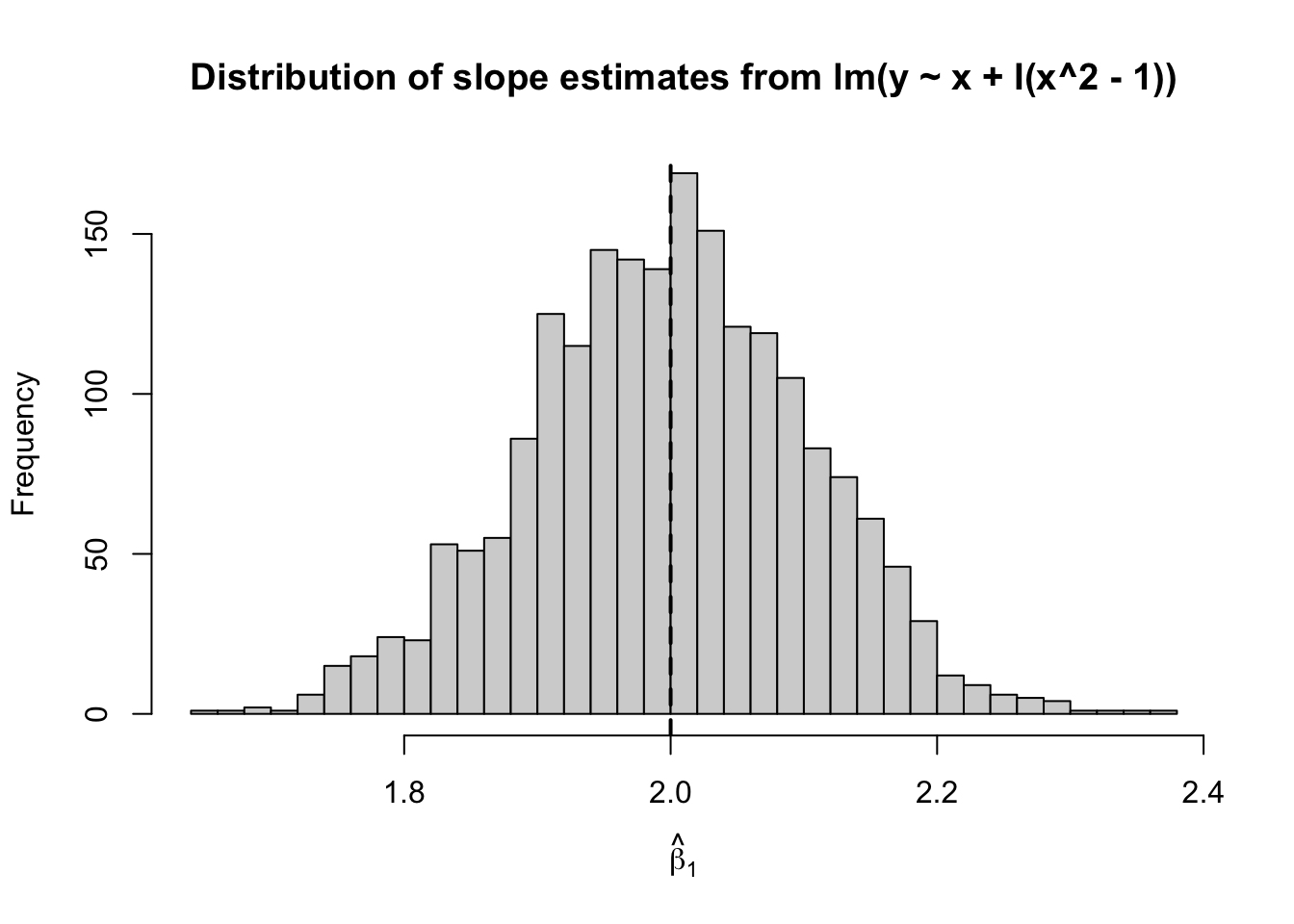
このシミュレーションからわかること
この例では、欠落変数 Z_i はたしかに X_i によって平均的に決まっている。 実際、
E[Z_i\mid X_i]=X_i^2-1
なので、X_i と Z_i の間には明確な関係がある。
しかしその関係は 二次的 であり、X_i の一次式とは直交している。したがって、
\mathrm{Cov}(X_i,Z_i)=0
となり、単回帰での傾き \hat\beta_1 には平均的なバイアスが生じない。
ただし、これは「問題がない」という意味ではない。 真の条件付き平均は
E[Y_i\mid X_i] = \beta_0+\beta_1 X_i+\beta_2(X_i^2-1)
であり、X_i の二次項を含む。したがって Y_i を X_i だけで回帰したモデルは平均関数を正しく表していない。 つまりこのケースでは、欠落変数はあるが、単回帰の傾きにはバイアスが出ない という、少し意地悪な例になっている。
多重共線性
ここまでは、外生性が崩れると OLS にバイアスが生じる、という話をしてきた。
次は別の問題として、多重共線性を考える。
多重共線性は、説明変数どうしが強く相関しているときに起きる問題である。
大事なのは、これはバイアスの問題ではないということだ。
外生性が成り立っていれば、OLS は依然として平均的には正しい値を狙っている。
しかし、説明変数どうしが似すぎていると、それぞれの変数の「独立した効果」を切り分けることが難しくなり、推定値が不安定になったり、標準誤差が大きくなったりする。
このセクションでは、まず数式で何が起きているかを確認し、その後シミュレーションで実際に見ていく。
1. 多重共線性とは何か
次のモデルを考える。
Y_i = \beta_0 + \beta_1 X_{1i} + \beta_2 X_{2i} + u_i
ここで、X_{1i} と X_{2i} の間に強い相関があるとする。
たとえば、学歴とテストスコア、広告費と販促費、面積と部屋数のように、現実のデータでは説明変数どうしがかなり似た動きをすることが多い。
このとき回帰は、X_1 を固定したまま X_2 を変化させたときの効果、あるいは X_2 を固定したまま X_1 を変化させたときの効果を推定しようとする。
しかし X_1 と X_2 がほとんど同じように動いてしまうと、「片方だけを動かす」という状況がデータの中でほとんど観察されない。
その結果、
- 係数推定値が不安定になる
- 標準誤差が大きくなる
- t値が小さくなり、有意でなくなりやすい
- サンプルを少し変えただけで係数が大きく動く
といったことが起こる。
2. バイアスとの違い
多重共線性は、しばしば「回帰がダメになる」と説明されるが、正確にはそうではない。
外生性が成り立っていれば、
E[u_i \mid X_{1i}, X_{2i}] = 0
なので、OLS は平均的には \beta_1, \beta_2 を正しく狙う。
つまり、多重共線性それ自体はバイアスを生まない。
問題は、推定量の分散が大きくなることにある。
3. 2変数回帰での見方
先ほどの \hat{\beta}_1 と \hat{\beta}_2 の「公式」を再掲する。
\hat\beta_1 = \frac{ \left(\sum_{i=1}^n \tilde X_{2i}^2\right) \left(\sum_{i=1}^n \tilde X_{1i}\tilde Y_i\right)- \left(\sum_{i=1}^n \tilde X_{1i}\tilde X_{2i}\right) \left(\sum_{i=1}^n \tilde X_{2i}\tilde Y_i\right) }{ \left(\sum_{i=1}^n \tilde X_{1i}^2\right) \left(\sum_{i=1}^n \tilde X_{2i}^2\right) - \left(\sum_{i=1}^n \tilde X_{1i}\tilde X_{2i}\right)^2 }
\hat\beta_2 = \frac{ \left(\sum_{i=1}^n \tilde X_{1i}^2\right) \left(\sum_{i=1}^n \tilde X_{2i}\tilde Y_i\right)- \left(\sum_{i=1}^n \tilde X_{1i}\tilde X_{2i}\right) \left(\sum_{i=1}^n \tilde X_{1i}\tilde Y_i\right) }{ \left(\sum_{i=1}^n \tilde X_{1i}^2\right) \left(\sum_{i=1}^n \tilde X_{2i}^2\right) - \left(\sum_{i=1}^n \tilde X_{1i}\tilde X_{2i}\right)^2 }
ここで、X_{1i}とX_{2i}が全てのサンプルで似たような値を取っている状況を考えよう。この時、
- 両方の推定量の分母は0に近くなる。
- さらに、分子も0に近くなる。
ことがわかる。
特に分母が0に近いことに起因して、ちょっとしたサンプルのズレですごい大きな推定値のズレを生んだりするということがわかるであろう。
4. 分散の式
単純化して書くと、\hat\beta_1 の分散は
\mathrm{Var}(\hat\beta_1 \mid X) = \frac{\sigma_u^2}{\sum_{i=1}^n (X_{1i} - \bar X_1)^2 (1-R_1^2)}
の形になる。(詳細な導出はここでは省略する。)
ここで R_1^2 は、X_1 を他の説明変数に回帰したときの決定係数である。
2変数の場合には、これはほぼ X_1 と X_2 の相関の強さを表している。
X_1 と X_2 の相関が強いほど R_1^2 は 1 に近づき、
1 - R_1^2
が小さくなる。
すると分母が小さくなるので、\hat\beta_1 の分散は大きくなる。
これが多重共線性の中心的なメカニズムである。
5. シミュレーションの設計
ここからはシミュレーションで確認する。
真のモデルを
Y_i = 1 + 2X_{1i} + 2X_{2i} + u_i
とする。
誤差項 u_i は平均 0 のノイズとする。
そして、X_1 と X_2 の相関だけを変えてみる。
相関が弱いケースでは、それぞれの係数は比較的安定して推定されるはずである。
一方、相関が非常に強いケースでは、係数推定値のばらつきが大きくなり、標準誤差も大きくなるはずである。
6. まずは1回だけ見てみる
set.seed(123)
n <- 500
x1 <- rnorm(n)
x2 <- 0.2 * x1 + sqrt(1 - 0.2^2) * rnorm(n)
u <- rnorm(n)
y <- 1 + 2 * x1 + 2 * x2 + u
fit <- lm(y ~ x1 + x2)
summary(fit)
Call:
lm(formula = y ~ x1 + x2)
Residuals:
Min 1Q Median 3Q Max
-2.7201 -0.6886 0.0193 0.6573 3.2828
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.02415 0.04438 23.08 <2e-16 ***
x1 2.05189 0.04611 44.50 <2e-16 ***
x2 2.05424 0.04488 45.77 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.9917 on 497 degrees of freedom
Multiple R-squared: 0.9054, Adjusted R-squared: 0.905
F-statistic: 2378 on 2 and 497 DF, p-value: < 2.2e-16cor(x1, x2)[1] 0.1431915この例では、X_1 と X_2 の相関はそれほど強くないので、両方の係数は比較的きれいに推定されるはずである。
次に、ほぼ同じ変数になってしまうケースを見てみる。
set.seed(123)
n <- 500
x1 <- rnorm(n)
x2 <- 0.98 * x1 + sqrt(1 - 0.98^2) * rnorm(n)
u <- rnorm(n)
y <- 1 + 2 * x1 + 2 * x2 + u
fit <- lm(y ~ x1 + x2)
summary(fit)
Call:
lm(formula = y ~ x1 + x2)
Residuals:
Min 1Q Median 3Q Max
-2.7201 -0.6886 0.0193 0.6573 3.2828
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.02415 0.04438 23.078 < 2e-16 ***
x1 1.80102 0.21899 8.224 1.73e-15 ***
x2 2.26706 0.22098 10.259 < 2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.9917 on 497 degrees of freedom
Multiple R-squared: 0.94, Adjusted R-squared: 0.9397
F-statistic: 3891 on 2 and 497 DF, p-value: < 2.2e-16cor(x1, x2)[1] 0.9780455この場合、真の係数は同じなのに、推定結果はかなり不安定になりやすい。 係数そのものは大きくぶれたり、標準誤差が大きくなったりする。
7. 相関の違いを図で見る
まず、相関が弱いときと強いときで、説明変数どうしの散布図がどう違うかを見てみよう。
set.seed(123)
n <- 500
x1_low <- rnorm(n)
x2_low <- 0.2 * x1_low + sqrt(1 - 0.2^2) * rnorm(n)
x1_high <- rnorm(n)
x2_high <- 0.98 * x1_high + sqrt(1 - 0.98^2) * rnorm(n)
par(mfrow = c(1, 2))
plot(x1_low, x2_low,
main = "Low correlation",
xlab = "x1", ylab = "x2")
plot(x1_high, x2_high,
main = "High correlation",
xlab = "x1", ylab = "x2")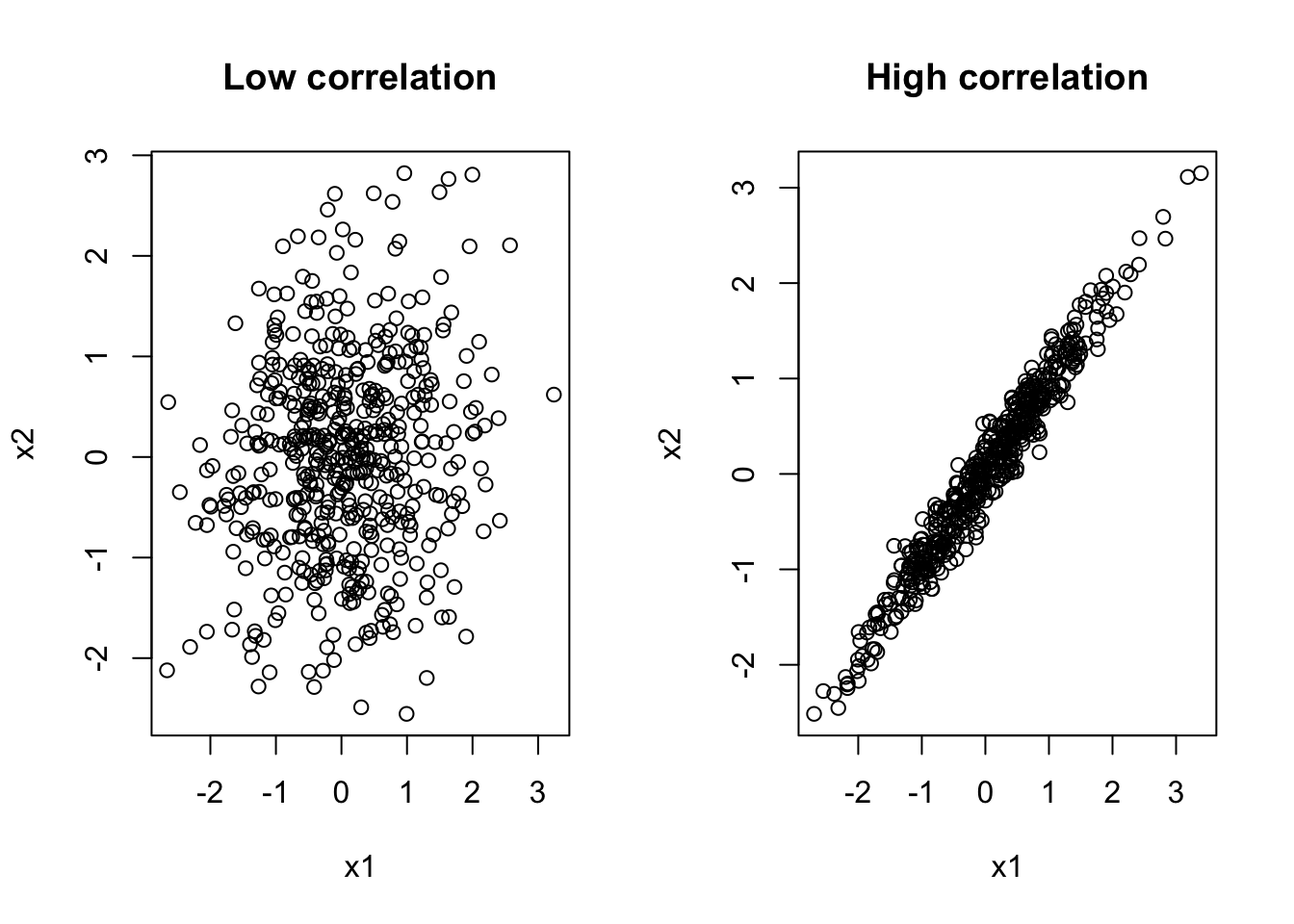
相関が低いときには、X_1 と X_2 はかなり独立に動いている。 一方、相関が高いときには、ほとんど一直線の上に点が並ぶ。 この場合、データは「X_1 だけが変わる」「X_2 だけが変わる」という variation をほとんど持たない。
8. 繰り返しシミュレーションで確認する
次に、相関が低いケースと高いケースで回帰を何度も繰り返し、\hat\beta_1 の分布を比べる。
simulate_b1 <- function(R, n, rho) {
b1hat <- numeric(R)
se1 <- numeric(R)
for (r in 1:R) {
x1 <- rnorm(n)
x2 <- rho * x1 + sqrt(1 - rho^2) * rnorm(n)
u <- rnorm(n)
y <- 1 + 2 * x1 + 2 * x2 + u
fit <- lm(y ~ x1 + x2)
summ <- summary(fit)$coefficients
b1hat[r] <- summ["x1", "Estimate"]
se1[r] <- summ["x1", "Std. Error"]
}
data.frame(b1hat = b1hat, se1 = se1)
}
set.seed(123)
res_low <- simulate_b1(R = 2000, n = 200, rho = 0.2)
res_high <- simulate_b1(R = 2000, n = 200, rho = 0.98)
mean(res_low$b1hat)[1] 1.999173mean(res_high$b1hat)[1] 2.015213mean(res_low$se1)[1] 0.07255275mean(res_high$se1)[1] 0.3581181ここで注目したいのは 2 点ある。
- \hat\beta_1 の平均は、どちらのケースでもだいたい真の値 2 に近い
- しかし、標準誤差の平均は高相関のケースでかなり大きくなる
つまり、多重共線性は平均的な正しさを壊すのではなく、精度を壊すのである。
9. 推定値の分布を比較する
# 共通のbreaksを作る
all_b1 <- c(res_low$b1hat, res_high$b1hat)
breaks_b1 <- pretty(range(all_b1), n = 40)
h_low <- hist(res_low$b1hat, breaks = breaks_b1, plot = FALSE)
h_high <- hist(res_high$b1hat, breaks = breaks_b1, plot = FALSE)
# 先に low correlation を描く
plot(h_low,
col = rgb(0, 0, 1, 0.4),
border = "white",
main = expression("Distribution of estimates of " * hat(beta)[1]),
xlab = expression(hat(beta)[1]),
xlim = range(breaks_b1),
ylim = c(0, max(h_low$counts, h_high$counts)))
# 上から high correlation を重ねる
plot(h_high,
col = rgb(1, 0, 0, 0.4),
border = "white",
add = TRUE)
# 真の値
abline(v = 2, lwd = 2, lty = 2)
legend("topright",
legend = c("Low correlation", "High correlation", "True value"),
fill = c(rgb(0, 0, 1, 0.4), rgb(1, 0, 0, 0.4), NA),
border = c("white", "white", NA),
lty = c(NA, NA, 2),
lwd = c(NA, NA, 2),
bty = "n")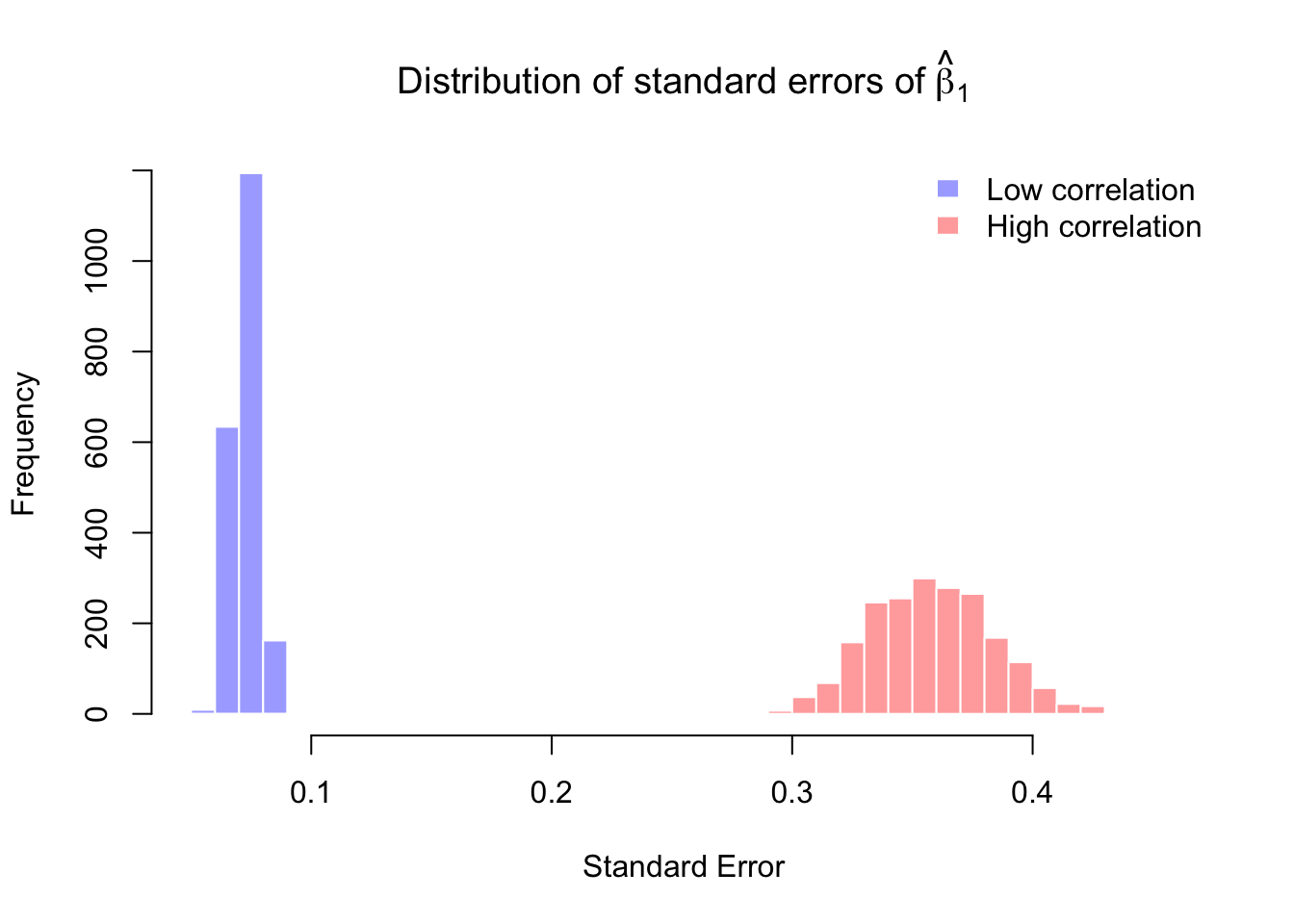
高相関のケースでは、\hat\beta_1 の分布がかなり広がるはずである。 真の値のまわりに中心はあるが、推定値のばらつきが大きい。
10. 標準誤差の分布も比べる
# 共通のbreaksを作る
all_se <- c(res_low$se1, res_high$se1)
breaks_se <- pretty(range(all_se), n = 40)
h_low_se <- hist(res_low$se1, breaks = breaks_se, plot = FALSE)
h_high_se <- hist(res_high$se1, breaks = breaks_se, plot = FALSE)
# 先に low correlation を描く
plot(h_low_se,
col = rgb(0, 0, 1, 0.4),
border = "white",
main = expression("Distribution of standard errors of " * hat(beta)[1]),
xlab = "Standard Error",
xlim = range(breaks_se),
ylim = c(0, max(h_low_se$counts, h_high_se$counts)))
# 上から high correlation を重ねる
plot(h_high_se,
col = rgb(1, 0, 0, 0.4),
border = "white",
add = TRUE)
legend("topright",
legend = c("Low correlation", "High correlation"),
fill = c(rgb(0, 0, 1, 0.4), rgb(1, 0, 0, 0.4)),
border = "white",
bty = "n")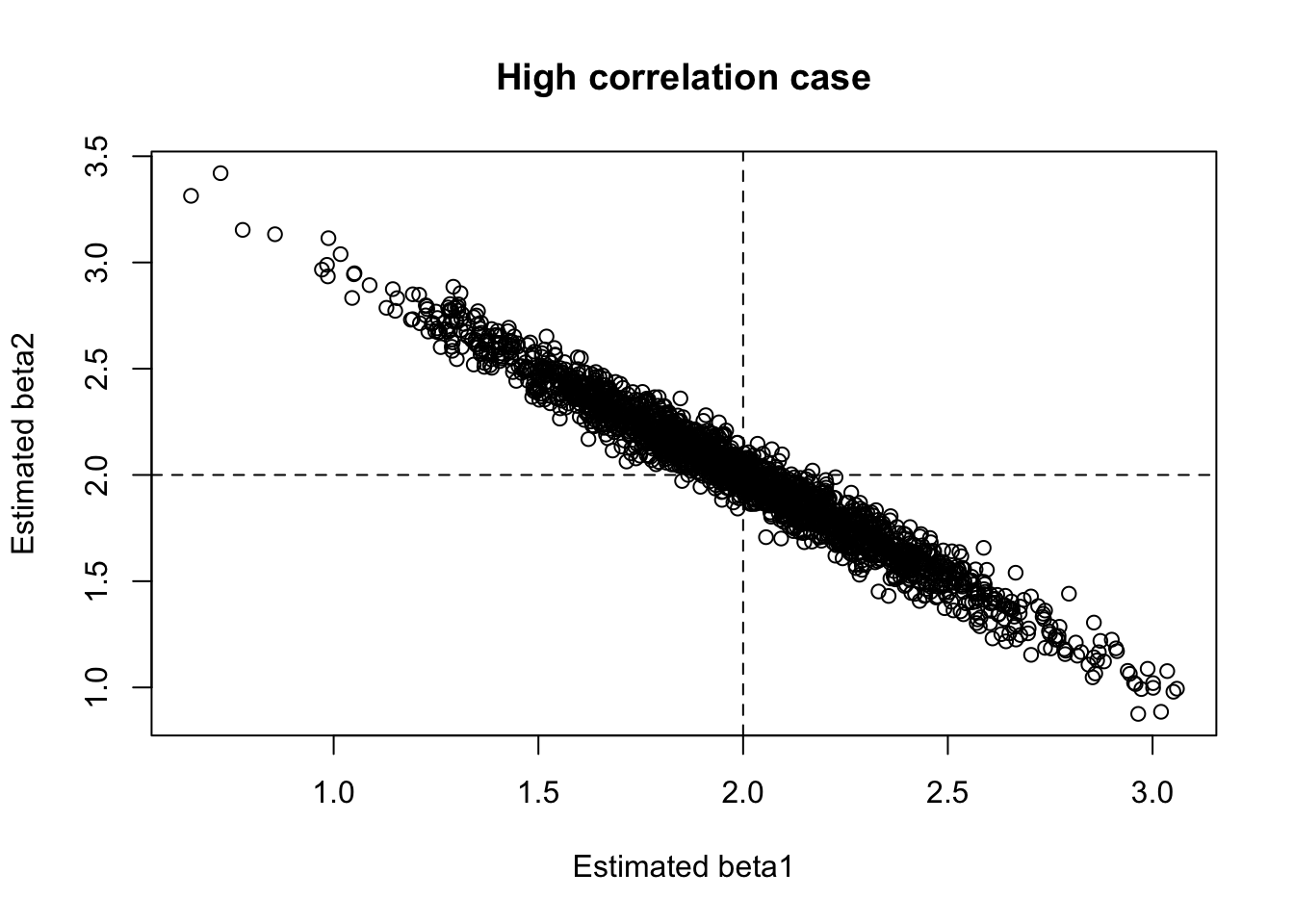
ここでは、高相関のケースで標準誤差が明らかに大きくなっていることが確認できるはずである。
11. 係数が不安定になる様子
多重共線性があると、X_1 と X_2 の係数は互いに押し合うような形でぶれやすい。 片方の係数が大きく出ると、もう片方が小さく出る、といったことが起きやすい。
それを見てみよう。
simulate_both <- function(R, n, rho) {
b1hat <- numeric(R)
b2hat <- numeric(R)
for (r in 1:R) {
x1 <- rnorm(n)
x2 <- rho * x1 + sqrt(1 - rho^2) * rnorm(n)
u <- rnorm(n)
y <- 1 + 2 * x1 + 2 * x2 + u
fit <- lm(y ~ x1 + x2)
b1hat[r] <- coef(fit)["x1"]
b2hat[r] <- coef(fit)["x2"]
}
data.frame(b1hat = b1hat, b2hat = b2hat)
}
set.seed(123)
res_both <- simulate_both(R = 2000, n = 200, rho = 0.98)
plot(res_both$b1hat, res_both$b2hat,
xlab = "Estimated beta1",
ylab = "Estimated beta2",
main = "High correlation case")
abline(v = 2, lty = 2)
abline(h = 2, lty = 2)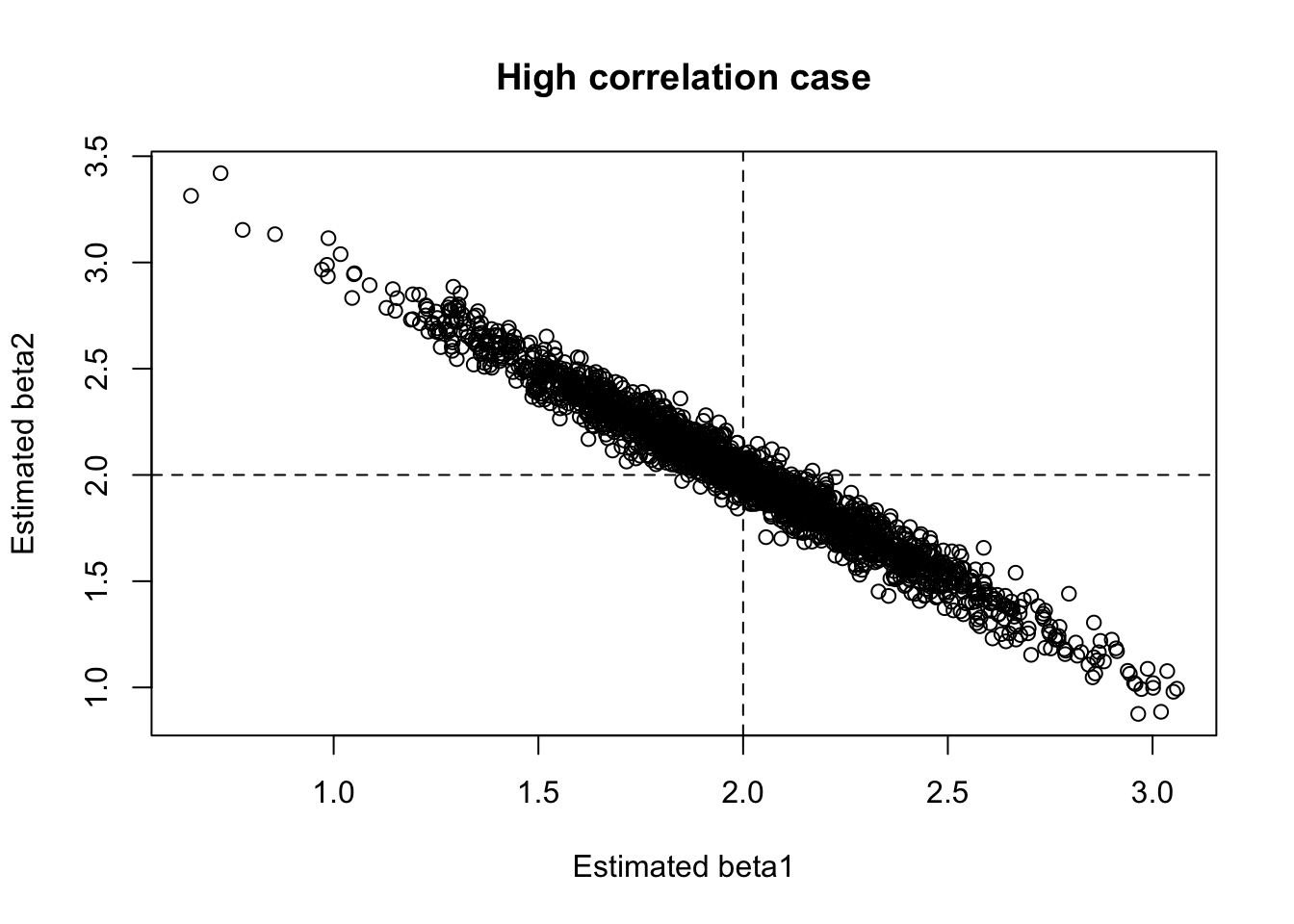
この図では、\hat\beta_1 と \hat\beta_2 が強く負の方向に動くことが多い。 これは、2つの説明変数が似すぎているため、「どちらに効果を割り振るか」が不安定になっていることを表している。
12. 実務的にどう考えるか
多重共線性が見つかったとき、考えるべきことは次のようなものである。
- 本当に別々の変数として入れる必要があるのか
- 片方を落としても解釈上問題ないか
- 合成指標を作ったほうが自然ではないか
- 個別係数ではなく、線形結合や予測そのものに関心があるのか
大事なのは、「有意でない = 効果がない」ではないということだ。 多重共線性のもとでは、推定の精度が落ちるので、真の効果があっても有意に出にくくなる。
13. まとめ
多重共線性とは、説明変数どうしが強く相関しているために、それぞれの独立した効果を切り分けにくくなる問題である。
この問題の本質は、バイアスではなく分散の増大にある。 外生性が成り立っていれば、OLS は平均的には正しい係数を狙っている。 しかし、説明変数どうしが似すぎていると、係数推定値は不安定になり、標準誤差が大きくなる。
したがって、多重共線性を見たときには、
- 係数の平均的な正しさ
- 推定の不安定さ
- 個別効果を識別したいのか、それとも全体の予測がしたいのか
を分けて考える必要がある。
宿題
- 次回は一旦ここまでの話でよくわからない部分についての質問に答える会とする
- 次回までに質問、疑問、不満などをまとめておくとよい
- githubでissueとして出してみよう
- (詳細な導出は省略) と書いたところの式展開を自分でしてみよう
- 再び、関数の最大化、最小化問題が出てきた。一階条件について忘れてた人は今回も復習しよう
- 重回帰のケースで二階条件をチェックしてみよう
- 連立方程式はパソコンに任せるわけだが、実際パソコンはどうやって連立方程式を解くのか、気になる人はchat gptに聞いてみよう