重回帰の応用
ここまでは、重回帰が「他の変数を一定にした上での関係」を見るための道具であること、そして欠落変数バイアスの考え方を学んだ。 このセクションでは、重回帰を使うと実際にどのような分析ができるのか を見ていく。
対数変数の時の係数の解釈
二次関数
交差項
多項式近似
ダミー変数
カテゴリー変数
個別の定数項を入れる:固定効果モデル
などを今回は見る。
重回帰の強みは、説明変数を増やせることそのものではない。
本当に重要なのは、変数の入れ方を工夫することで、さまざまな経済的関係を表現できること である。
後半では、重回帰の部品が実際の論文でどのように使われているのかを確認する。式の形そのものだけでなく、どの比較からどの主張を作っているのかを意識する。
1. 対数変数の時の係数の解釈
実証分析では、変数をそのまま使うのではなく、対数をとってから回帰に入れる ことが多い。 これは、金額・売上・賃金・人口のように、値のスケールが大きく、しかも「差」より「割合」で考えた方が自然な変数で特によく使われる。
対数を使うときは、どの変数に対数をとったかによって係数の解釈が変わる。
1.1 被説明変数だけ対数をとる場合
たとえば
\log y_i = \beta_0 + \beta_1 x_i + u_i
というモデルを考える。
このとき、x_i が1単位増えると、y_i はおよそ 100\beta_1 パーセント変化する。
つまり、\beta_1 = 0.03 なら、x が1増えると y はおよそ3%増える、と読む。
この形は、たとえば
教育年数が1年増えると賃金は何%変わるか
店舗面積が1単位増えると売上は何%変わるか
のような問いで便利である。
1.2 説明変数だけ対数をとる場合
次に
y_i = \beta_0 + \beta_1 \log x_i + u_i
を考える。
このとき、x_i が1%増えると、y_i はおよそ \beta_1/100 だけ変化する。
つまり、\beta_1 = 2 なら、x が1%増えると y は約0.02単位増える。
これは、説明変数の変化を「割合」で考えたいが、被説明変数は水準で解釈したいときに便利である。
1.3 両方とも対数をとる場合
さらに
\log y_i = \beta_0 + \beta_1 \log x_i + u_i
という形もよく使う。 これは log-log モデル と呼ばれる。
このとき \beta_1 は、x が1%増えたときに y が何%変化するかを表す。 つまり、\beta_1 は弾力性 である。
たとえば \beta_1 = 0.8 なら、x が1%増えると y は0.8%増える。
これは経済学ではとても重要で、需要関数や生産関数などで頻繁に使われる。
1.4 対数を使うときの注意
対数は便利だが、0以下の値にはとれない。 したがって、変数に0が多い場合や負の値をとる場合には、そのままでは使えない。
また、対数を使うと係数の解釈が水準ではなく割合になるので、何が何%変わるのか を常に意識して読む必要がある。
2. 二次関数
単回帰や重回帰というと「直線」を当てはめるイメージが強い。 しかし、説明変数を工夫すれば、曲線的な関係 も表現できる。
最も基本的なのが二次関数である。
y_i = \beta_0 + \beta_1 x_i + \beta_2 x_i^2 + u_i
このモデルでは、x と y の関係は放物線になる。
2.1 二次項を入れる意味
二次項を入れると、x の効果は一定ではなく、x の値によって変わる。
x の限界効果は
\frac{\partial y_i}{\partial x_i} = \beta_1 + 2\beta_2 x_i
で与えられる。
つまり、x が小さいときと大きいときで、x の効果は異なる。
2.2 典型的な解釈
\beta_2 < 0 なら、上に凸ではなく逆U字型 になる\beta_2 > 0 なら、U字型 になる
たとえば、
などでは、最初は増加するが、どこかで伸びが鈍る、あるいは逆に下がる、という関係を考えたくなることがある。 そのようなときに二次項が役に立つ。
2.3 頂点の解釈
二次関数の頂点は
x^\ast = -\frac{\beta_1}{2\beta_2}
で与えられる。 これにより、「どの水準で最大になるか」「どこを境に増加から減少に変わるか」を計算できる。
3. 交差項
重回帰の大きな強みの一つは、ある変数の効果が別の変数に依存する ことを表現できる点である。 そのために使うのが交差項である。
たとえば
y_i = \beta_0 + \beta_1 x_i + \beta_2 z_i + \beta_3 (x_i z_i) + u_i
を考える。
ここで x_i z_i が交差項である。
3.1 交差項の意味
このモデルでは、x の効果は
\frac{\partial y_i}{\partial x_i} = \beta_1 + \beta_3 z_i
となる。
つまり、x の効果は z の値によって変わる。 逆に、z の効果も x の値によって変わる。
3.2 ダミー変数との交差項
特によく使うのは、ダミー変数(後述するが、0か1の値を取る変数)との交差項である。
たとえば d_i を男女ダミーとして
y_i = \beta_0 + \beta_1 x_i + \beta_2 d_i + \beta_3 (x_i d_i) + u_i
を考える。
このとき
d_i = 0 のグループでは傾きは \beta_1 d_i = 1 のグループでは傾きは \beta_1 + \beta_3
になる。
つまり、2つのグループで傾きが異なる ことを表現している。
3.3 切片も傾きも違う
上の式では
\beta_2 が切片の差\beta_3 が傾きの差
を表している。
したがって、交差項を使うと「平均的に違う」だけでなく、「説明変数への反応の仕方が違う」という異質性まで捉えることができる。
4. 多項式近似
二次関数は曲線を表現する最も簡単な方法だが、それでも十分でないこともある。 そのようなときは、三次項、四次項などを追加して、より柔軟な形を作ることができる。
たとえば
y_i = \beta_0 + \beta_1 x_i + \beta_2 x_i^2 + \beta_3 x_i^3 + u_i
のようなモデルである。
より一般には
y_i = \beta_0 + \beta_1 x_i + \beta_2 x_i^2 + \cdots + \beta_K x_i^K + u_i
という形を考える。 これを多項式近似という。
4.1 多項式近似の発想
「本当の関係の形はよくわからないが、直線ではなさそうだ」というとき、多項式を使うとかなり柔軟に曲線を近似できる。
実際、滑らかな関数の多くは、ある範囲では多項式でかなりよく近似できる。
4.2 注意点
ただし、次数を高くしすぎると問題もある。
サンプル内で不自然にうねうねした形になる
端の方で急激に曲がる
係数の解釈が難しくなる
多重共線性が強くなりやすい
したがって、柔軟性が上がる一方で、解釈や安定性は下がる 。 実際の分析では、図を見ながら二次や三次くらいまでに抑えることも多い。
5. ダミー変数
ダミー変数とは、ある属性を0と1で表した変数である。 たとえば
女性なら1、男性なら0
都市部なら1、地方なら0
政策実施後なら1、実施前なら0
といった変数である。
5.1 ダミー変数の係数の意味
モデル
y_i = \beta_0 + \beta_1 d_i + u_i
を考える。
ここで d_i がダミー変数なら、
d_i = 0 のときの平均は \beta_0 d_i = 1 のときの平均は \beta_0 + \beta_1
となる。
したがって、\beta_1 は2つのグループの平均の差 を表す。
5.2 他の変数をコントロールした上での差
重回帰の中でダミー変数を使うと、その係数は
他の変数を一定にした上での平均的な差
として解釈できる。
たとえば
y_i = \beta_0 + \beta_1 \text{educ}_i + \beta_2 \text{female}_i + u_i
なら、\beta_2 は教育年数を一定にした上での男女差を表す。
6. カテゴリー変数
現実には、属性が2種類ではなく、3種類以上あることも多い。 たとえば
学年:1年、2年、3年、4年
地域:東京、大阪、福岡、その他
学部:経済、法、工、文
のような変数である。 このような変数をカテゴリー変数という。
6.1 カテゴリー変数はダミーに分解する
カテゴリーが G 個あるときは、通常 G-1 個のダミー変数を作って回帰に入れる。
たとえば学部が
の3種類なら、
の2つを入れて、「経済」を基準カテゴリにする。
するとモデルは
y_i = \beta_0 + \beta_1 D_{i,\text{law}} + \beta_2 D_{i,\text{engineering}} + u_i
のようになる。
このとき
\beta_0 は基準カテゴリ(経済)の平均\beta_1 は法と経済の差\beta_2 は工と経済の差
を表す。
6.2 なぜ全部入れてはいけないのか
3種類のカテゴリについて3つすべてのダミーを入れると、必ず
D_{i,\text{econ}} + D_{i,\text{law}} + D_{i,\text{engineering}} = 1
が成り立つ。 さらに定数項も入っていると、完全な線形関係が生じてしまう。
そのため、1つは基準カテゴリとして落とす 必要がある。 これを忘れると、いわゆる dummy variable trap に陥る。
6.3 基準カテゴリの選び方
基準カテゴリはどれを選んでもよい。 ただし、解釈しやすいグループを基準にすると便利である。
たとえば
政策前を基準にする
男性を基準にする
首都圏以外を基準にする
などである。
基準を変えると係数の見え方は変わるが、モデルが表している内容そのものは変わらない。
7. 個別の定数項を入れる:固定効果モデル
ここまで見てきたダミー変数の考え方を極端に押し進めると、観測単位ごとに定数項を持たせる という発想にたどり着く。 これが固定効果モデルである。
たとえば個人 i を時点 t で観測したパネルデータで
y_{it} = \alpha_i + \beta x_{it} + u_{it}
というモデルを考える。
ここで \alpha_i は個人ごとの定数項であり、固定効果と呼ばれる。
7.1 固定効果の意味
\alpha_i は、その個人に固有で、時間を通じて変わらない要因を表している。
たとえば個人データなら
のような、観測しにくいがその人に固有の特徴が入っていると考えられる。
企業データなら
学校データなら
などが含まれるかもしれない。
7.2 固定効果モデルで何ができるか
固定効果モデルの重要な点は、こうした時間を通じて変わらない観測されない要因 を吸収できることである。
その結果、\beta は
同じ個人の中で x が変化したときに y がどう変わるか
に近い情報から識別される。
つまり、比較の軸が「人と人の比較」から「同じ人の中での変化の比較」に移る。
7.3 ダミー変数として見る固定効果
固定効果モデルは、実際には「個人ダミーを全部入れた回帰」と考えることができる。
たとえば個人が100人いれば、99個の個人ダミーを入れるのと同じ発想である。 したがって、固定効果モデルはダミー変数の延長線上にある。
7.4 年固定効果
個人固定効果と並んでよく使うのが年固定効果である。
y_{it} = \alpha_i + \lambda_t + \beta x_{it} + u_{it}
ここで \lambda_t は各年に共通するショックを吸収する。 たとえば景気、制度変更、物価、全国的なトレンドなどである。
このモデルでは、
\alpha_i が個人固有の不変要因\lambda_t が時点共通の要因
を吸収する。
7.5 固定効果モデルの限界
固定効果モデルは強力だが万能ではない。
吸収できるのは、時間を通じて変わらない要因 だけである。 時間とともに変わる観測されない要因が x_{it} と相関していれば、なおバイアスは残りうる。
また、時間を通じて変わらない変数は、個人固定効果と完全に重なってしまうため、その係数は識別できない。
たとえば個人固定効果を入れたモデルでは、性別のように各個人について不変な変数の係数は推定できない。
8. まとめ
このセクションで見たように、重回帰を使うと
対数を通じて割合の関係を扱える
二次項や多項式で曲線的な関係を表現できる
交差項で効果の異質性を表現できる
ダミー変数やカテゴリー変数でグループ間の差を扱える
固定効果モデルで観測されない不変要因を吸収できる
ようになる。
実際の実証分析では、これらを単独で使うだけでなく、組み合わせて使うことが多い。 たとえば
対数賃金を被説明変数にし
教育年数とその二乗を入れ
性別ダミーとの交差項を入れ
個人固定効果と年固定効果を加える
といった形である。
したがって、重回帰を学ぶときには「式を機械的に推定する」のではなく、 どのような関係を表現したいのかに応じて、どの変数をどう入れるべきかを考えること が大切である。
カットオフがある変数と回帰分析
ここまで見てきた重回帰は、基本的には「観測された Y と X の条件付き平均を、線形の式で近似する」道具である。 しかし実証分析では、そもそも観測される変数が制度やデータ作成の都合でカットオフを持っていることがある。
たとえば次のようなケースである。
所得が一定額以上だと「1,000万円以上」としか記録されない
テスト点が 0 点未満や 100 点超にはならない
医療費や労働時間のように、0 に値がたまる
賃金データが、働いている人についてしか観測されない
資産額や寄付額が、一定額以上の人だけデータに入っている
説明変数である所得や資産が top-code されている
こういう状況では、単に
Y_i = \beta_0 + \beta_1 X_i + u_i
を OLS で推定すればよい、とは限らない。 問題は、OLS の計算ができないことではない。 OLS の計算はできる。 しかし、計算された係数が、もともと知りたかったパラメータと一致しない ことがある。
ここでは、まだ最尤法を学んでいないので、Tobit や Heckit のようなモデルを本格的に導入することはしない。 その代わり、OLS だけを使って、どこまでなら言えるのか、どこから先はまだ言えないのかを整理する。
Censoring と truncation の違い
まず言葉を分けておく。
Censoring とは、真の値はカットオフを超えているかもしれないが、観測値としてはカットオフの値にまとめられる状況である。 たとえば本当の所得が 1,200 万円でも 2,000 万円でも、データ上は「1,000万円以上」としか記録されない場合である。 下限で censor される場合もある。 たとえば、潜在的には負の値をとりうる需要や希望労働時間が、観測上は 0 で止まるような場合である。
Truncation とは、カットオフの外側にある観測単位が、データそのものに入ってこない状況である。 たとえば、賃金が働いている人についてしか観測されない場合、働いていない人の潜在賃金はデータから落ちている。 あるいは、一定額以上の寄付をした人だけが寄付者データに入っている場合、少額寄付者や非寄付者は観測されない。
違いを短く言えば、
censoring: 個体はデータにいるが、値がカットオフにまとめられる
truncation: カットオフの外側の個体が、そもそもデータにいない
である。
この違いは重要である。 censoring では「カットオフに値がたまる」。 truncation では「誰がデータに入るか」自体が変わる。
従属変数が censor されているケース
まず、従属変数 Y に下限 0 がある場合を考える。 背後には、潜在的な変数 Y_i^\ast があり、
Y_i^\ast = \beta_0 + \beta_1 X_i + u_i
という関係があるとする。 しかし実際に観測されるのは
Y_i =
\begin{cases}
Y_i^\ast & \text{if } Y_i^\ast > 0 \\
0 & \text{if } Y_i^\ast \le 0
\end{cases}
である。 たとえば Y_i^\ast を「潜在的な支出意欲」、Y_i を「実際の支出額」と考えると、支出額は 0 未満にならない。
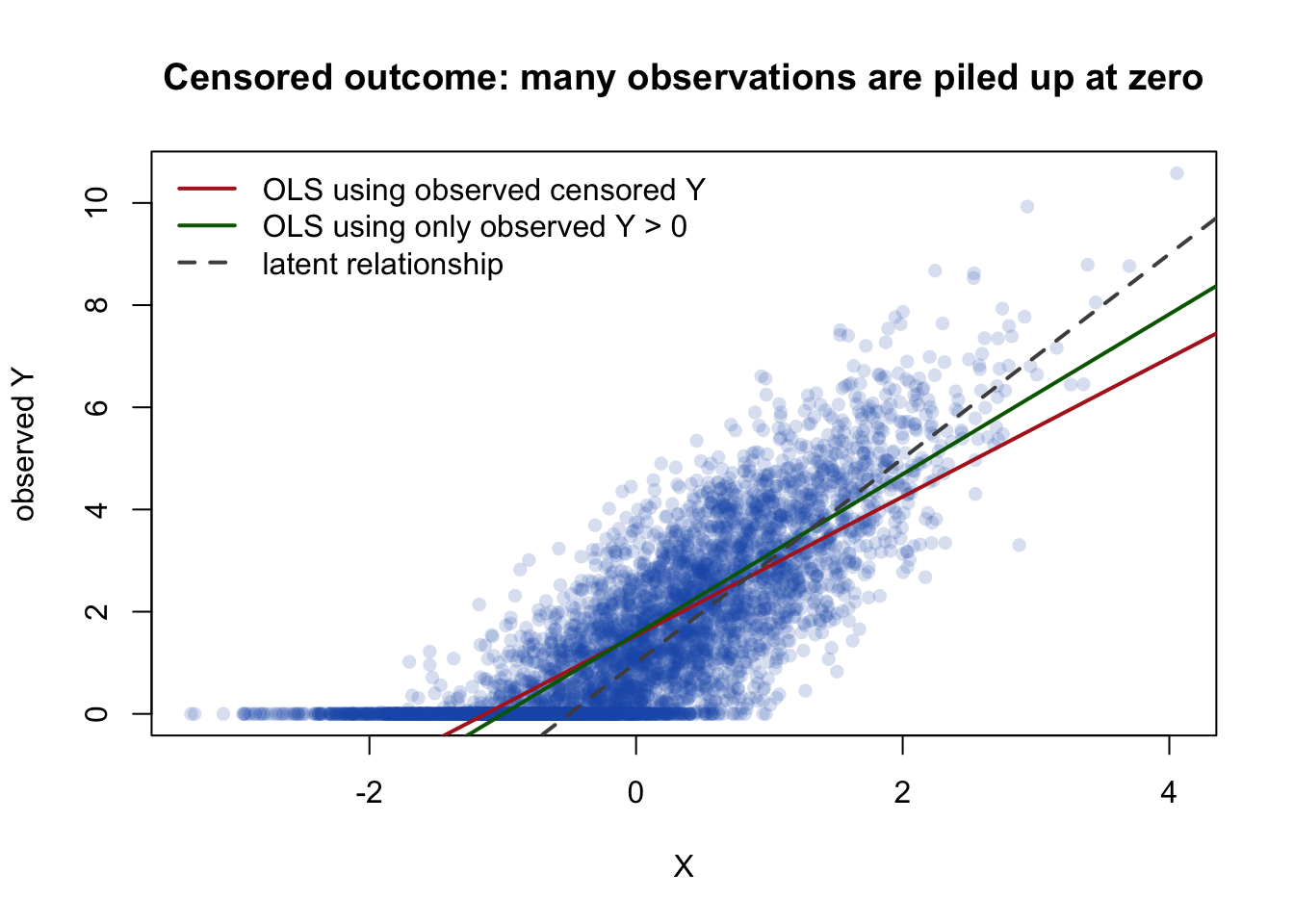
このとき、観測された Y_i をそのまま OLS にかけると何が起きるだろうか。 直感的には、Y_i^\ast \le 0 の人たちが全員 0 に押し込められるので、Y と X の関係は直線ではなくなる。 とくに X が小さいところでは 0 に張りつく人が多く、X が大きいところでは張りつく人が少ない。 したがって、観測された Y の条件付き平均 E[Y_i \mid X_i] は、潜在変数 Y_i^\ast の条件付き平均とは違う形になる。
シミュレーションで見てみよう。
set.seed (606 )<- 5000 <- rnorm (n)<- rnorm (n, sd = 1.2 )<- 1 + 2 * x + u<- pmax (0 , y_star)<- as.integer (y_star > 0 )<- s_observed == 1 <- data.frame (model = c ("latent Y* on X" ,"censored Y on X" ,"censored Y on X, only S = 1" slope = c (coef (lm (y_star ~ x))[2 ],coef (lm (y_cens ~ x))[2 ],coef (lm (y_cens ~ x, subset = observed_positive))[2 ]$ slope <- round (coef_table$ slope, 3 ):: kable (coef_table)
latent Y* on X
2.029
censored Y on X
1.359
censored Y on X, only S = 1
1.566
本当の潜在モデルでは、X の係数は 2 である。 ところが、0 で censor された Y をそのまま OLS で回帰すると、係数は 2 からずれる。 これはサンプルサイズが小さいからではなく、観測された Y の平均構造そのものが変わっているからである。
図で見るとよりわかりやすい。
plot (pch = 16 , col = rgb (0.1 , 0.35 , 0.7 , 0.18 ),xlab = "X" ,ylab = "observed Y" ,main = "Censored outcome: many observations are piled up at zero" abline (lm (y_cens ~ x), col = "firebrick" , lwd = 2 )abline (lm (y_cens ~ x, subset = observed_positive), col = "darkgreen" , lwd = 2 )abline (1 , 2 , col = "gray30" , lwd = 2 , lty = 2 )legend ("topleft" ,legend = c ("OLS using observed censored Y" , "OLS using only observed Y > 0" , "latent relationship" ),col = c ("firebrick" , "darkgreen" , "gray30" ),lwd = 2 ,lty = c (1 , 1 , 2 ),bty = "n"
ここで大事なのは、censor された Y に OLS をしてはいけない、と機械的に覚えることではない。 OLS が推定しているものを正しく読む必要がある。
もし知りたいものが、
観測された支出額 Y が、X と平均的にどう関係しているか
であれば、OLS は記述的な線形近似として意味を持つ。 ただし、その係数は
潜在的な支出意欲 Y^\ast に対する X の効果
ではない。
この区別が重要である。
従属変数が truncation されているケース
次に、Y_i^\ast > 0 の人だけがデータに入る場合を考える。 これは censoring よりもさらに厄介である。
ここで、個体 i がデータに観測されるかどうかを表すダミー変数を
S_i =
\begin{cases}
1 & \text{if } Y_i^\ast > 0 \\
0 & \text{if } Y_i^\ast \le 0
\end{cases}
と書くことにする。 S_i = 1 ならデータに入る。 S_i = 0 ならデータに入らない。
つまり、観測されるサンプルは
S_i = 1
を満たす人だけである。 しかし、S_i=1 という条件は、もともとの潜在モデル
Y_i^\ast = \beta_0 + \beta_1 X_i + u_i
を使うと、
u_i > -\beta_0 - \beta_1 X_i
という条件である。 つまり、サンプルに入るかどうかを表す S_i は、誤差項 u_i と説明変数 X_i の両方に依存している。
この条件付きサンプルで OLS をきれいに解釈するには、
E[u_i \mid X_i, S_i = 1] = 0
が必要である。 しかし、もともとの母集団で E[u_i \mid X_i] = 0 が成り立っていたとしても、この条件は自動的には成り立たない。 Lecture 5 で見たように、OLS のきれいな解釈には「説明変数と誤差項が系統的に関係していない」ことが必要だった。 truncation は、この条件をサンプル選択を通じて壊してしまう。
なぜ壊れるのかをもう少し具体的に見る。 S_i=1 は
u_i > -\beta_0 - \beta_1 X_i
を意味するので、S_i=1 の中では誤差項 u_i の分布が下から切られている。 しかも、その切られる位置は X_i によって変わる。 X_i が小さい人は、かなり大きな正の誤差を持っていないと S_i=1 になれない。 逆に X_i が大きい人は、多少小さい誤差でも S_i=1 になれる。
したがって、S_i=1 で条件づけると、誤差項の平均が X_i と一緒に動く。 これが
E[u_i \mid X_i] = 0
だった世界から、
E[u_i \mid X_i, S_i = 1] \neq 0
の世界に変わる、ということである。
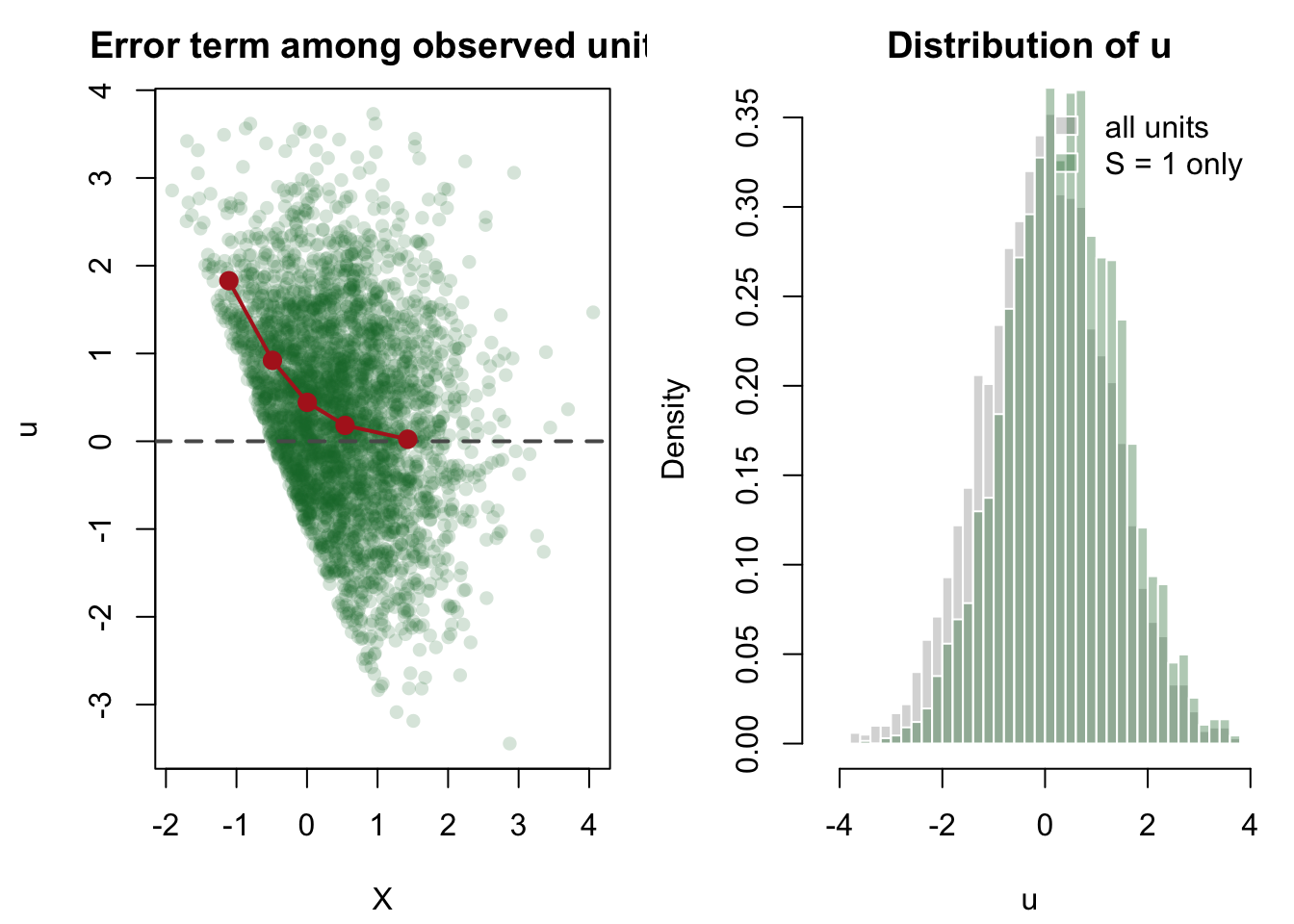
シミュレーションで、実際に条件付き誤差の分布を見てみよう。
<- cut (breaks = quantile (x, probs = seq (0 , 1 , 0.2 )),include.lowest = TRUE <- data.frame (x_bin = levels (x_bin),mean_u_all = as.numeric (tapply (u, x_bin, mean)),mean_u_given_s1 = as.numeric (tapply (u[s_observed == 1 ], x_bin[s_observed == 1 ], mean)),share_s1 = as.numeric (tapply (s_observed, x_bin, mean))$ mean_u_all <- round (selection_table$ mean_u_all, 3 )$ mean_u_given_s1 <- round (selection_table$ mean_u_given_s1, 3 )$ share_s1 <- round (selection_table$ share_s1, 3 ):: kable (selection_table)
[-3.34,-0.86]
-0.051
1.829
0.102
(-0.86,-0.249]
0.004
0.922
0.464
(-0.249,0.262]
0.023
0.443
0.791
(0.262,0.853]
0.065
0.181
0.957
(0.853,4.06]
0.017
0.023
0.998
全体では、どの X の範囲でも誤差項の平均はだいたい 0 に近い。 これは、データを作るときに u_i を X_i と独立に発生させたからである。 しかし S_i=1 の人だけを見ると、誤差項の平均は 0 ではなく、しかも X の範囲によって変わる。
図にすると、何が起きているかがさらに見やすい。
<- par (mfrow = c (1 , 2 ), mar = c (4.2 , 4.2 , 2.4 , 1 ))plot (pch = 16 , col = rgb (0.1 , 0.45 , 0.2 , 0.18 ),xlab = "X" ,ylab = "u" ,main = "Error term among observed units" abline (h = 0 , col = "gray35" , lwd = 2 , lty = 2 )points (tapply (x[observed_positive], x_bin[observed_positive], mean),tapply (u[observed_positive], x_bin[observed_positive], mean),pch = 16 , col = "firebrick" , cex = 1.4 lines (tapply (x[observed_positive], x_bin[observed_positive], mean),tapply (u[observed_positive], x_bin[observed_positive], mean),col = "firebrick" , lwd = 2 hist (breaks = 35 , freq = FALSE ,col = rgb (0.35 , 0.35 , 0.35 , 0.25 ),border = "white" ,xlab = "u" ,main = "Distribution of u" hist (breaks = 35 , freq = FALSE ,col = rgb (0.1 , 0.45 , 0.2 , 0.35 ),border = "white" ,add = TRUE legend ("topright" ,legend = c ("all units" , "S = 1 only" ),fill = c (rgb (0.35 , 0.35 , 0.35 , 0.25 ), rgb (0.1 , 0.45 , 0.2 , 0.35 )),border = "white" ,bty = "n"
左の図では、S_i=1 の人だけを見ると、誤差項 u_i の平均が X_i によって変わっていることがわかる。 赤い点は X の範囲ごとの平均であり、0 の水平線から系統的にずれている。 右の図では、S_i=1 に限ると誤差項の分布そのものが、全体の分布からずれていることがわかる。
上のシミュレーションでも、観測された Y_i > 0 の人だけを残して OLS をすると、潜在モデルの係数 2 からずれていた。 これは「観測される人だけを見る」ことで、E[u_i \mid X_i, S_i=1]=0 が崩れてしまうためである。
典型例は賃金である。 賃金は働いている人についてしか観測されない。 しかし働くかどうかは、潜在賃金、家庭状況、健康、選好などに依存する。 したがって、働いている人だけで賃金回帰をすると、それは「全員に対する潜在賃金の関係」ではなく、「働いている人という選ばれたサンプルの中での関係」になる。
説明変数にカットオフがあるケース
カットオフは従属変数だけでなく、説明変数にも現れる。 たとえば所得や資産が top-code されているのに、それを説明変数として使う場合である。 あるいは、テスト点や信用スコアのように、説明変数が上限・下限を持つこともある。
ここでも問題は同じで、観測された X が、本当に回帰式に入れたい X^\ast と一致しているかである。
たとえば本当は
Y_i = \beta_0 + \beta_1 X_i^\ast + u_i
なのに、観測されるのが
X_i = \max(0, X_i^\ast)
だとする。 このとき X_i^\ast < 0 の人は、全員 X_i = 0 と記録される。 観測された X_i をそのまま使うと、真の説明変数に測定誤差が入った回帰になる。 しかもこの測定誤差は、普通の「ランダムなノイズ」ではなく、カットオフによって生じる非線形な誤差である。
set.seed (607 )<- 5000 <- rnorm (n)<- rnorm (n)<- 1 + 2 * x_star + u<- pmax (0 , x_star)<- x_star > 0 <- data.frame (model = c ("Y on true X*" ,"Y on censored X" ,"truncated X sample: Y on X*, only X* > 0" slope = c (coef (lm (y ~ x_star))[2 ],coef (lm (y ~ x_cens))[2 ],coef (lm (y ~ x_star, subset = keep_x_positive))[2 ]$ slope <- round (x_table$ slope, 3 ):: kable (x_table)
Y on true X*
1.996
Y on censored X
2.951
truncated X sample: Y on X, only X > 0
2.009
この例では、真の X^\ast を使えば係数は 2 に近い。 しかし censor された X をそのまま説明変数に使うと、係数は大きく変わる。 これは、X^\ast < 0 の細かい違いがすべて 0 に潰れてしまい、X の分布と Y との関係が変形されるからである。
一方で、説明変数についての truncation は少し注意が必要である。 もし「X^\ast > 0 の人だけを観測している」が、その範囲では真の X^\ast が正確に観測され、かつ
E[u_i \mid X_i^\ast] = 0
がその範囲でも成り立つなら、X^\ast > 0 のサンプル内での傾きは推定できる。 つまり、説明変数でサンプルを切ることそれ自体が、常に OLS のバイアスを生むわけではない。
ただし、このとき推定しているのは、
X^\ast > 0 の人たちの範囲での関係
である。 全体集団にそのまま外挿できるとは限らない。 また、サンプルに入る条件が実は X だけでなく u や Y にも依存しているなら、やはり selection の問題が出てくる。
OLS だけでここまではできる
ここまでの話を整理すると、OLS だけでもできることはある。
第一に、カットオフがあることを図や記述統計で確認できる。 ヒストグラムや散布図を描いて、0 や上限値に観測値が不自然にたまっていないかを見ることは重要である。
第二に、観測された変数そのものについての線形近似はできる。 たとえば「実際に観測された支出額」や「実際に観測された労働時間」が X とどう関係しているかを記述することはできる。
第三に、サンプルを限定した分析であることを明示すれば、そのサンプル内での関係を推定することはできる。 たとえば「就業者に限った賃金回帰」や「正の支出をした人に限った支出額回帰」は、対象をはっきり限定すれば記述的には意味を持つ。
ただし、ここで注意したいのは、これらは基本的に
観測されたデータ上での関係を記述している
ということである。
潜在変数 Y^\ast の係数や、サンプル選択がなかった世界での関係を推定しているとは限らない。
ここから先はまだできない
本当は、従属変数が censor されているときには Tobit モデル、サンプル選択があるときには Heckit などの考え方が出てくる。 これらは、単に OLS に変数を足す話ではない。 観測される確率や、カットオフに値がたまる確率を含めて、データが生成される仕組みをモデル化する必要がある。
そのためには、最尤法や分布の仮定を使う。 この lecture の時点では、まだそこまでの道具を導入していない。
したがって、ここでの到達点は次のようにまとめられる。
カットオフがある変数では、OLS の係数が何を表しているかを慎重に読む必要がある
censoring と truncation は違う問題である
観測された変数の線形近似としての OLS はできる
しかし、潜在変数の構造パラメータや選択のない世界のパラメータを推定するには、追加のモデルと推定法が必要である
この区別は、次に見る論文紹介にもつながる。 重回帰は非常に便利だが、便利だからこそ、「何を観測していて、何が観測されていないのか」を常に意識する必要がある。
ここからは、前半で見た ダミー変数・交差項・固定効果 が実際の論文の中でどう使われるのかを見る。式の形そのものよりも、「どの比較をしているのか」を意識しながら読むのがポイントである。